Google Cloud 上で 100 兆桁の円周率を計算

Emma Haruka Iwao
Developer Advocate
※この投稿は米国時間 2022 年 6 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
記録は破るためにあります。2019 年、Google は 31 兆 4000 億桁の円周率を計算し、当時の世界記録を樹立しました。そして 2021 年には グラウビュンデン応用科学大学 の科学者が、さらに 31 兆 4000 億桁上回る計 62 兆 8000 億桁を計算しました。そして本日、Google は100 兆桁の円周率を計算し、世界記録を更新したことを発表します。
Google Cloud を使って円周率の桁数の世界記録を更新1するのは今回で 2 度目で、わずか 3 年で桁数を 3 倍に伸ばしました。
この新記録は、 Google Cloud のインフラストラクチャが年々高速化していることの証とも言えます。記録達成の背景には、 Google Cloud の安全でカスタマイズ可能なコンピューティングサービス Compute Engine と、近年追加および改善された Compute Engine N2 マシンファミリー、 100 Gbps の外向き帯域幅、Google Virtual NIC、そしてバランス永続ディスクといった機能があります。
技術的な詳細に移る前に、今回の 100 兆桁の計算ジョブの概要をご紹介します。
プログラム: y-cruncher v0.7.8、作者 Alexander J. Yee
アルゴリズム: Chudnovsky のアルゴリズム
計算ノード: n2-highmem-128 (128 vCPU と 864 GB メモリ)
開始日時: 2021 年 10 月 14 日(木) 04:45:44 UTC
終了日時: 2022 年 3 月 21 日(月) 04:16:52 UTC
合計経過時間: 157 日 23 時間 31 分 7.651 秒
合計ストレージサイズ: 663 TB 使用可能、 515 TB 使用
合計 I/O: 読み込み 43.5 PB、書き込み 38.5 PB、 合計 82 PB
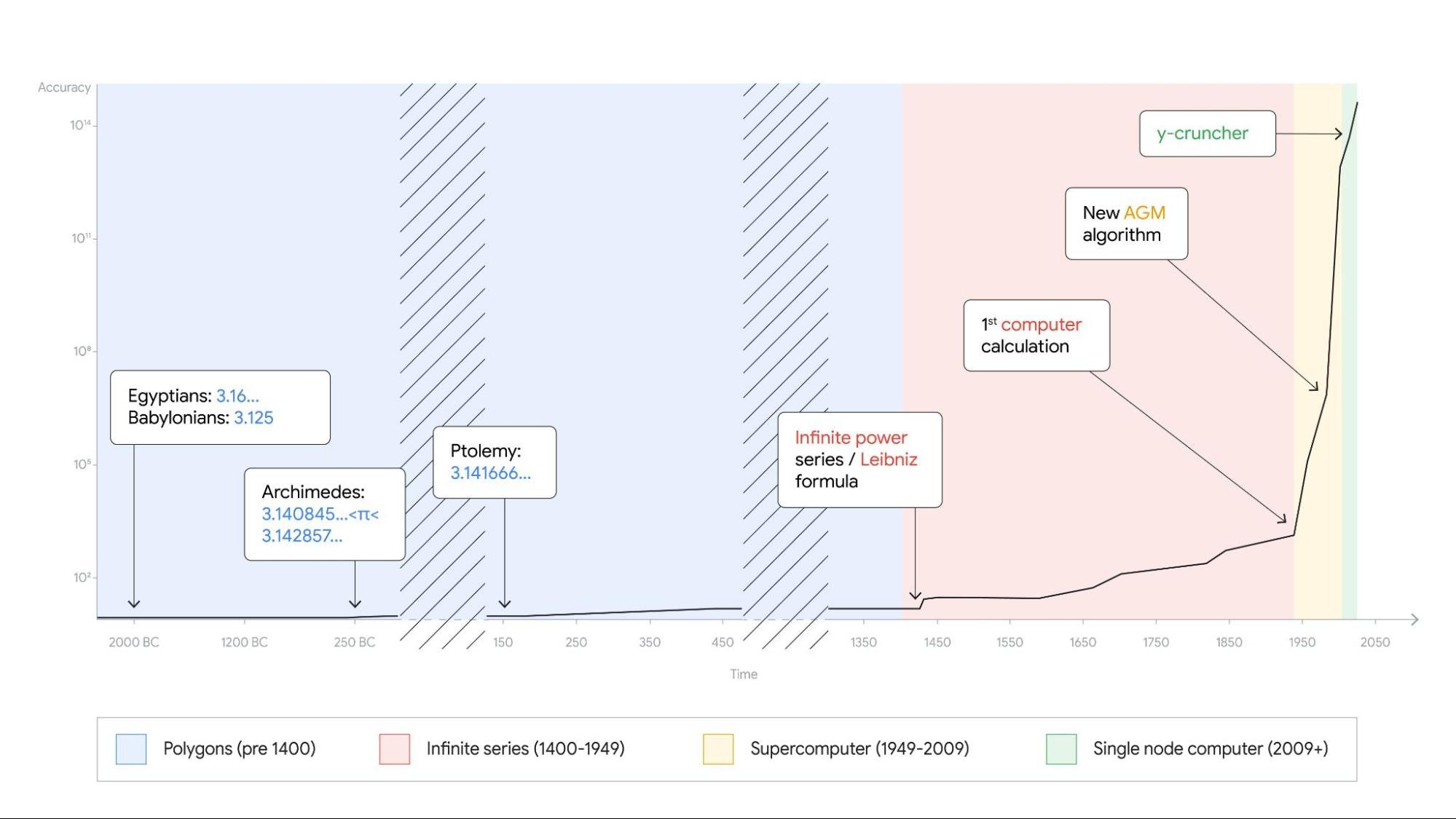
この画像は、古代から現代までの円周率計算の歴史を示しています。コンピュータの性能向上により、円周率の桁数が指数関数的に増加していることがわかります。
アーキテクチャの概要
円周率の計算には高い CPU、ストレージ、ネットワーク性能が必要です。そこで、Google は、今回の挑戦のために以下のような Compute Engine の環境を構築しました。
まずストレージに関して、一時ストレージの必要容量をおよそ 554 TB と見積もりました。単一の仮想マシンに接続できる永続ディスクの最大容量は 257 TB で、従来のシングル ノード アプリケーションには十分ですが、今回はさらに大きな容量が必要でした。そこで1 台の計算ノードと、合計 64 個の iSCSI ターゲットを提供する 32 台のストレージノードからなるクラスタを設計しました。
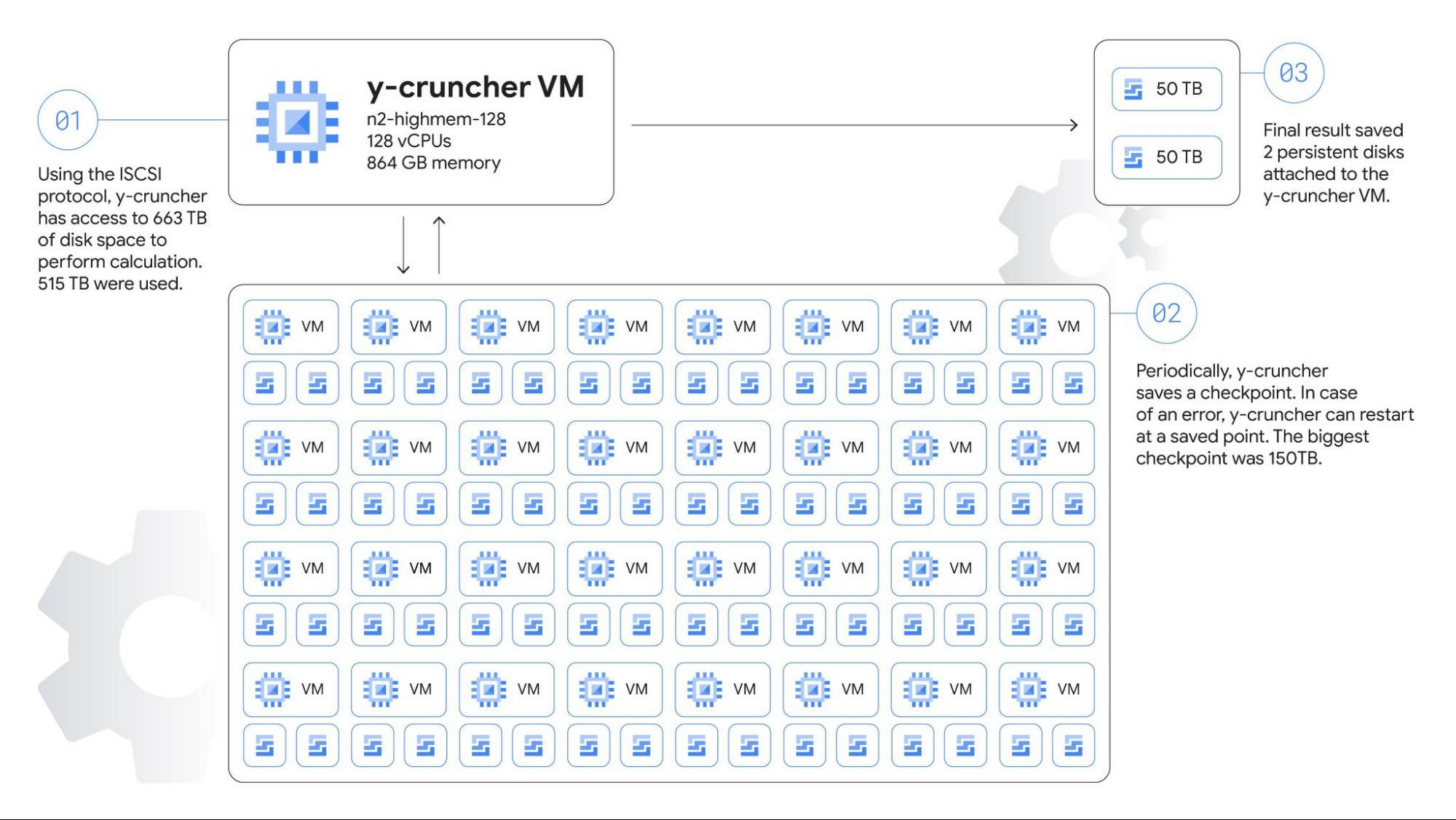
主となる計算ノードには 128 vCPU、864 GB のメモリを持ち、100 Gbps 外向き帯域幅をサポートする n2-highmem-128 インスタンスを採用し、OS には Debian Linux 11 を用いました。ネットワークベースの共有ストレージアーキテクチャを採用したため、100 Gbps の帯域幅はこのシステムの重要な要件でした。
各ストレージサーバーは n2-highcpu-16 インスタンスで、2 台の 10,359 GB のゾーンバランス永続ディスクを接続しました。N2 マシンシリーズは価格とパフォーマンスのバランスに優れ、16 vCPU を割り当てると 32 Gbps のネットワーク帯域を持ち、最新の Intel Ice Lake CPU プラットフォームを使用可能なため、高性能なストレージサーバーに適した選択肢と言えます。
構築を自動化
クラスタのセットアップと管理には、 Terraform を使用しました。さらに、いくつかのシェルスクリプトを開発し、古いスナップショットの削除や、スナップショットからの再開など、極めて重要な作業を自動化しました(実際にはこの機能は使用しませんでした)。Terraform スクリプトでは、必要なソフトウェアパッケージを自動的にインストールするための OSポリシーも作成しました。ゲストOSセットアップの一部は、起動スクリプトによって実行されます。このように、クラスタ全体を数個のコマンドで再構築できるようにしました。
この計算には数ヶ月の時間が必要で、わずかなの性能差でも実行時間が数日、数週間変わってしまうことが予想されました。また、複数の設定項目がオペレーティングシステム、インフラストラクチャ、実行するアプリケーションそのものに存在し、様々な組み合わせが考えられました。Terraform を使用することで、インフラストラクチャの異なる数十といった組み合わせを短時間でテストすることが可能になりました。さらに、y-cruncher を異なる設定で実行して性能測定を自動化する、小さなスクリプトも開発しました。これらの最適化により、最終的な実行速度は最初の設計に比べ約 2 倍高速化されました。言い換えると、最適化できなければこの計算プロジェクトは 157 日ではなく 300 日ほどかかってた可能性があるということです。
実際 100 兆桁の計算に使用したスクリプトは GitHubで公開していますので、ご覧ください。
適切なマシンタイプを選択
Compute Engine は高い CPU や I/O 負荷に対応したマシンタイプも提供しています。利用可能なメモリ容量とネットワーク帯域幅が最も重要な要件だったため、n2-highmem-128 (Intel Xeon、128 vCPU、864 GB メモリ)を選択しました。このマシンタイプは、高い CPU 性能、大容量メモリ、100 Gbps ネットワーク帯域幅といった必要な要件を満たしていました。この N2 マシンシリーズは、Google Cloud で最もよく利用される汎用マシンファミリーの 1 つです。
100 Gbps ネットワーク
n2-highmem-128 マシンタイプが 100 Gbps 外向きネットワーク帯域幅をサポートしていたことも、重要なポイントでした。2019 年に 31 兆 4000 億桁の円周率計算を行った際、外向きネットワーク帯域幅は、わずか 16 Gbps でしたので、わずか 3 年間で帯域幅が約 6 倍に増加したことになります。この高速化がこの 100 兆桁計算を可能にしました。今回、ネットワークストレージに対し読み書きしたデータ量の合計は 82.0 PB で、2019 年の 19.1 PB から大きく増加しました。
また、ネットワークドライバーを virtio から、新しい Google Virtual NIC (gVNIC) に変更しました。gVNIC はグーグルの Andromeda 仮想ネットワークスタックと密に結合する新しいデバイスドライバーで、より高い帯域幅と低いレイテンシーを実現します。また、100 Gbps のネットワーク帯域幅の使用にも必要な要件です。
ストレージ設計
ストレージ設計は、今回のクラスタ全体を見ても非常に重要な要素であったため、容量、性能、信頼性、コストといった様々な要素を考慮する必要がありました。また、データ全体がメインメモリに収まらず、ストレージシステムの性能がプログラム実行のボトルネックとなっていました。ペタバイト単位のデータを損失や破損なく扱える、安定、高耐久かつ、100 Gbps の帯域幅をフルに活用できるストレージシステムが必要だったのです。
永続ディスク (PD) は Compute Engine の仮想マシンで使用できる、冗長性のある高性能なストレージです。今回の計算には、新しく追加されたバランス PD を採用しました。バランス PD は、1,200 MB/s の読み書きスループットと最大 8 万 IOPS を提供し、高いスループットと中程度の IOPS が必要な y-cruncher の特性に最適でした。
Terraform を用い、ストレージノード数、ノードあたりの iSCSI ターゲット数、マシンタイプ、ディスクサイズといった異なるパラメーターの組み合わせをテストしました。テストの結果、32 ノード、計 64 ディスクの構成が今回のワークロードに対して最も良い性能を示すであることも推測できました。
シェルスクリプトを用いて、 2 日ごとのバックアップ取得を自動化しました。このスクリプトは、最後のスナップショットからの時間を確認し、fstrim コマンドを実行して未使用のブロックをトリミングし、gcloud compute disks snapshot コマンドを実行して PD スナップショットを作成します。実際のスナップショットのデータコピーは Compute Engine のインフラストラクチャが非同期にバックグラウンドで実行します。 gcloud コマンドは数秒で完了し、y-cruncher はすぐに計算を再開することができ、バックアップにかかる中断時間を最小化することができました。
最終結果を保存するために、計算ノードに 2 台の 50 TB のディスクを直接接続しました。このディスクは計算の最終段階まで使用されないので、y-cruncher が結果を出力する直前まではディスクサイズを完全には割り当てませんでした。これにより、約 4 ヶ月分にあたる間 100 TB のストレージコストを削減することができました。
結果
以上のような性能測定と最適化の結果、100 兆桁の円周率の計算が無事に完了しました。ちょうど 100 兆桁目は 0 でした。計算が終了してから、最終結果を Bailey–Borwein–Plouffe の公式 (BBP の公式) という別のアルゴリズムを用いて検証しました。この検証が、円周率計算全体で最も怖い瞬間です。計算に 5 ヶ月を費やしても、最終結果を確認するまでは、途中経過が正しいのか確実に確かめる方法が無いからです。幸い、BBP の公式と今回の結果が一致し、計算が正しいことが確認されました。以下が小数点以下 100 兆桁目までの 100 桁です。
全桁の結果は、こちらのデモサイトでご覧いただけます。
今回の実験をふまえて
今回の大規模計算は、 Google Cloud の柔軟なインフラストラクチャを用いた大規模科学技術計算の一例で、こうした取り組みは世界中で行われています。また、計算プログラムを実行する 5 ヶ月の間、仮想マシンの不具合は無く、82 PB のデータを1ビットの誤りもなく正しく読み書きすることができたため、今回の結果は Google Cloud の信頼性の高さも示しています。過去 3 年間、Google Cloud が積み重ねてきたインフラストラクチャや製品の改良が、今回のプロジェクトを可能にしました。
今回の円周率計算からは学ぶことが多く、非常に楽しいプロジェクトでした。このブログ記事が、 Google Cloud のスケーラブルなコンピューティング、ネットワーク、ストレージのインフラストラクチャを、みなさま自身のハイ パフォーマンス コンピューティング領域の課題に役立てるヒントになれば幸いです。また Compute Engine を使う第一歩として、Compute Engine 上に仮想マシンを作成し、円周率計算のプログラムを実行する過程をステップごとに細かく解説した codelab を公開しました。最後に、円周率計算の歴史と意義について The Keyword の この記事に詳しく書きましたので、そちらもぜひ合わせてご覧ください。
1編注: 現在、この達成を「世界記録」として正式認定するためにギネスワールドレコーズと確認を進めています。この記録は y-cruncherの作者 Alexander J. Yee により審査・検証されています。
- Developer Advocate, Emma Haruka Iwao


