新しい Compute Engine A2 VM - クラウド初の NVIDIA Ampere A100 GPU
Google Cloud Japan Team
※この投稿は米国時間 2020 年 7 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習と HPC アプリケーションの処理パフォーマンスを手頃な価格で劇的に向上できるサービスはこれまでありませんでした。このたび、Google Compute Engine 向けにアクセラレータが最適化された VM(A2)ファミリーをご利用いただけるようになりました。この A2 VM ファミリーは NVIDIA Ampere A100 Tensor Core GPU を基盤としています。VM あたり最大で 16 個の GPU が使用可能な A2 VM は、パブリック クラウド初の A100 を基盤としたサービスです。現在は、Google の限定公開アルファ版プログラムでのみご利用可能ですが、今年後半には一般公開が予定されています。
NVIDIA Ampere A100 GPU を備え、アクセラレータが最適化された VM
A2 VM ファミリーは、CUDA による機械学習(ML)トレーニングと推論、ハイ パフォーマンス コンピューティング(HPC)など、非常に厳しい要件が求められる最新のアプリケーションのために設計されました。40 GB の高性能 HBM2 GPU メモリを搭載した A100 GPU は、旧世代の GPU と比較して、GPU 1 個あたり最大 20 倍の処理パフォーマンスを誇ります。また A2 は、複数の GPU ワークロードの高速化のために、NVIDIA の HGX A100 システムを使用して、NVLink による最大 600 GB/秒の高速な GPU 間の帯域幅を実現しています。A2 VM では、最大 96 個の Intel Cascade Lake vCPU、GPU への高速なデータフィードを必要とするローカル SSD(オプション)、最大 100 Gbps のネットワーキングをご利用いただけます。さらに、A2 VM では vNUMA を提供することで、基盤となる GPU サーバー プラットフォームのアーキテクチャが完全に透明化され、高度なパフォーマンス チューニングが実現します。
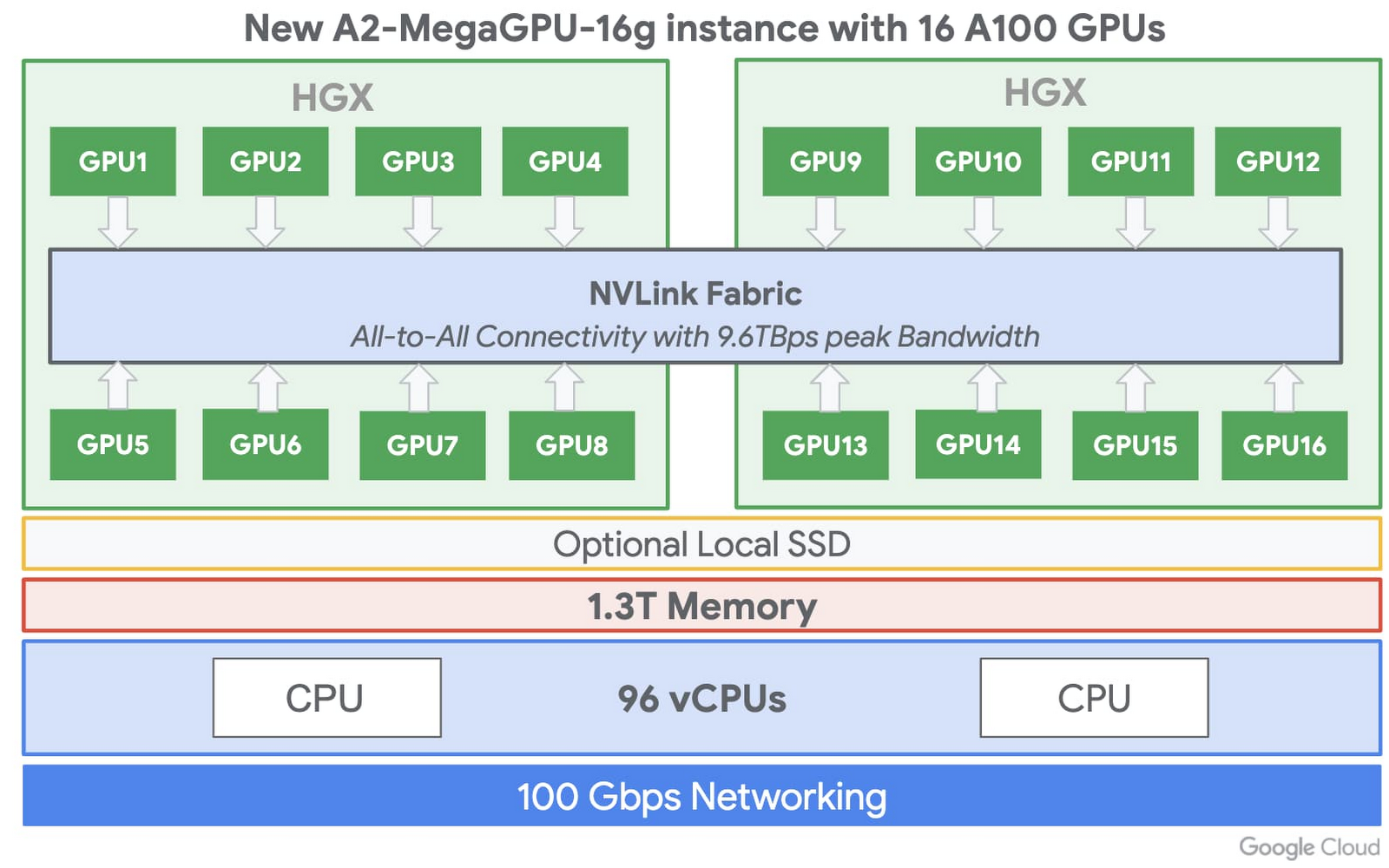
VM あたり 16 個の GPU
要求の厳しいワークロードでは、マシンは大きければ大きいほど良いとされる場合があります。Google はこのようなワークロード向けに a2-megagpu-16g インスタンスをご用意しています。これは A100 GPU を 16 個備え、合計 640 GB の GPU メモリが利用可能です。また、新しいスパース機能を使用した単一の VM の場合、FP16 で最大 10 PFLOPS、INT8 で 20 PFLOPS の、効率性に優れたパフォーマンスを実現できます。パフォーマンスを最大化し、大規模なデータセットに対応するため、このインスタンスでは 1.3 TB のシステムメモリと、最大 9.6 TB/秒の NVLink の合計帯域幅が利用可能な NVLink の網羅的なトポロジを備えています。コンピューティング負荷の高いプロジェクトに、このインフラストラクチャをぜひご活用ください。
また、A2 VM はアプリケーションの GPU コンピューティング能力のニーズに合わせて、小規模な構成でもご利用いただけます。さらに、GPU に対して 2 つの異なる CPU 比率とネットワーキング比率が提供されるため、前処理性能と複数の VM のネットワーキングの性能をアプリケーションに合わせることができます。
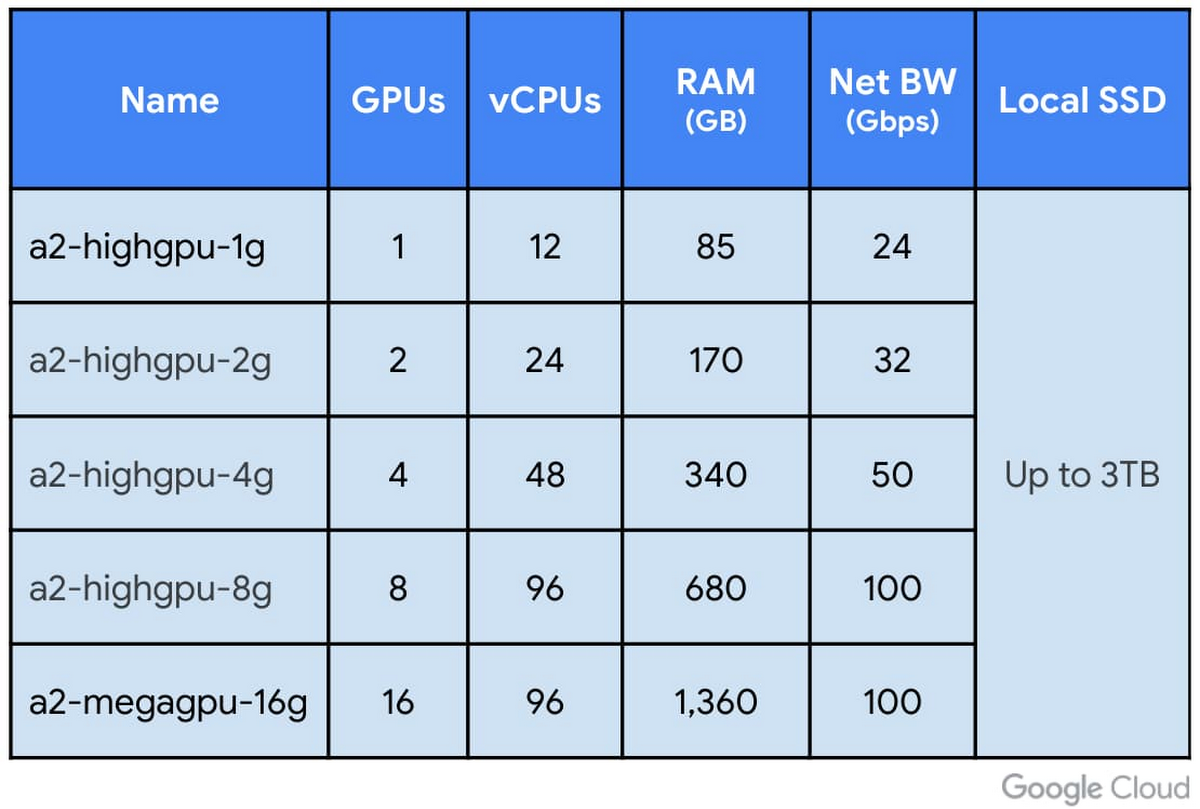
利用可能な A2 VM 構成
新しい NVIDIA Ampere アーキテクチャ
A2 インスタンス向けの新しい GPU アーキテクチャは複数の革新的な機能を備え、多くの ML ワークロードや HPC ワークロードですぐにメリットを享受できます。A100 の新精度である Tensor Float 32(TF32)により、旧世代の V100 における FP32 のパフォーマンスと比較して、処理速度が 10 倍に向上しています。A100 は 16 ビットでの演算能力も強化され、FP16 と bfloat16(BF16)に対応し、TF32 での処理速度は 2 倍に達します。また、A100 では INT8、INT4、INT1 Tensor オペレーションもサポートされるようになったため、推論ワークロードの最適な選択肢でもあります。また、A100 の新しい Sparse Tensor コアの処理手順では、入力がゼロ値の演算をスキップできるため、INT8、FP16、BF16、TF32 形式の演算スループットが 2 倍になります。さらに、マルチインスタンス グループ(mig)機能により、各 GPU を最大 7 つにパーティション分割でき、パフォーマンスや障害分離の面で完全に隔離されたインスタンスにできます。これらの機能により、各 A100 のパフォーマンスの大幅な向上、メモリの増強、精度に対する非常に柔軟な対応、単一の GPU で複数のワークロードを実行する際のプロセス分離の改善を実現できます。
使ってみる
Google は、お客様が A2 VM シェイプを A100 GPU で簡単に使い始められるよう取り組んでいます。Compute Engine で Deep Learning VM Image を使用するのが手早い方法です。高パフォーマンスのワークロードを実行するのに必要なあらゆるものが、あらかじめ構成されています。また、A100 は近日中に Google Kubernetes Engine(GKE)、Cloud AI Platform、その他の Google Cloud サービスでもサポートされるようになります。
A2 VM ファミリーの詳細や、アルファ版の利用のリクエストについては、販売チームにご連絡いただくか、こちらからお申し込みください。一般提供開始や料金については、今年後半にお知らせします。
- プロダクト マネージャー Chris Kleban、テクニカル プログラム マネージャー Bharath Parthasarathy

