New Compute Engine A2 VMs—first NVIDIA Ampere A100 GPUs in the cloud
Chris Kleban
Group Product Manager, Google Cloud
Bharath Parthasarathy
Product Manager
Machine learning and HPC applications can never get too much compute performance at a good price. Today, we’re excited to introduce the Accelerator-Optimized VM (A2) family on Google Compute Engine, based on the NVIDIA Ampere A100 Tensor Core GPU. With up to 16 GPUs in a single VM, A2 VMs are the first A100-based offering in the public cloud, and are available now via our private alpha program, with public availability later this year.
Accelerator-Optimized VMs with NVIDIA Ampere A100 GPUs
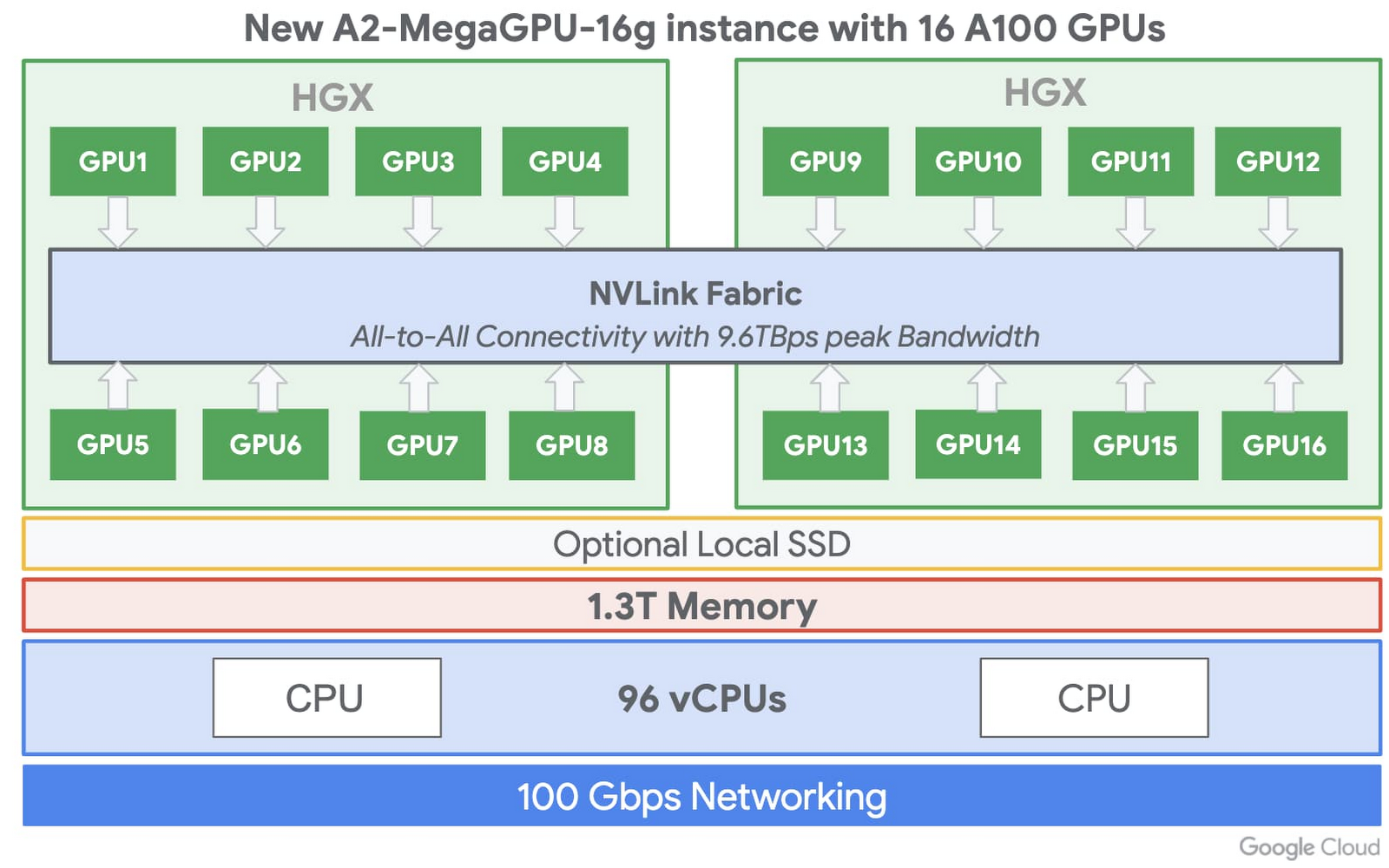
The A2 VM family was designed to meet today’s most demanding applications—workloads like CUDA-enabled machine learning (ML) training and inference, and high performance computing (HPC). Each A100 GPU offers up to 20x the compute performance compared to the previous generation GPU and comes with 40 GB of high-performance HBM2 GPU memory. To speed up multi-GPU workloads, the A2 uses NVIDIA’s HGX A100 systems to offer high-speed NVLink GPU-to-GPU bandwidth that delivers up to 600 GB/s. A2 VMs come with up to 96 Intel Cascade Lake vCPUs, optional Local SSD for workloads requiring faster data feeds into the GPUs and up to 100 Gbps of networking. Additionally, A2 VMs provide full vNUMA transparency into the architecture of underlying GPU server platforms, enabling advanced performance tuning.
A whopping 16 GPUs per VM
For some demanding workloads, the bigger the machine, the better. For those, we have the a2-megagpu-16g instance with 16 A100 GPUs, offering a total of 640 GB of GPU memory and providing an effective performance of up to 10 petaflops of FP16 or 20 petaOps of int8 in a single VM when using the new sparsity feature. To maximize performance and support the largest datasets, the instance comes with 1.3 TB of system memory and an all-to-all NVLink topology with aggregate NVLink bandwidth up to 9.6 TB/s. We look forward to seeing how you use this infrastructure for your compute-intensive projects.
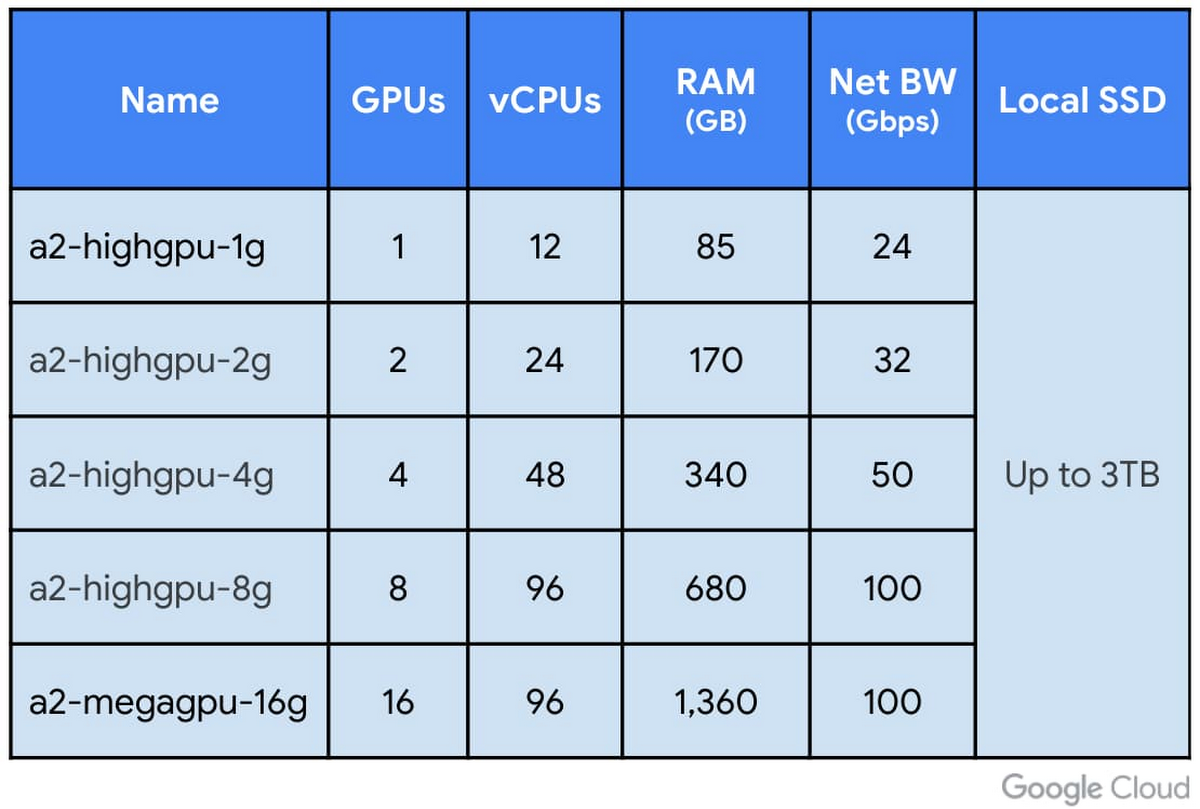
Of course, A2 VMs are available in smaller configurations as well, allowing you to match your application’s needs for GPU compute power. The A2 family of VMs come in two different CPU- and networking-to-GPU ratios, allowing you to match the preprocessing and multi-vm networking performance best suited for your application.
NVIDIA’s new Ampere architecture
The new Ampere GPU architecture for our A2 instances features several innovations that are immediately beneficial to many ML and HPC workloads. A100’s new Tensor Float 32 (TF32) format provides 10x speed improvement compared to FP32 performance of the previous generation Volta V100. The A100 also has enhanced 16-bit math capabilities supporting both FP16 and bfloat16 (BF16) at double the rate of TF32. INT8, INT4 and INT1 tensor operations are also supported now making A100 an equally excellent option for inference workloads. Also, the A100’s new Sparse Tensor Core instructions allow skipping the compute on entries with zero values, resulting in a doubling of the Tensor Core compute throughput of int8, FP16, BF16 and TF32. Lastly, the multi-instance group (mig) feature allows each GPU to be partitioned into as many as seven GPU instances, fully isolated from a performance and fault isolation perspective. All together, each A100 will have a lot more performance, increased memory, very flexible precision support, and increased process isolation for running multiple workloads on a single GPU.
Getting started
We want to make it easy for you to start using the A2 VM shapes with A100 GPUs. You can get started quickly on Compute Engine with our Deep Learning VM images, which come preconfigured with everything you need to run high-performance workloads. In addition, A100 support will be coming shortly to Google Kubernetes Engine (GKE), Cloud AI Platform, and other Google Cloud services.
To learn more about the A2 VM family and request access to our alpha, either contact your sales team or sign up here. Public availability and pricing information will come later in the year.


