AI モデルをホストするうえでの自己ホスト型 GKE かマネージド Vertex AI かの選択
Dan Dobrin
Enterprise App Modernization Architect, Google
Yanni Peng
Customer Engineer
※この投稿は米国時間 2024 年 8 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
昨今のテクノロジー環境において、アプリケーションをビルドまたはモダナイズするには、ビジネスの目標とユースケースを明確に理解する必要があります。この理解は、特に大規模言語モデル(LLM)などの生成 AI 基盤モデルといった新たなツールを効果的に活用するために不可欠です。
LLM は大きな競争優位性をもたらしますが、それを問題なく実装できるかは、プロジェクトの要件を十分に理解しているかによって決まります。このプロセスにおける重要な決定事項は、Vertex AI などのマネージド LLM ソリューションと、Google Kubernetes Engine(GKE)などのプラットフォーム上の自己ホスト型オプションのどちらを選択するかです。
このブログ投稿では、LLM 推論のための最新アプリをデプロイする「理由」と「方法」に関する重要な問いに答えるために、開発者、運用スペシャリスト、IT 関連の意思決定者に必要な情報を提供します。使いやすさとカスタマイズの両方を意識して、LLM デプロイ戦略を最適化できるよう支援します。この投稿では、以下の方法を説明します。
-
サーバーレス アーキテクチャのシンプルさとスケーラビリティを紹介しつつ、LLM 推論を効率的に行うために Cloud Run 上に Java アプリをデプロイする方法。
-
Cloud Run を補完し、より複雑な LLM デプロイを実現する堅牢な AI インフラストラクチャ プラットフォームとして Google Kubernetes Engine(GKE)を使用する方法。
さっそく始めましょう。
AI 開発に Google Cloud を選ぶ理由
ではまず、LLM を搭載したアプリケーションをビルド、デプロイ、スケールする際に考慮すべき要因にはどのようなものがあるでしょうか。Google Cloud で AI アプリケーションを開発すると、次のようなメリットが得られます。
-
選択肢: マネージド LLM を使用するか、独自のオープンソース モデルを Vertex AI に持ち込むかを選択できます。
-
柔軟性: Vertex AI にデプロイするか、LLM のニーズに合わせたカスタム インフラストラクチャとして GKE を利用できます。
-
スケーラビリティ: LLM インフラストラクチャを必要に応じてスケールし、需要の増加に対応できます。
-
エンドツーエンドのサポート: LLM のライフサイクル全体に対応する包括的なツールとサービスのスイートを活用できます。
マネージドか自己ホスト型モデルか
Google Cloud での AI 開発のための選択肢を長期的な戦略目標と照らし合わせて検討するときは、チームの専門知識、予算面の制約、カスタマイズ要件などの要因を考慮しましょう。2 つのオプションを簡単に比較してみましょう。
マネージド ソリューション
長所:
-
簡単にデプロイ、管理できることによる使いやすさ
-
自動スケーリングとリソースの最適化
-
サービス プロバイダがアップデートを管理し、セキュリティ パッチを適用
-
他の Google Cloud サービスとの緊密な統合
-
組み込みのコンプライアンス機能とセキュリティ機能
短所:
-
インフラストラクチャとデプロイ環境のファインチューニングにおけるカスタマイズの制約
-
ベンダー ロックインの可能性
-
特に大規模に導入する場合、自己ホスト型より費用が高い
-
基礎インフラストラクチャをあまり管理できない
-
モデル選択に制限が課される可能性あり
GKE 上での自己ホスト
長所:
-
デプロイ環境の完全な管理が可能
-
大規模導入により費用削減も可能
-
オープンソース モデルを自由に選択、カスタマイズ可能
-
クラウド プロバイダ間でのポータビリティがより高い
-
きめ細かいパフォーマンスとリソースの最適化が可能
短所:
-
設定、メンテナンス、スケーリングに DevOps に関する相当な専門知識が必要
-
ユーザーがアップデートとセキュリティに責任を持つ必要あり
-
スケーリングとロード バランシングの構成を手動で行う必要あり
-
コンプライアンスとセキュリティに関連する負担が大きい
-
初期設定により時間がかかり、より管理が複雑
つまり、Vertex AI のようなマネージド ソリューションは、運用上のオーバーヘッドを最小限に抑えながら迅速にデプロイしたいチームに最適ですが、GKE 上の自己ホスト型ソリューションは、特定のカスタマイズ要件を持ち、ソリューションを完全に管理しつつ費用を削減したい優秀な技術チームに適しています。いくつかの例を見てみましょう。
Java で生成 AI アプリをビルドし、Cloud Run にデプロイする
このブログ投稿では、ユーザーが有名な書籍から引用文を取得できるアプリケーションを作成しました。当初の機能はデータベースから引用文を取得することでしたが、生成 AI 機能により機能セットが拡張され、ユーザーがマネージド型または自己ホスト型の大規模言語モデルから引用文を取得できるようになりました。
このアプリは、そのフロントエンドを含め、Cloud Run にデプロイされ、モデルは GKE で自己ホスト(モデルのサービングには vLLM を活用)され、Vertex AI で管理されます。このアプリは、CloudSQL データベースから事前に構成された書籍の引用文を取得することもできます。
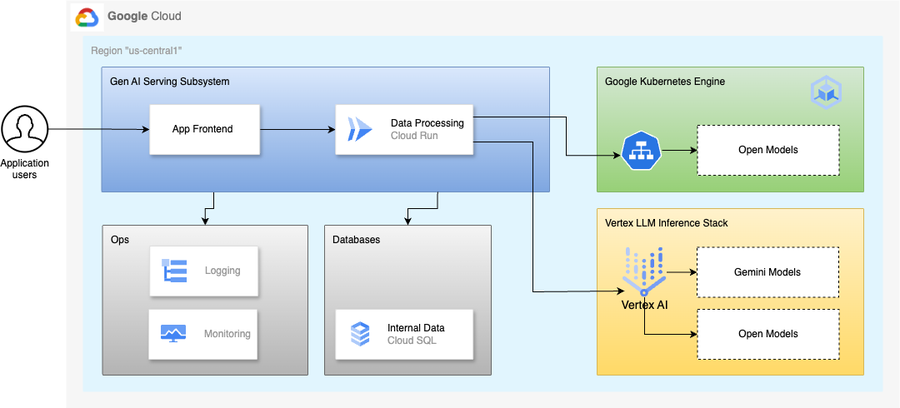
企業において生成 AI アプリケーションをビルドする際に Java が適している理由は以下のとおりです。
-
成熟したエコシステムと広範なライブラリ
-
スケーラビリティと堅牢性により、AI ワークロードの処理に最適
-
Spring AI 経由で AI モデルと簡単に統合可能
-
優れたセキュリティ機能
-
多くの組織に Java の専門知識を持つ膨大な人材が存在
Cloud Run は、最も簡単かつ迅速に本番環境で生成 AI アプリを運用できる方法で、これを使用するチームが実行できることは以下のとおりです。
-
リクエストに対応するための、迅速にスケーリング可能で、ゼロへのスケーリングも可能な API エンドポイントをビルドする
-
GKE と相互運用可能でポータブルなコンテナにおいて Java 生成 AI アプリを運用する
-
コード実行時のみ料金を支払う
-
開発者になじみのあるコードを記述し、アプリを迅速にデプロイする
始める前に
このブログ投稿を裏付ける Spring Boot Java アプリケーションは、Spring AI Orchestration Framework を活用しています。このアプリは Java 21 LTS と Spring Boot を基盤としてビルドされており、アプリには Cloud Run のビルド、テスト、デプロイ、ランタイムに関するガイドラインが含まれています。
所定の手順に沿って Git リポジトリのクローンを作成し、Java 21 と GraalVM の設定が完了していることを確認してください。
コードベースは、アプリのビルドおよび Cloud Run へのデプロイと、GKE へのオープンモデルのデプロイおよびそのモデルの構成それぞれに関するリファレンス ドキュメントによって補完されています。
GKE へのオープンモデルのデプロイ
まずはオープンモデル LLM を GKE にデプロイしてみましょう。このブログ投稿では、Meta-Llama-3.1-8B-Instruct オープンモデルを GKE にデプロイします。
LLM デプロイのための Hugging Face へのアクセスと API トークンの設定
ランタイム中に LLM をダウンロードするには、以下のステップを実行して、Hugging Face のアカウントと API トークンを設定します。
1. 前提条件:
-
選択したリージョンで利用可能な L4 GPU と十分な割り当てがある Google Cloud プロジェクトにアクセスできることを確認します。
-
kubectl と Google Cloud SDK がインストールされたコンピュータ ターミナルを用意します。Google Cloud プロジェクト コンソールの Cloud Shell を使用することもできます。この Cloud Shell には、必要なツールがすでにインストールされています。
2. Hugging Face のアカウントと API トークン:
-
ここで使用する Llama3.1 などのモデルを使用するには、Hugging Face API トークンをダウンロードする必要があります。
-
アクセス権を申請するには、Meta の Llama モデルのリソースページ(Meta Llama のダウンロード)をご覧ください。なお、ファイルをダウンロードするには、メールアドレスを登録する必要があります。
-
Hugging Face に移動して、Meta のアクセス申請時に登録したものと同じメールアドレスを使用して、アカウントを作成します。
-
Llama 3 モデルを探し、アクセス権申請様式に必要事項を記入します [Meta Llama 3.1-8B Instruct]。承認メールが届くまで根気よくメールボックスを確認してください。
-
承認後、アカウント プロファイル設定から Hugging Face のアクセス トークンを取得します。このアクセス トークンは、デプロイ プロセス中にモデルファイルを認証、ダウンロードするために使用されます。
3. GCP で大規模言語モデル(LLM)をデプロイするために適切なノードプールと GPU 構成を指定して GKE クラスタを設定するには、リポジトリのステップに従います。主なステップは、以下のとおりです。
オープンモデル LLM のデプロイと GCLB 構成のリファレンス ドキュメントは、こちらからご確認いただけます。
GKE の構成の詳細
1.デプロイ:
-
vllm-inference-server Pod の単一インスタンスを作成します
-
NVIDIA L4 GPU を使用して、特定のリソース(CPU、メモリ、エフェメラル ストレージ)を割り当てます
-
キャッシュと共有メモリ用の空のディレクトリをマウントします
2.サービス:
-
ClusterIP を使用して、デプロイを内部公開します
-
ポート 8000 でアクセスできるようにサービスを構成します
3.BackendConfig:
-
ロードバランサの HTTP ヘルスチェックを指定して、サービスの健全性を確認します
4.Ingress:
-
Google Cloud ロードバランサ(GCLB)経由でサービスを公開するように、Ingress リソースを構成します
-
ポート 8000 の
vllm-inference-serverサービスに外部トラフィックをルーティングします
vLLM は、Native vLLM API のほか、OpenAI API も公開します。このブログ記事では、マネージド型と GKE ホスト型のオープンモデル間の整合性を確保するため、OpenAI API の仕様に適合する API を使用します。
モデルと GCLB がデプロイされたら、デプロイ環境変数が以下の Open API キーと Hugging Face トークンの 2 つのシークレットを参照していることを確認してください。
-
vLLM の Open API キーは、お客様が定義し、環境変数 VLLM_API_KEY を使用して設定します。この環境変数では、英数字と特殊文字を任意に組み合わせることができます。また、このシークレットの管理には、Google Cloud Secret Manager を使用できます。
- Hugging Face トークンは、先に設定した Hugging Face のアカウントで利用可能です。
代わりにVertexAI で使用できるマネージド モデル
Vertex AI のフルマネージド サービスである Model Garden から有効化するだけで、Meta LLama3.1 オープンモデルにアクセスすることもできます。
このブログ記事では、コードベースの 405b パラメータで meta/llama3-405b-instruct-maas オープンモデルを使用します。
生成 AI Java アプリケーションの Cloud Run へのデプロイと構成
コード リポジトリのクローン作成が完了し、Java 21 がインストールされていることを確認します [こちらをお読みください]。
テストモデルに接続するために必要な環境変数を設定します。
アプリをビルドして、ローカル環境内で検証します [こちらをお読みください]。
コンテナ イメージをビルドして、Artifact Registry に push します [こちらをお読みください]。
Cloud Run にデプロイして、JVM、Cloud Run、LLM アクセス構成のための構成をプロビジョニングします [こちらをお読みください]。
アプリケーションをエンドツーエンドでテストする
Cloud Run にデプロイしたアプリケーションを以下のとおりエンドツーエンドでテストできます。
以下にモデルのレスポンス例を示します。
アプリの UI で、データベースで使用可能な割り当てを確認してから、GKE LLM デプロイを使用して、または Vertex AI 内で、LLM に割り当てを生成するよう依頼できます。

まとめ
このブログ投稿では、Google Cloud Platform における大規模言語モデル(LLM)と生成 AI アプリケーションのデプロイについて、独自の案内を提示しています。AI の導入をビジネスニーズに合わせることを重視し、マネージド Vertex AI ソリューションと Google Kubernetes Engine(GKE)上の自己ホスト型オプションを比較しています。
このブログ投稿の内容は以下のとおりです。
-
AI 開発における Google Cloud の利点: 柔軟性、スケーラビリティ、包括的なサポート
-
マネージド LLM ソリューションと自己ホスト型 LLM ソリューションの長所と短所
-
複雑な LLM デプロイに対応する GKE の機能
-
プロダクション レディな実例: LLM 推論を効率的に行うために Cloud Run にデプロイされた Spring AI Java アプリ
この投稿が、使いやすさとカスタマイズに関する要望にバランスよく対応する方法についての貴重な知見を提示し、LLM デプロイ戦略について情報に基づく意思決定を行うために必要な知識を得るうえで役立てば幸いです。
生成 AI の導入は、技術的側面ではなく、ビジネスニーズから始まることを忘れないでください。
関連情報
Google 社員 Rick(Rugui)Chen のブログ投稿 Serving Open Source LLMs on GKE using vLLM framework
-エンタープライズ アプリ モダナイゼーション担当アーキテクト Dan Dobrin
-カスタマー エンジニア Yanni Peng

