Vertex Matching Engine: 非常に高速かつスケーラブルな最近傍探索

Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
密なベクトル空間でデータを表現する方法であるベクトル エンベディングは、ML エンジニアが使用するツールの中で最も便利なツールです。
エンベディングの初期の使用例としては、単語のエンベディングがあります。単語のエンベディングは、ベクトル空間での位置(距離と方向)により、各単語の有意義なセマンティクスを符号化することができるため、一般的なツールとなりました。たとえば、次のような実際のエンベディングを可視化した図では、国とその首都の関係性のように、セマンティックな関係性を表す幾何学的な関係を示しています。
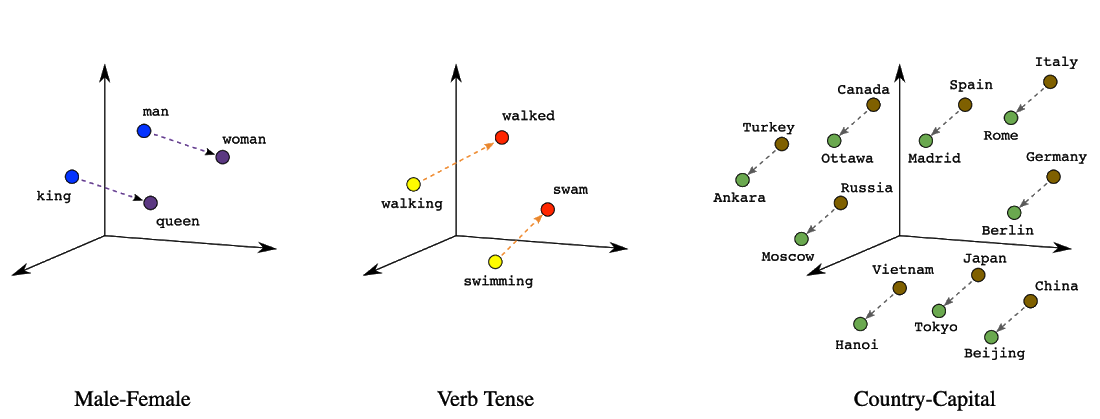
今日、単語のエンベディングやテキストのエンベディングは一般的に、セマンティック検索システムを強化するために使用されています。エンベディングベースの検索は、単純なインデックス可能なプロパティではなく、セマンティックな理解に依存するクエリに回答するのに有効な手法です。この手法では、クエリとデータベース アイテムを共通のベクトル エンベディング空間にマッピングするように機械学習モデルがトレーニングされ、意味的に類似するアイテムがより近くに配置されます。このアプローチでクエリに回答するために、システムはまずクエリをエンベディング空間にマッピングする必要があります。これが最近傍探索問題(「ベクトル類似性検索」と呼ばれることもある)で、すべてのデータベース エンベディングから対象のクエリに最も近いものを見つける必要があります。
図 2: 上記の 2 タワー ニューラル ネットワーク モデルは、エンベディング型検索の一種であり、クエリとデータベース アイテムが 2 つの各ニューラル ネットワークによってエンベディング空間にマッピングされます。この例では、モデルは仮想的な文学データベースに対する自然言語クエリに応答しています。
エンベディングの利用は、単語やテキストに限られません。機械学習モデル(多くの場合、ディープ ラーニング モデル)を使用すると、写真、オーディオ、ムービー、ユーザーの好みなど、さまざまな種類のデータのセマンティックなエンベディングを生成できます。これらのエンベディングは、あらゆる種類の機械学習タスクに利用できます。
一例として、画像の類似性検索があります。画像のエンベディングを使用すると、Google 画像検索のように、1 つの画像を使用して他の類似した画像を検索できます。また、お客様の購入履歴を基にエンベディングを生成することで、似たようなお客様や商品を見つけ出し、よりよい提案が可能になります。
エンベディングの用途は実に広大で、次のようなものに利用されています。
レコメンデーション エンジン
検索エンジン
広告ターゲティング システム
画像分類や画像検索
テキスト分類
質問への回答
Chat bot
上記の用途以外にもさまざまな用途にエンベディングは利用されています。
さらに、一部の用途では、独自にモデルを構築してエンベディングを生成する必要がありますが(自社の顧客をモデル化するなど)、エンベディングを生成するモデルの多くは、テキスト用の Universal Sentence Encoder や画像用の ResNet のように、無料で使用でき、オープンソース化されています。そのため、独自のトレーニング データが十分にない場合、ベクトル エンベディングが特に便利な ML 手法になります。
しかし、ベクトル エンベディングはデータを表現する非常に便利な方法であるという事実にもかかわらず、現在のデータベースは効果的にベクトル エンベディングを実行できるように設計されていません。特に、ベクトル空間で最近傍探索を実行するためには設計されていません(例: データベースの中で、クエリ画像に最も似ている 10 枚の画像を検索するなど)。大規模なデータセットでこうしたタスクを実行するのは、膨大な計算が必要になるため困難であり、迅速かつ大規模に処理するためには洗練された近似アルゴリズムが必要です。
こうした問題を解決するのが Vertex Matching Engine です。Vertex Matching Engine は非常に高速かつスケーラブルなベクトル類似性検索を実現するフルマネージド ソリューションです。
Vertex Matching Engine は、こちらのブログ投稿で紹介されている Google の研究によって開発された最先端の技術に基づいています。この技術は、検索、YouTube のおすすめ、Play ストアなど、Google の広範なアプリケーションで大規模に使用されています。
Vertex Matching Engine の特徴的な機能を見てみましょう。
スケーリング: 何十億ものエンベディング ベクトルを、秒間クエリ数が高い状態でも、低レイテンシで検索が可能です。何百万ものベクトルを検索できる一般的な最近傍サービスでも、優れた AI アプリケーションを構築できます。しかし、何十億ものベクトルを検索できるサービスがあれば、真に革新的なアプリケーションを構築できます。
低 TCO: 何十億ものベクトルの規模で動作するサービスを設計するためには、リソースを効率的に利用する必要があります。結局のところ、ハードウェアを増やすだけではスケーリングを行うことはできません。Google のテクノロジーのリソース効率により、Vertex Matching Engine は実際、主要な代替サービスよりも約 40% コストを抑えることができます(Google Cloud 社内調査、2021 年 5 月)。
低レイテンシで高い再現率: システムが総当たりで検索を行った場合、秒間クエリ数が高い状態でエンベディング ベクトルの大規模なコレクションを検索し、低レイテンシで結果を提供することは不可能です。これを行うには、ある程度の精度を引き換えに、非常に高速かつスケーラブルな検索を実現する高度な近似アルゴリズムを使用する必要があります。こちらの論文では、その基礎となる技術をより詳細に説明しています。このシステムでは基本的に、ほとんどの最近傍を検索することを非常に低いレイテンシで試みます。再現率は、システムによって返される真の最近傍の割合を測定するために使用される指標です。Google 社内のチームによる実証的な統計によると、多くの実世界のアプリケーションにおいて、Vertex Matching Engine は 95~98% の再現率を達成し、10ms 以下で 90 パーセンタイルのレイテンシで結果を提供できることがわかっています(Google Cloud 社内調査、2021 年 5 月)。
フルマネージド: Matching Engine は、自動スケーリング対応のフルマネージド ソリューションです。インフラストラクチャの管理を気にすることなく、優れたアプリケーションの構築に専念できます。
内蔵フィルタリング: 実世界のアプリケーションでは多くの場合、ベクトル マッチングによるセマンティック類似性は、結果をフィルタリングするために使用される他の制約や基準と連携します。たとえば、e コマースサイトがおすすめを表示する際、商品カテゴリまたはユーザーの地域に応じてフィルタリングを行うことがあります。Vertex Matching Engine を使用すると、ユーザーはブール論理を使用して単純または複雑なフィルタリングを実行できます。
Vertex Matching Engine の使い方
ユーザーは、事前に計算されたエンベディングを GCS でファイル形式で提供します。各エンベディングには、関連する一意の ID と、フィルタリングに使用できるオプションのタグ(トークンまたはラベル)があります。Matching Engine は、エンベディングを取り込み、インデックスを作成します。その後、インデックスはクラスタにデプロイされます。クラスタはオンライン クエリを受け取り、ベクトル類似性マッチングを実行します。クライアントは、クエリベクトルを使ってインデックスを呼び出し、返すべき最近傍の数を指定できます。そして、一致したベクトルの ID と、それに対応する類似度スコアがクライアントに返されます。
実際のアプリケーションでは、エンベディングを定期的に更新、または新しく生成するのが一般的です。そのため、ユーザーは、エンベディングの更新されたバッチを提供し、インデックスの更新を行うことができます。新しいエンベディングから更新されたインデックスが作成され、ダウンタイムやレイテンシへの影響なしで、既存のインデックスが置き換えられます。
インデックスを作成する際には、レイテンシと再現率のバランスをとるために、インデックスを調整することが重要です。主な調整項目はこちらでご説明しています。Matching Engine ではブルート フォース インデックスを作成する機能も利用でき、調整に役立ちます。ブルート フォース インデックスは、特定のクエリベクトルの「グラウンド トゥルース」の最近傍を検索するために便利なユーティリティです。ブルート フォース インデックスはネイティブ ブルート フォース サーチを実行するため、速度が遅く、本番環境では使用すべきではありません。インデックスの調整中に「グラウンド トゥルース」の最近傍を取得することで、再現率を計算できるようになり、調整に役立ちます。
高度な ML / AI アプリケーションに最適なクラウド
独自の AI / ML アプリケーションのために Google が開発した優れたインフラストラクチャにアクセスできるという理由から、多くのお客様が Google Cloud を選択しています。Matching Engine により、業界をリードする Google サービスをまた一つ、お客様にご提供できることになりました。皆さまがこのサービスを活用して優れたアプリケーションを構築されるのを楽しみにしております。
まずは、こちらのドキュメントと、このサンプル ノートブックをご覧ください。
-Cloud AI Platform プロダクト マネージャー Anand Iyer


