リモートやイベントでトリガーされる AI Platform Pipelines の使用
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習ワークフローはデータの準備や分析からトレーニング、評価、デプロイに至るまで、相互に依存するさまざまな手順を伴う場合があります。ノートブックやスクリプトの組み合わせなど、場当たり的な方法でこうしたプロセスを作成、追跡することは困難であり、監査や再現性といった問題はますます解決しづらくなっています。
今年リリースした Cloud AI Platform Pipelines は、このような問題の解決に役立ちます。堅牢で再現可能な機械学習パイプラインをデプロイする手段を提供するだけでなく、モニタリング、監査、バージョン トラッキング、再現性も実現します。また、ML ワークフローのために、エンタープライズ向けのインストールしやすい安全な実行環境を提供します。
Pipelines Dashboard UI を使用すると、パイプラインのアップロード、実行、モニタリングが簡単になりますが、プログラムで Pipelines フレームワークにアクセスすることをおすすめします。それにより、ノートブックからパイプラインを構築して実行し、パイプライン、テスト、実行をプログラムで管理できます。始めるにあたり、Pipelines インストール エンドポイントの認証が必要になります。認証の方法はコードが実行されている環境によって異なります。本日はこの点に重点を置いて説明します。
イベントによってトリガーされるパイプラインの呼び出し
今回取り上げる興味深いユースケースの一つは、Cloud Functions などのサービスで SDK を使用して、イベントによってトリガーされるパイプラインの呼び出しを設定することです。これにより、GCS バケットに追加された新しいデータ、PubSub トピックに追加された新しい情報、その他のイベントに基づいてデプロイを開始できます。
AI Platform Pipelines ではパイプラインを指定する場合に、Kubeflow Pipelines(KFP)SDK を使用するか、TensorFlow Extended(TFX) パイプライン テンプレートを TFX SDK でカスタマイズします。Pipelines クラスタの外部から SDK で接続するには、リモート環境で認証情報を設定して、AI Platform Pipelines インストールのエンドポイントにアクセスできるようにする必要があります。多くの場合、gcloud をアカウントにインストールして初期化するのが簡単なとき(または AI Platform Notebooks の場合と同様に、設定が済んでいるとき)、接続は透過的です。
または、Google Cloud で実行している場合、gcloud の初期化が簡単ではない状況では、基盤となる VM のメタデータを通じてアクセス トークンを取得し使用することで認証できます。そのランタイム環境が Pipelines のインストールで使用されているものとは異なるサービス アカウントを使用している場合は、そのサービス アカウントに Pipelines エンドポイントへのアクセス権を付与する必要もあります。このシナリオの例としては、Cloud Functions のインスタンスがプロジェクトの App Engine サービス アカウントを使用する場合などが挙げられます。
最後に、実行環境が Google Cloud ではなく、gcloud がインストールされていない場合は、サービス アカウントの認証情報ファイルを使用してアクセス トークンを生成できます。
以下では、上記オプションについて説明し、パイプラインの実行を開始する Cloud Functions の関数を定義して、イベントによってトリガーされるパイプライン ジョブを設定する方法の例を示します。
Kubeflow Pipelines SDK を使用して、gcloud アクセスで AI Platform Pipelines クラスタに接続する
AI Platform Pipelines クラスタに接続するには、そのエンドポイントの URL をまず確認する必要があります。
簡単なのは、AI Pipelines ダッシュボードにアクセスし、[設定] をクリックする方法です。
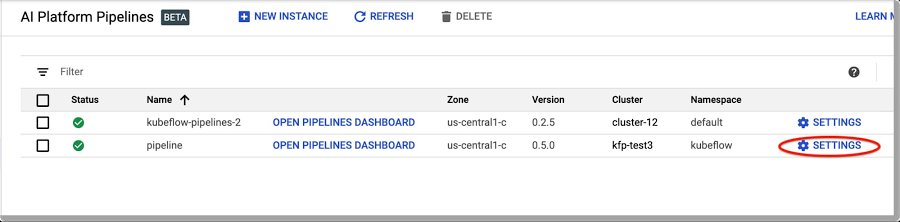
インストールに関する情報を取得するには [設定] をクリックします。
ポップアップ ウィンドウが次のように表示されます。
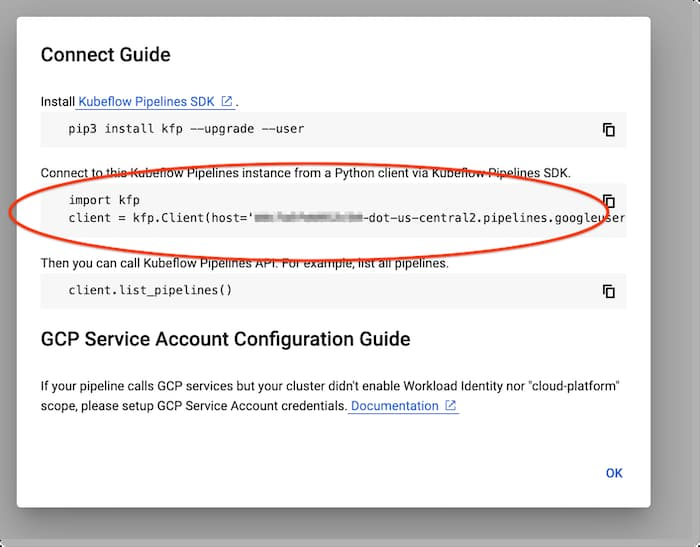
表示されたコード スニペットをコピーし、KFP SDK を使用してインストールのエンドポイントで接続します。この簡単なノートブックの例では、プロセスをテストできます(こちらは、代わりに TFX SDK と TFX テンプレートを使用する例です)。
AI Platform Notebooks から接続する
同じプロジェクトで実行されている AI Platform Notebooks を使用している場合、接続は正常に機能します。前述のとおり、Pipelines インストールのエンドポイントに URL を指定するだけで済みます。
ローカルマシンや開発マシンから接続する
代わりに、ローカルマシンや他の同様の環境から Pipelines インストールにデプロイすることもできます。gcloud をインストールし、アカウントの承認が完了した場合も認証が正常に機能します。
GCP ランタイムから AI Platform Pipelines エンドポイントに接続する
Cloud Functions、Cloud Run、App Engine などのサーバーレス環境で、異なるサービス アカウントを使用する一時的なインスタンスがある場合、gcloud の設定と初期化が問題になる可能性があります。ここでは別の方法を使用します。Cloud AI Pipelines の逆プロキシへのアクセスをサービス アカウントに許可し、クライアント オブジェクトの作成時に渡すアクセス トークンを取得します。これを行う方法について Cloud Functions の例を使用して説明します。
例: イベントによってトリガーされたパイプラインを Cloud Functions でデプロイする
Cloud Functions は、Google Cloud のイベント ドリブン型サーバーレス コンピューティング プラットフォームです。Cloud Functions を使用してパイプラインのデプロイメントをトリガーすると、イベントによってトリガーされるパイプラインをサポートする方法の可能性が大きく広がります。その場合、Google Cloud Storage バケットに追加された新しいデータ、PubSub トピックに追加された新しい情報などに基づいてデプロイを開始できます。
たとえば、データの新しいバッチを受信するか、AI Platform Data Labeling Service の「エクスポート」が完了したら、ML トレーニング パイプラインの実行を自動的に開始することもできます。
では、Cloud Storage バケットに新しいファイルを追加してパイプラインのデプロイがトリガーされる例を見てみましょう。
このシナリオでは、データセットを保持する Cloud Storage バケットに Cloud Functions トリガーを設定しない場合があります。その理由はファイルを追加するたびにトリガーされてしまうためです。更新に複数のファイルが含まれる場合は、おそらく必要な動作ではありません。代わりに、データのエクスポートまたは取り込みプロセスの完了時に、Cloud Storage ファイルを独立した「トリガー バケット」に書き込むことができます。このファイルには、新しく追加されたデータへのパスに関する情報が含まれます。そのバケットでトリガーするように定義された Cloud Functions の関数は、パイプラインの実行を開始する際に、ファイルの内容を読み取り、データパスに関する情報をパラメータとして渡すことができます。
パイプラインをデプロイするように Cloud Functions の関数を設定する主なステップは 2 つあります。まず、Cloud Functions で使用するサービス アカウント(プロジェクトの App Engine サービス アカウント)をプロジェクト閲覧者権限があるメンバーとして追加することにより、Pipelines インストールで使用するサービス アカウントへのアクセスを許可します。デフォルトでは、Pipelines サービス アカウントがプロジェクトの Compute Engine の既定サービス アカウントになります。
次に、トリガー時にパイプラインの実行を開始する Cloud Functions の関数を定義してデプロイします。この関数は Cloud Functions インスタンスのサービス アカウントに合わせてアクセス トークンを取得し、このトークンが KFP クライアント コンストラクタに渡されます。これで、クライアント オブジェクトを通じてパイプラインの実行を開始(または他のリクエストを送信)できます。
Cloud Storage ファイルまたはその内容のトリガーに関する情報は、パイプラインのランタイム パラメータとして渡すことができます。
Cloud Functions の関数には kfp SDK をインストールする必要があるため、これを指定する Cloud Functions のデプロイで使用される requirements.txt ファイルを定義しなくてはなりません。
こちらのノートブックは、この設定を行うプロセスを順に説明し、Cloud Functions の関数のコードを示します。この例では、パラメータとして渡されたファイル名をエコーするだけの非常に単純なパイプラインを定義しています。Cloud Functions の関数はそのパイプラインの実行を開始し、関数呼び出しをトリガーした新しいファイルや変更ファイルの名前を渡します。
サービス アカウントの認証情報ファイルを使用して Pipelines エンドポイントに接続する
ローカルで開発していて gcloud がインストールされていない場合は、ローカルで利用可能なサービス アカウント認証情報ファイルを通じて認証情報トークンを取得することもできます。その方法をこちらの例で紹介しています。最も簡単なのは、Pipelines のインストールに使用したものと同じサービス アカウント(デフォルトでは Compute Engine サービス アカウント)の認証情報を使用することです。それ以外の場合、別のサービス アカウントに Compute Engine アカウントへのアクセスを許可する必要があります。
まとめ
AI Platform Pipelines API を使用してパイプラインをリモートでデプロイする方法はいくつかあります。ここでご紹介したノートブックを使用すれば、スムーズに開始できるはずです。特に Cloud Functions を利用すると、イベントによってトリガーされるさまざまな種類のパイプラインをサポートできます。これを実践に移す方法について詳しくは、Cloud Functions ノートブックを参照して、新しいデータでパイプライン実行を自動起動する方法の例をご確認ください。上記のノートブックをお試しになり、ご意見やご感想をお聞かせください。私へのご連絡は Twitter アカウント @amygdala 宛てにお願いいたします。
-スタッフ デベロッパー アドボケイト Amy Unruh


