LLM-Evalkit のご紹介: Google Cloud でのプロンプト エンジニアリングのための実用的なフレームワーク
Mike Santoro
Field Solutions Architect, Google
Vipin Nair
Generative Blackbelt, Google
※この投稿は米国時間 2025 年 10 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
大規模言語モデル(LLM)を使用したことがある方なら、チームのプロンプトがドキュメント、スプレッドシート、さまざまなクラウド コンソールに散在している状況をよくご存じでしょう。多くの場合、イテレーションは手動で非効率的なプロセスであるため、どの変更が実際にパフォーマンスを向上させるかを追跡することは困難です。
この問題の解決へ向け、Google はこのプロセスを構造化するよう設計された軽量のオープンソース アプリケーションである LLM-Evalkit を発表します。LLM-Evalkit は、Google Cloud を使用して Vertex AI SDK 上に構築された実用的な軽量フレームワークで、プロンプト エンジニアリングを一元化して合理化し、客観的な指標を追跡したより効果的なイテレーションを可能にします。
分散したワークフローを一元化
現在、Google Cloud でプロンプトを管理するには、複数のツールを使いこなす必要があります。開発者が 1 つのコンソールでテストする一方で、プロンプトは別のドキュメントに保存し、評価には別のサービスを使用する、といったことが起こりえます。この断片化により、作業の重複が起こるとともに、標準化された評価プロセスの確立が難しくなります。チームメンバーによってプロンプトのテスト方法が少しずつ異なるため、結果に一貫性がなくなる可能性があります。
LLM-Evalkit は、これらの異なるツールを 1 つのまとまりのあるアプリケーションに抽象化することで、この問題を解決します。プロンプトの作成、テストから、バージョニング、ベンチマークまで、プロンプト関連のすべての活動を集中管理するハブとして機能し、これによりワークフローが簡素化され、すべてのチームメンバーが同じ手法を用いて作業できるようになります。共通のインターフェースにより、さまざまなプロンプトの履歴とパフォーマンスを時系列で簡単に追跡し、信頼できる記録システムを作成できます。
推測から測定へ
プロンプトのイテレーションが主観的な「感覚」や数例の出力に基づいて行われる例はあまりにも多いといわざるを得ません。たとえ当初は機能したとしてもスケールせず、あるプロンプトが別のプロンプトよりも本当に優れているとする根拠づけが難しくなります。
LLM-Evalkit は、プロンプト自体ではなく、解決しようとしている問題に焦点を移すことを推奨しています。その方法論は単純明快です。
-
具体的な問題から始める: LLM に実行させたいタスクを明確に定義します。
-
関連性の高いデータセットを収集または作成する: モデルが受け取る入力の種類をよく表す、一連のテストケースを構築します。
-
明確な測定基準を構築する: データセットに対するモデルの出力を評価するための客観的な指標を定義します。
このアプローチにより、体系的でデータドリブンなイテレーションが可能になります。新しいプロンプトが改善につながっているかどうかを推測するのではなく、一貫したベンチマークに照らし合わせてそのパフォーマンスを測定できます。客観的な指標に照らして進捗状況を追跡できるため、どの変更がより優れた、より信頼性の高い結果につながったのかが明確になります。
ノーコード アプローチでチームを支援
プロンプト エンジニアリングは、複雑なツールやコードに慣れている人だけのものではありません。数人の技術チームメンバーしかプロンプトを効果的に構築してテストできない場合、ボトルネックが発生し、開発サイクルが遅くなりますが、
LLM-Evalkit は、ノーコードでユーザー フレンドリーなインターフェースでこの問題に対処します。プロダクト マネージャー、UX ライター、貴重なドメイン知識を持つが開発者ではない主題専門家(SME)など、幅広いチームメンバーがプロンプト エンジニアリングに携われるようにすることを目標としています。プロセスを民主化することで、イテレーションが迅速化され、テストするアイデアの幅が広がり、技術担当者と非技術担当者の間でより良いコラボレーションを促進できます。
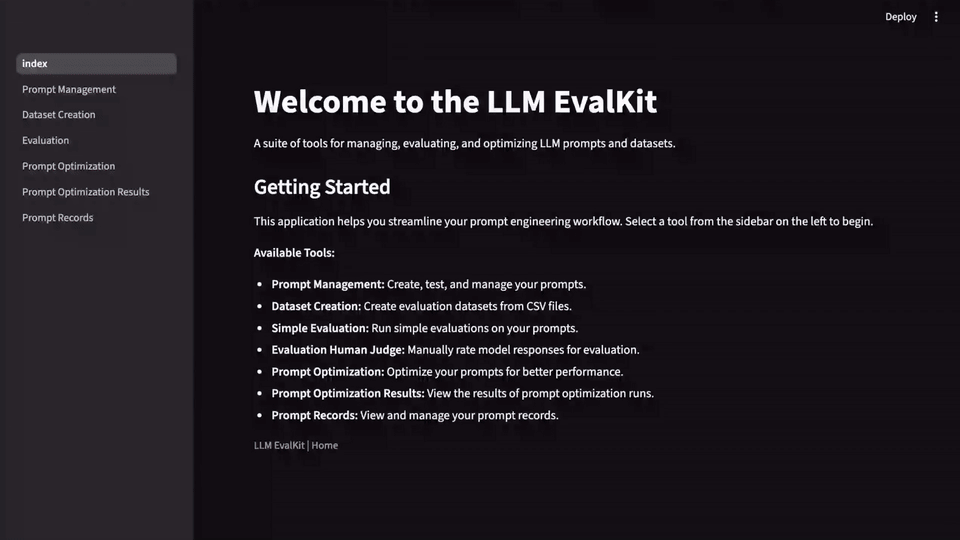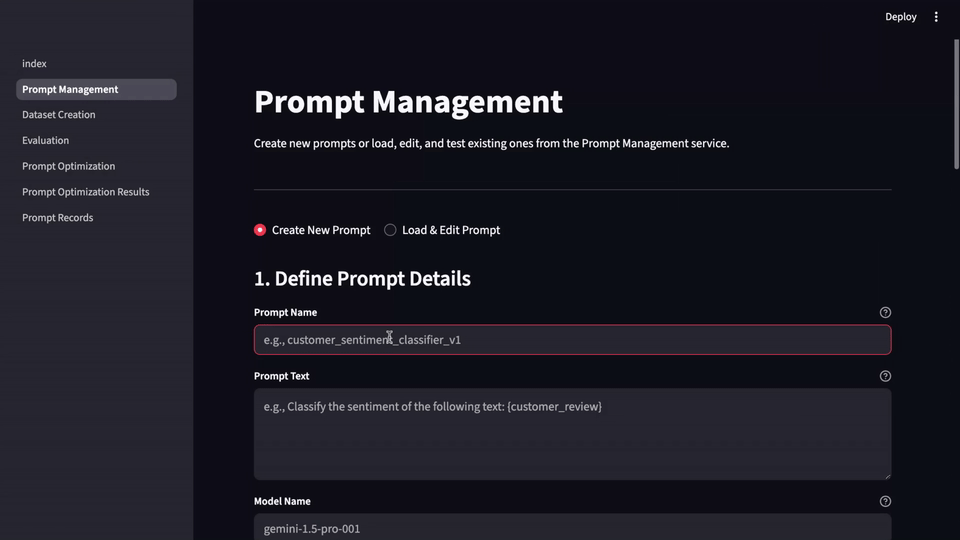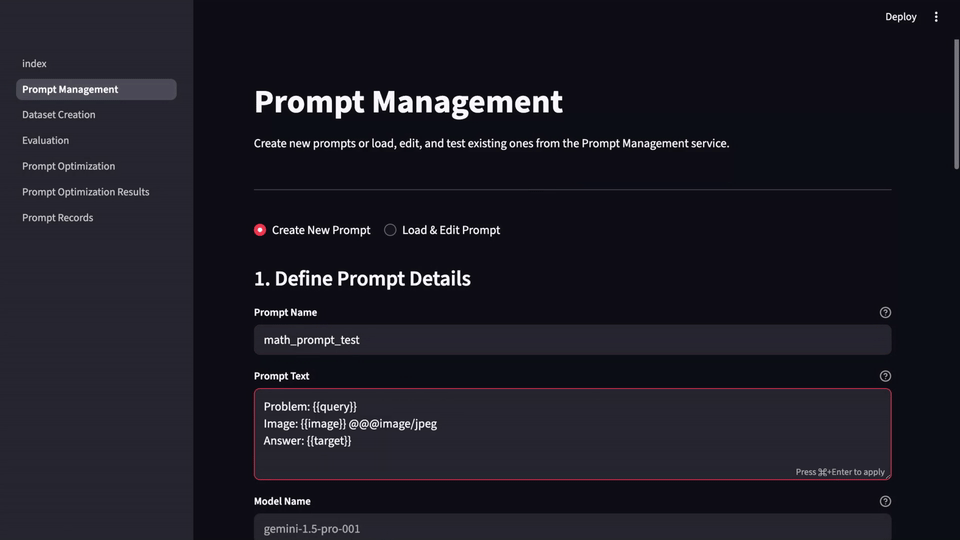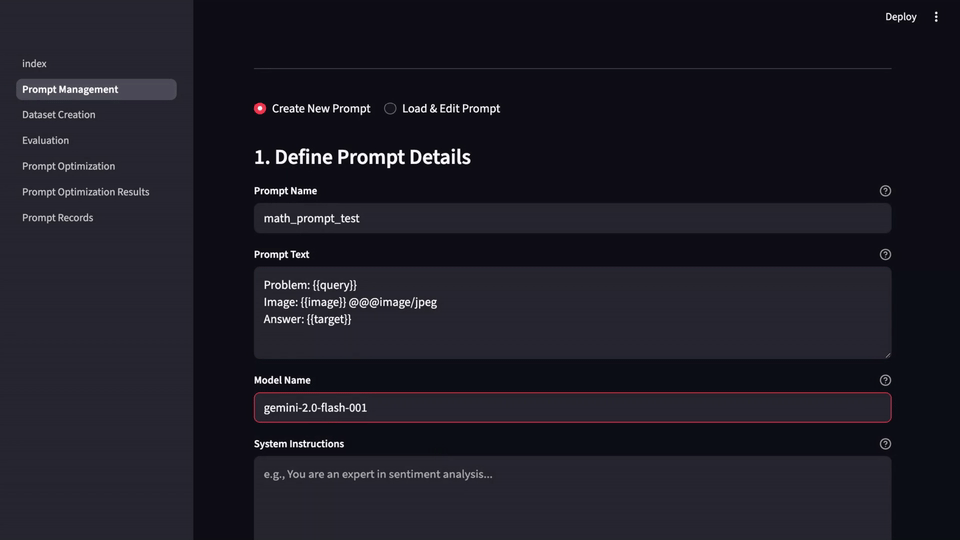
始める
LLM-Evalkit は、プロンプト エンジニアリングに、より体系的で共同作業的なアプローチをもたらすように設計されています。一元化された指標ドリブンなノーコード フレームワークを提供することで、アドホックにテストを行う体制から、より構造化された効率的なワークフローに移行できるようチームを支援します。
ぜひお試しください。オープンソース リポジトリとドキュメントは、GitHub でご確認いただけます。皆様のチームがこのツールをどのように活用して、LLM をより効果的に構築していくのか、楽しみにしています。最新の評価機能については、Google Cloud コンソールで直接ご確認いただけます。ガイド付きのアプローチをご希望の場合は、コンソールで実行する専用のチュートリアルをご利用いただけます。このチュートリアルでは、プロンプト エンジニアリングのあらゆるニーズに対応する柔軟なオプションが提供され、プロセス全体が説明されます。
-Google、フィールド ソリューション アーキテクト、Mike Santoro
-Google、生成 AI ブラックベルト Vipin Nair



