Cloud AI Platform Pipelines のご紹介
Google Cloud Japan Team
※この投稿は米国時間 2020 年 3 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
ノートブックで機械学習(ML)モデルのプロトタイプを作成している最中は、かなり簡単に思えるかもしれません。ですが、ML ワークフローを持続可能かつスケーラブルにするために必要な他の部分が気になりだすと、事態は複雑になります。機械学習のワークフローには、データの準備や分析からトレーニング、評価、デプロイなどに至るまで、相互に依存するステップが多数含まれます。こうしたプロセスをアドホックな方法(一連のノートブックやスクリプト)で構成、追跡することは難しく、監査や再現性などの問題はますます対処しづらくなります。
本日、Cloud AI Platform Pipelines のベータ版がリリースされます。Cloud AI Platform Pipelines は、堅牢で再現可能な機械学習パイプラインをデプロイする方法だけでなく、モニタリング、監査、バージョン トラッキングの各機能や、再現性を提供します。また、ML ワークフローのための、エンタープライズ対応でインストールしやすい安全な実行環境を実現します。
AI Platform Pipelines では以下をご利用になれます。
Google Cloud Console 経由のプッシュボタン式インストール
ML ワークロードを実行するためのエンタープライズ機能(パイプラインのバージョニング、アーティファクトと実行の自動メタデータ トラッキング、
Cloud Logging、可視化ツールなど)BigQuery、Dataflow、AI Platform Training、AI Platform Serving、
Cloud Functions をはじめとする Google Cloud マネージド サービスとのシームレスな統合ML ワークフロー向けに事前に構築された多くのパイプライン コンポーネント(パイプライン ステップ)、独自のカスタム コンポーネントの簡単な構築
AI Platform Pipelines は 2 つの主要な部分で構成されています。1 つは GCP サービスと統合された構造化 ML ワークフローをデプロイし実行するためのエンタープライズ対応インフラストラクチャで、もう 1 つはパイプラインとコンポーネントを構築、デバッグ、共有するためのパイプライン ツールです。
この記事では、AI Platform Pipelines を使用して ML ワークフローをホストする機能とメリットを大きく取り上げ、技術スタックを紹介し、新機能をいくつか説明します。
AI Platform Pipelines を使用するメリット
インストールと管理が簡単
AI Platform Pipelines には、Cloud Console の AI Platform パネルからアクセスします。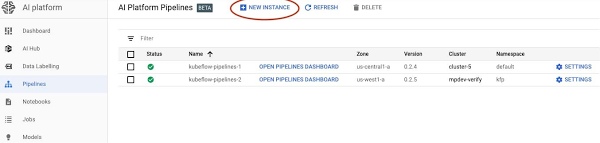
インストール プロセスは軽量でプッシュボタン式であり、ホストされているモデルによって管理と使用が簡素化されています。AI Platform Pipelines は Google Kubernetes Engine(GKE)クラスタ上で実行されます。インストール プロセスの一環としてクラスタが自動的に作成されますが、必要に応じて既存の GKE クラスタを使用できます。Cloud AI Platform UI を使用すると、すべてのクラスタを表示、管理できます。また、Pipelines インストールをクラスタから削除して再インストールし、以前のインストールから存続している状態を保持しながら Pipelines のバージョンを更新することもできます。
認証アクセスが簡単
AI Platform Pipelines では、Cloud AI Platform UI から Pipelines UI への安全な認証アクセスが可能になり、ポート転送を設定する必要がありません。また、チームの他のメンバーにアクセス権を付与することもできます。
同様に、REST API サービスを介してプログラムによって Pipelines クラスタにアクセスするのも簡単にできます。これにより、Cloud AI Platform Notebooks の Pipelines SDK を使用して、パイプラインの定義やパイプライン実行ジョブのスケジュール設定などのタスクを実行しやすくなります。
AI Platform Pipelines の技術スタック
AI Platform Pipelines では Kubeflow Pipelines(KFP)SDK を使用するか、TFX SDK で TensorFlow Extended(TFX)パイプライン テンプレートをカスタマイズして、パイプラインを指定します。SDK はパイプラインをコンパイルして Pipelines REST API に送信します。AI Pipelines REST API サーバーは、実行するためのパイプラインを保存し、スケジュール設定します。AI Pipelines は Argo ワークフロー エンジンを使用してパイプラインを実行します。また、メタデータの記録、コンポーネント IO の処理、パイプライン実行のスケジュール設定を行うその他のマイクロサービスも用意されています。パイプライン ステップは GKE クラスタで個別の分離ポッドとして実行され、パイプライン コンポーネントの Kubernetes ネイティブ エクスペリエンスを実現します。パイプライン コンポーネントでは Dataflow、AI Platform Training、AI Platform Prediction、BigQuery などの Google Cloud サービスを活用して、スケーラブルな計算やデータ処理に対応できます。また、GKE の自動スケーリングとノードの自動プロビジョニングを直接活用して、クラスタ内でかなりの量の GPU や TPU の計算を行うステップをパイプラインに含めることもできます。
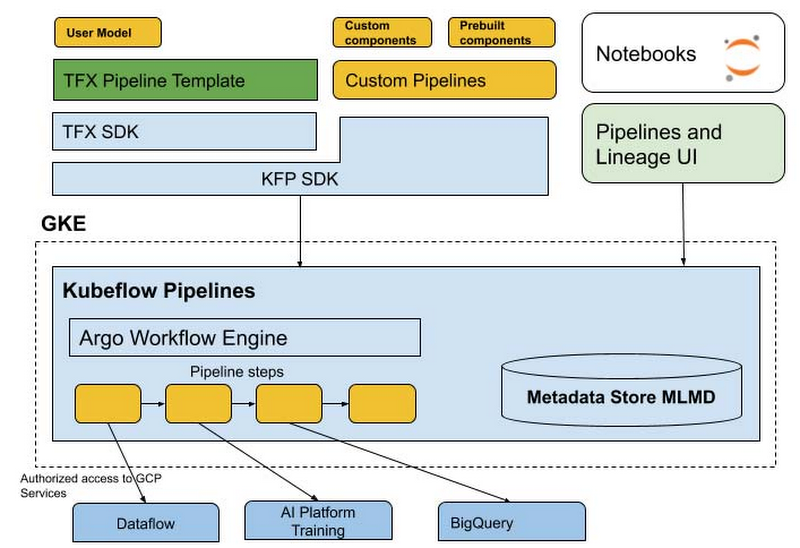
このスタックの一部を詳しく見てみましょう。
SDK
Cloud AI Platform Pipelines では、Kubeflow Pipelines SDK(Kubeflow OSS プロジェクトの一部)と TFX SDK という 2 つの SDK が ML パイプラインの作成のためにサポートされています。
この 2 つの SDK エクスペリエンスは今後統合される予定です。TFX SDK は、フレームワークに依存しない、KFP SDK で利用可能な操作をサポートします。また、既存の KFP SDK ユーザーがマージ済み SDK に簡単にアップグレードできる移行パスも提供されます。
2 つの異なる SDK がある理由
Kubeflow Pipelines SDK は ML フレームワークに依存しない下位レベルの SDK であり、Kubernetes リソースの直接制御とコンテナ化されたコンポーネントの単純な共有(パイプライン ステップ)が可能になります。
TFX SDK は現在プレビュー モードであり、ML ワークロード向けに設計されています。TFX SDK は、規範的でカスタマイズ可能なコンポーネントによって上位レベルの抽象化を実現します。これには、耐久性のあるスケーラブルな ML パイプラインの Google ベスト プラクティスに相当する定義済みの ML タイプが使用されます。また、本番環境の ML 用として、Google 内部で開発、使用され、TensorFlow 用に最適化されたカスタマイズ可能なテンプレートのコレクション(コンポーネント アーキタイプで構成されています)も付属しています。
独自データでモデルを構築、トレーニング、デプロイするようにパイプライン テンプレートを構成できます。また、スキーマ推測、データ検証、モデル評価、モデル分析を自動的に実施でき、トレーニングされたモデルを AI Platform Prediction サービスに自動的にデプロイできます。
AI Platform Pipelines ベータ版で ML パイプラインを実行する際は、SDK を以下のように選択することをおすすめします。
TFX SDK とそのテンプレート: TensorFlow に基づいた E2E ML Pipelines の場合(カスタマイズ可能なデータの前処理やトレーニング コードを使用します)。
Kubeflow Pipelines SDK: 完全なカスタム パイプラインの場合や、さまざまな GCP サービスへのアクセスに対応した事前構築済みの KFP コンポーネントを使用するパイプラインの場合。
メタデータ ストアと MLMD
AI Platform Pipelines の実行には、ML Metadata(MLMD)を使用した自動メタデータ トラッキングが含まれます。MLMD は、ML デベロッパーやデータ サイエンティストのワークフローに関連付けられたメタデータを記録、取得するためのライブラリです。TensorFlow Extended(TFX)の一部ですが、別々に使用することもできます。
自動メタデータ トラッキングは、各パイプライン ステップで使用されるアーティファクト、パイプライン パラメータ、入出力アーティファクト間のリンク、それらを作成、使用したパイプライン ステップを記録します。
Pipelines の新機能
AI Platform Pipelines のベータ版には、テンプレート ベースのパイプライン構築、バージョニング、自動アーティファクト、リネージ トラッキングのサポートなど、多くの新機能が含まれています。
TFX テンプレートで独自の ML パイプラインを構築する
デベロッパーが ML パイプライン コードの使用を開始しやすくなるように、TFX SDK では、テンプレート(スキャフォールディング)とともに、独自データの本番環境 ML パイプラインを構築するための手順を示したガイドが提供されます。TFX テンプレートを使用すると、さまざまなコンポーネントを徐々にパイプラインに追加して繰り返すことができます。
TFX テンプレートには、Cloud Console の AI Platform Pipelines の [スタートガイド] ページからアクセスできます。TFX SDK では現在、分類問題タイプのテンプレートが提供されていて、TensorFlow 向けに最適化されています。今後、さまざまなユースケースや問題タイプに対応したテンプレートが追加される予定です。
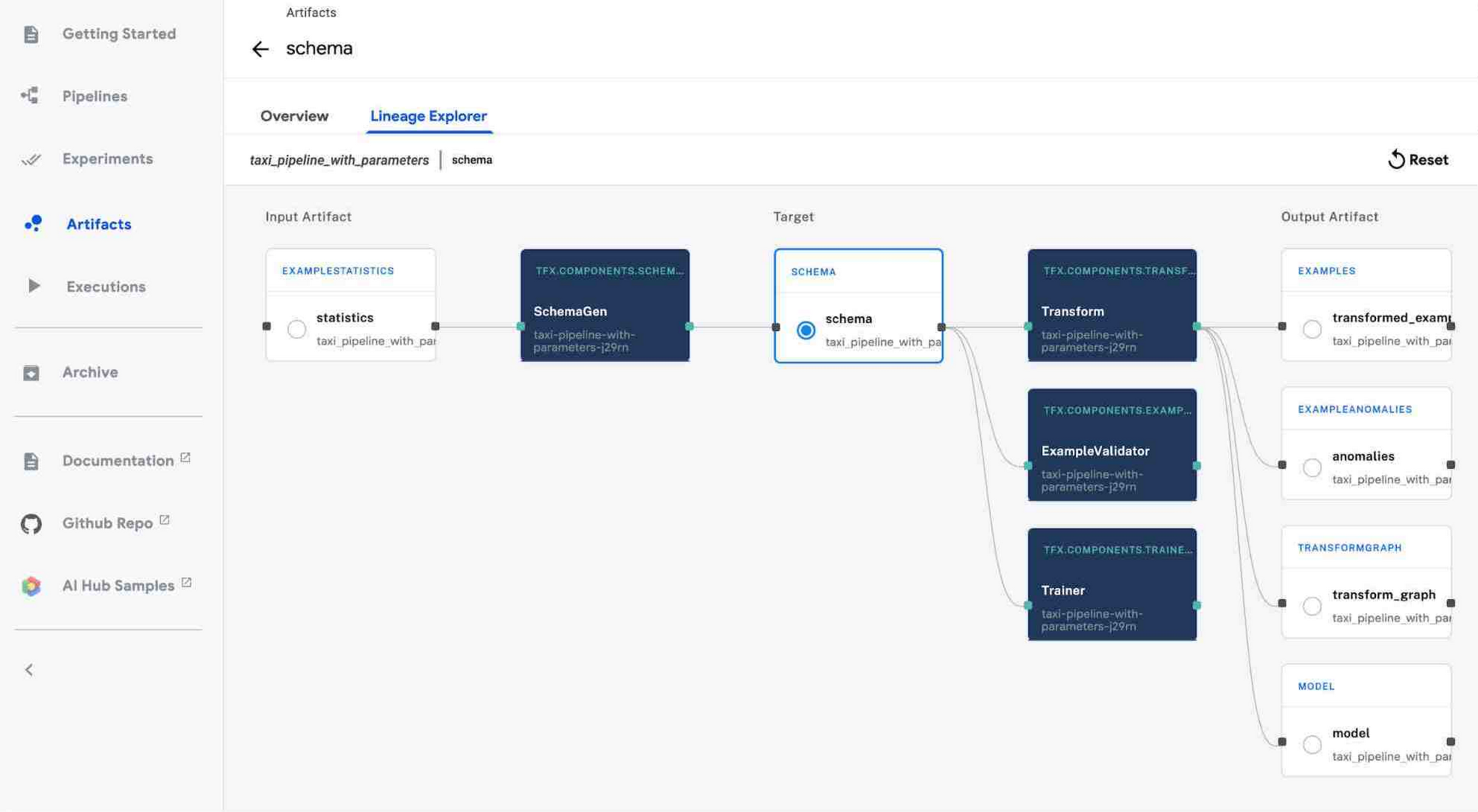
TFX パイプラインは通常、ML ワークフローのすべてのステップ向けに事前作成された複数のコンポーネントで構成されています。たとえば、データの取り込みに ExampleGen、データ統計の生成と可視化に StatisticsGen、データの検証に ExampleValidator と SchemaGen、データの前処理に Transform、TensorFlow モデルのトレーニングに Trainer を使用できます。AI Platform Pipelines UI を使用すると、パイプライン内のさまざまなコンポーネントの状態や、データセットの統計などを以下のように可視化できます。
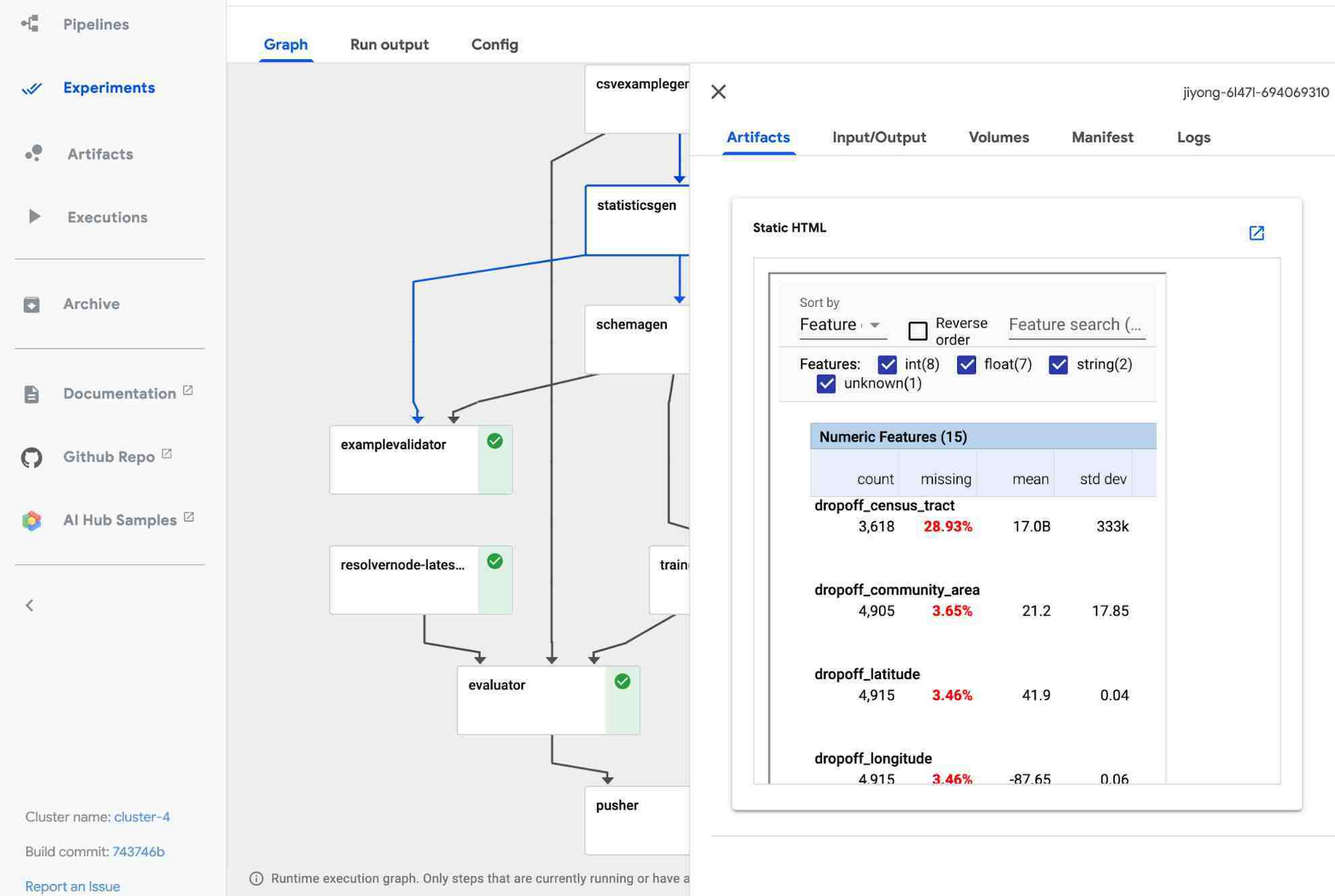
パイプラインのバージョニング
AI Platform Pipelines ではパイプラインのバージョニングがサポートされています。同じパイプラインの複数のバージョンをアップロードして UI でグループ化できるため、意味的に関連するワークフローをまとめて管理できます。
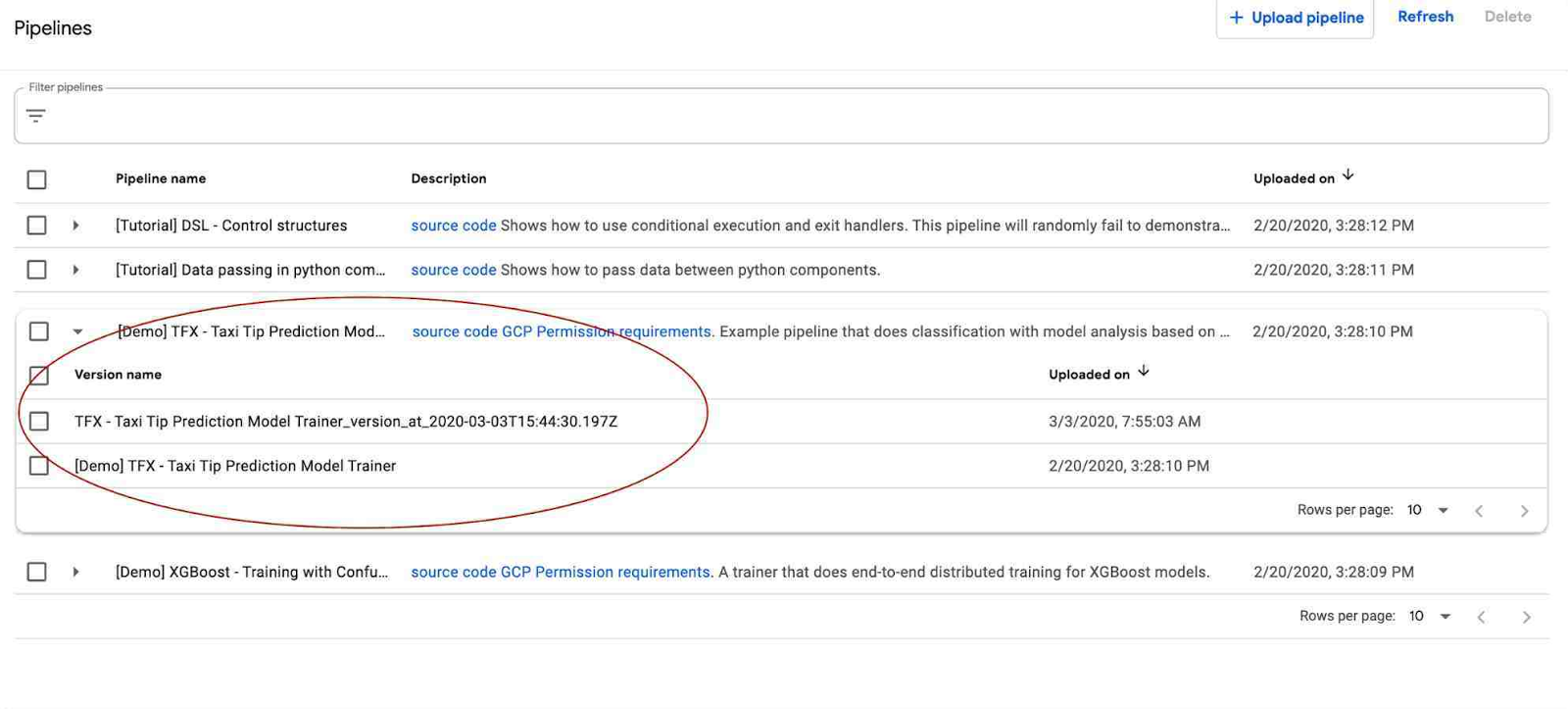
アーティファクトとリネージのトラッキング
AI Platform Pipelines ではアーティファクトとリネージの自動トラッキングがサポートされています。このトラッキングは、ML Metadata を利用して UI でレンダリングされます。
アーティファクトのトラッキング: ML ワークフローには通常、複数のタイプのアーティファクト(モデル、データ統計、モデル評価指標など)の作成やトラッキングが含まれます。AI Platform Pipelines UI を使用すると、ML パイプラインのアーティファクトを簡単に追跡できます。
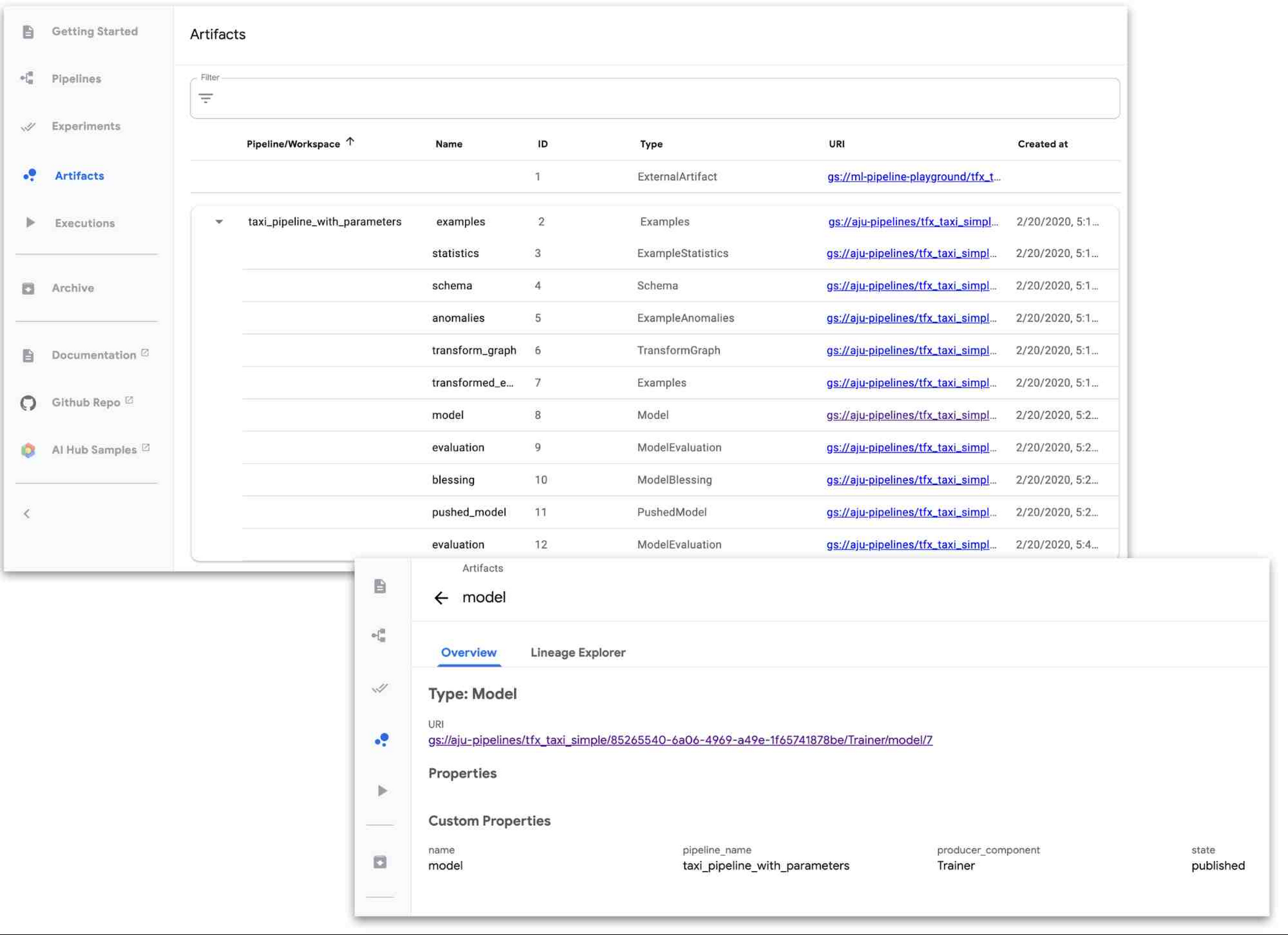
リネージのトラッキング: バージョン管理をせずにコーディングをしないように、リネージのトラッキングをせずにモデルをトレーニングすべきではありません。リネージのトラッキングでは、モデルやデータなどの履歴とバージョンが表示されます。ML スタック トレースのようなものと考えることができます。リネージのトラッキングは次のような質問に回答できます。このモデルはどのデータでトレーニングされたか?このデータセットからどの
モデルがトレーニングされたか?このモデルはどのデータ統計でトレーニングされたか?
その他の改善点
Kubeflow Pipelines SDK の最近のリリースでは、これ以外にも多くの改善が行われています。注目に値するのは、Python 関数からパイプライン コンポーネントを構築するためのサポートが改善された点と、コンポーネントの
入出力指定が容易になった点です。たとえば、パイプラインのステップ間で大規模なデータセットを簡単に共有できます。
スタートガイド
使用を開始するには、Google Cloud Console にアクセスし、[AI Platform] > [パイプライン] に移動して、[新しいインスタンス] をクリックします。既存の GKE クラスタを使用するか、インストール プロセスの一環として新しいクラスタを作成するかを選択できます。新しいクラスタを作成する場合は、パイプラインから Cloud Platform サービスへのアクセスを許可するチェックボックスをオンにすることができます(そうしない場合は、追加の手順でアクセス権をさらに細かく指定できます。デモ パイプラインと TFX テンプレートには、Dataflow、AI Platform、Cloud Storage へのアクセスが必要です)。
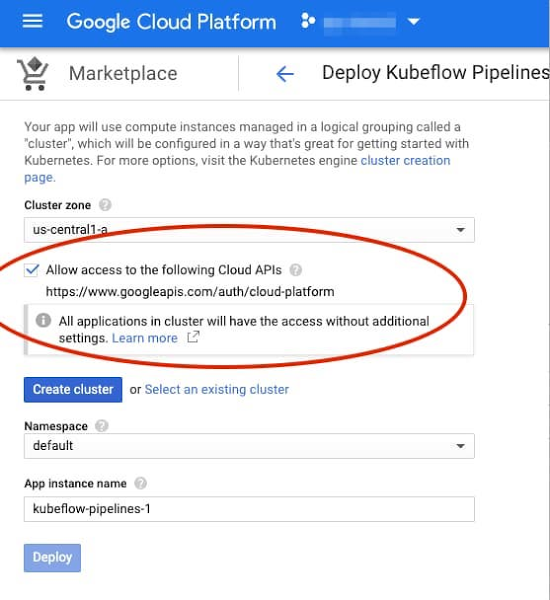
詳しくは手順をご覧ください。
コマンドラインを使用して Kubeflow Pipelines を GKE クラスタにデプロイする場合、そのデプロイには Cloud Console の [AI Platform] > [パイプライン] からもアクセスできます。
AI Platform Pipelines クラスタが稼働したら、[パイプライン ダッシュボードを開く] リンクをクリックします。そこから、[スタートガイド] ページを確認するか、左側のナビゲーション バーの [パイプライン] をクリックして、いずれかのサンプルを実行できます。<名前を追加> パイプラインは、上記の ML パイプライン テンプレートを使用して構築された例を示しています。独自のパイプラインのいずれかを構築、アップロード、実行することもできます。
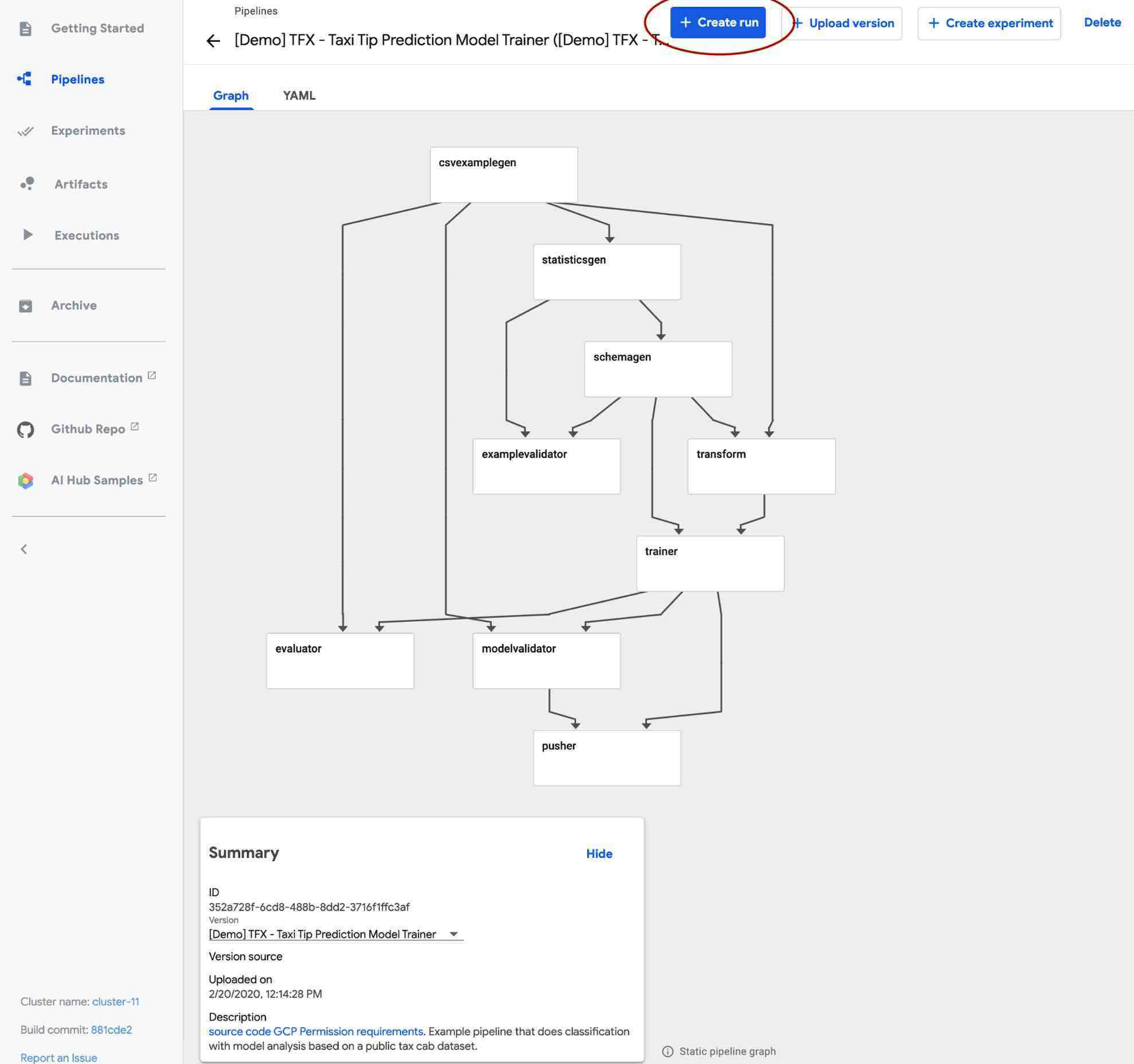
パイプラインの実行時や終了後に、ランタイム グラフ、ログ、出力の可視化、アーティファクト、実行情報などを表示できます。詳しくはドキュメントをご覧ください。
今後の予定
以下のサポートを含む、いくつかの新しいパイプライン機能が近日中に提供されます。
マルチユーザー分離: パイプラインやその他のリソースにアクセスできるユーザーを、Pipelines クラスタにアクセスする各ユーザーが制御できるようにします。
Workload Identity: GCP サービスへの透過的なアクセスをサポートします。
バックエンド データ(メタデータ、サーバーデータ、ジョブ履歴、指標など)のクラスタ外ストレージの簡単な UI ベース設定: 大規模なデプロイメントが可能になり、クラスタのシャットダウン後も持続できるようになります。
簡単なクラスタ アップグレード
ML ワークフローを作成するための他のテンプレート
AI Platform Pipelines の使用を開始するには、インストールに含まれるサンプル パイプラインの一部をお試しになるか、パイプライン ダッシュボードの [スタートガイド] ランディング ページをご確認ください。上記のノートブックには、KFP SDK を使用して作成されたパイプラインのサンプルも多数含まれています。
-By TFX 部門プロダクト マネージャー Anusha Ramesh、スタッフ デベロッパー アドボケイト Amy Unruh



