Google Cloud Speech-to-Text で FFmpeg を使用する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 11 月 7 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud Speech-to-Text は、リアルタイムで音声を文字に変換するフルマネージド サービスです。音声ファイルや動画ファイルの文字起こし、動画字幕の作成、音声起動型アプリケーションの構築に使用できます。
このサービスは WAV、MP3、AAC などの幅広い音声形式に対応しています。英語、スペイン語、フランス語、ドイツ語、日本語など、さまざまな言語で音声を文字起こしすることもできます。
Google Cloud Speech-to-Text は使いやすいソリューションで、音声ファイルをアップロードするだけで自動的にテキストに変換されます。通話や会議などのライブ音声を文字起こしすることもできます。Speech-to-Text には、V1 のサンプルと V2 のサンプルが用意されています。
問題
ただし、入力音声エンコードが STT API でサポートされていない場合はどうすればよいでしょうか。
サポートされている音声エンコードについては、https://cloud.google.com/speech-to-text/docs/encoding をご覧ください。
幸い、エンコード変換を支援するサードパーティ製ツールは多数あります。
FFmpeg は、音声と動画のデータを処理する一般的なマルチメディア フレームワークで、音声と動画のコンテンツのエンコード、デコード、コード変換、ストリーミングに使用できます。このブログ投稿では、さまざまなシナリオで FFmpeg を利用して、STT API を呼び出すために適切なエンコードを取得する方法を紹介します。
- コマンドラインからローカルで実行する
- Python プログラムを通じて呼び出す
- GCP Buildpacks と FFmpeg を使用してコンテナ イメージをビルドする
- Vertex AI Workbench から実行する
コマンドラインからローカルで実行する
https://www.ffmpeg.org/download.html から FFmpeg ソフトウェアをダウンロードしてインストールします。
「acelp.kelvin」でエンコードされたサンプル入力音声ソースを取得します。このエンコードは STT API ではサポートされていません。
音声ソースのエンコード方式を確認するには、ffmpeg -i input.wav を実行します。次のとおり、出力にエンコードが表示されます。
以下のコマンドを実行してエンコードを「pcm_s16le」に変更します。
ffmpeg -i outpt.wav コマンドの出力は、ファイルのエンコードが変更され、ファイルを STT API に渡す準備が整ったことを示しています。
ffmpeg オプションの一覧については、http://ffmpeg.org/documentation.html をご覧ください。
Python プログラムを通じて呼び出す
FFmpeg のバージョンを requirements.txt ファイルに記入し、pip install -r requirements.txt を実行します。
以下の Python コード スニペットでは入力ファイルを受け取り、出力音声が pcm_s16le でエンコードされます。
入力ファイルはマシンのローカルに置くことも、GCS バケットに保存することも可能です。ファイルを GCS バケットに保存した場合、まず FFmpeg ソフトウェアが実行されているマシンにファイルをダウンロードし、エンコードが変更された後に再アップロードする必要があります。
GCP Buildpacks と FFmpeg を使用してコンテナ イメージをビルドする
Google Cloud の Buildpacks はアプリケーションのソースコードを、本番環境に対応したコンテナ イメージに変換します。Buildpacks ではデフォルトのビルダーが使用されますが、実行イメージをカスタマイズして、サービスのビルドに必要なパッケージを追加することもできます。
1.1. Dockerfile を作成する
最初のステップは、Dockerfile(builder.Dockerfile)の作成です。このファイルには、FFmpeg のベースイメージをビルドする方法を記述します。
この Dockerfile では、デフォルトの「gcr.io/buildpacks/builder」イメージがベースイメージとして使用されます。次に、apt-get コマンドにより、FFmpeg パッケージがインストールされます。
1.2. コンテナ イメージをビルドする
Dockerfile を作成したら、次のコマンドを使用してコンテナ イメージをビルドできます。
1.3. コンテナ イメージを push する
FFmpeg のベースイメージをビルドしたら、次のコマンドを使用して実行できます。
FFmpeg ソフトウェアを使用して、イメージの準備が整いました。Buildpacks の代わりに任意のイメージを使用して、標準のコンテナ ビルドプロセスに従って FFmpeg を含めることができます。
Vertex AI Workbench から実行する(Ubuntu)
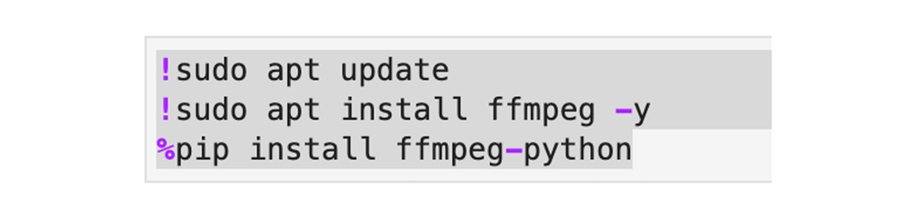
Vertex Jupyter Workbench での実行は、Python プログラムをローカルで実行する方法と同様です。Jupyter ノートブックから sudo を使用して FFmpeg をインストールすると、上記の Python コード スニペットをそのまま実行できます。FFmpeg のインストール コマンドは、ノートブックの環境によって異なる場合があります。
まとめ
エンコード変換のプロセスは非常にシンプルです。変換プロセスに選択するプラットフォームは、音声ファイルの数とサイズ、および必要な変換量によって決まります。少数のファイルを変換するには、コマンドラインを使用するか、Python プログラムをローカルで実行します。このタスクを繰り返す場合、イメージをビルドし、Cloud Run などのサーバーレス プラットフォームを使用するのが最適です。Vertex Workbench では、特に並列処理が必要な場合、サイズが増大する音声ファイルの処理効率が向上します。
FFmpeg では、音声ファイルがソフトウェアと同じロケーションにあることが求められるため、大きな音声ファイルを処理する場合、特に音声ファイルが GCS バケットに保存されている場合にパフォーマンスの問題につながる可能性があります。この問題を回避するには、GCP 上で、音声ファイルが保存されている GCS バケットと同じリージョン内にある処理プラットフォームを選択することをおすすめします。リージョン間でデータを転送する必要がなくなるため、ファイル処理にかかる時間が短縮されます。
Speech-to-Text API の使用を開始するには、詳細なドキュメントを参照し、チュートリアルをお試しください。
ー Anita Gutta



