Vertex AI の Reduction Server を使用して PyTorch トレーニングのパフォーマンスを最適化する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 3 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
ディープ ラーニング モデルがますます複雑になり、データセットが大規模になるにつれて、分散トレーニングが必要不可欠になっています。トレーニングのスピードが上がれば、モデリングの目標を達成するための反復をより速く行えるようになります。しかし、分散トレーニングには特有の課題が伴います。
どのような分散戦略を使用するのかを決定し、トレーニング コードを変更しなければなりません。加えて、インフラストラクチャの管理や、アクセラレータの使用量の最適化をどのように行うか、ノード間の帯域幅の制限にどのように対処するかを策定する必要もあります。こうした問題によってプロジェクトが複雑化し、思うように進行できなくなることは珍しくありません。
今回の投稿では、Reduction Server を使用して PyTorch + Hugging Face モデルのトレーニングを高速化する方法をご紹介します。Reduction Server は、同期データ並列型アルゴリズムにあわせて、NVIDIA GPU でのマルチノード分散トレーニングの帯域幅とレイテンシを最適化する Vertex AI の機能です。
分散データ並列型の概要
Reduction Server の詳細や、Vertex AI Training サービスでのジョブの送信方法に触れる前に、分散データ並列処理の基本を理解しておきましょう。データ並列処理は分散トレーニングを実行する方法の一つであり、1 台のマシンに複数のアクセラレータを搭載している場合や、複数のマシンにそれぞれ複数のアクセラレータを搭載している場合に使用できます。
データ並列処理の仕組みを理解するために、まずは線形モデルから見ていきましょう。このモデルは、計算グラフの観点から考えることが可能です。次の図で、matmul op は X と W のテンソルを受け取ります。それぞれトレーニング バッチと重みです。結果のテンソルが、モデルのバイアス項であるテンソル b とともに add op に渡されます。この op の結果は Ypred であり、これがモデルの予測値となります。
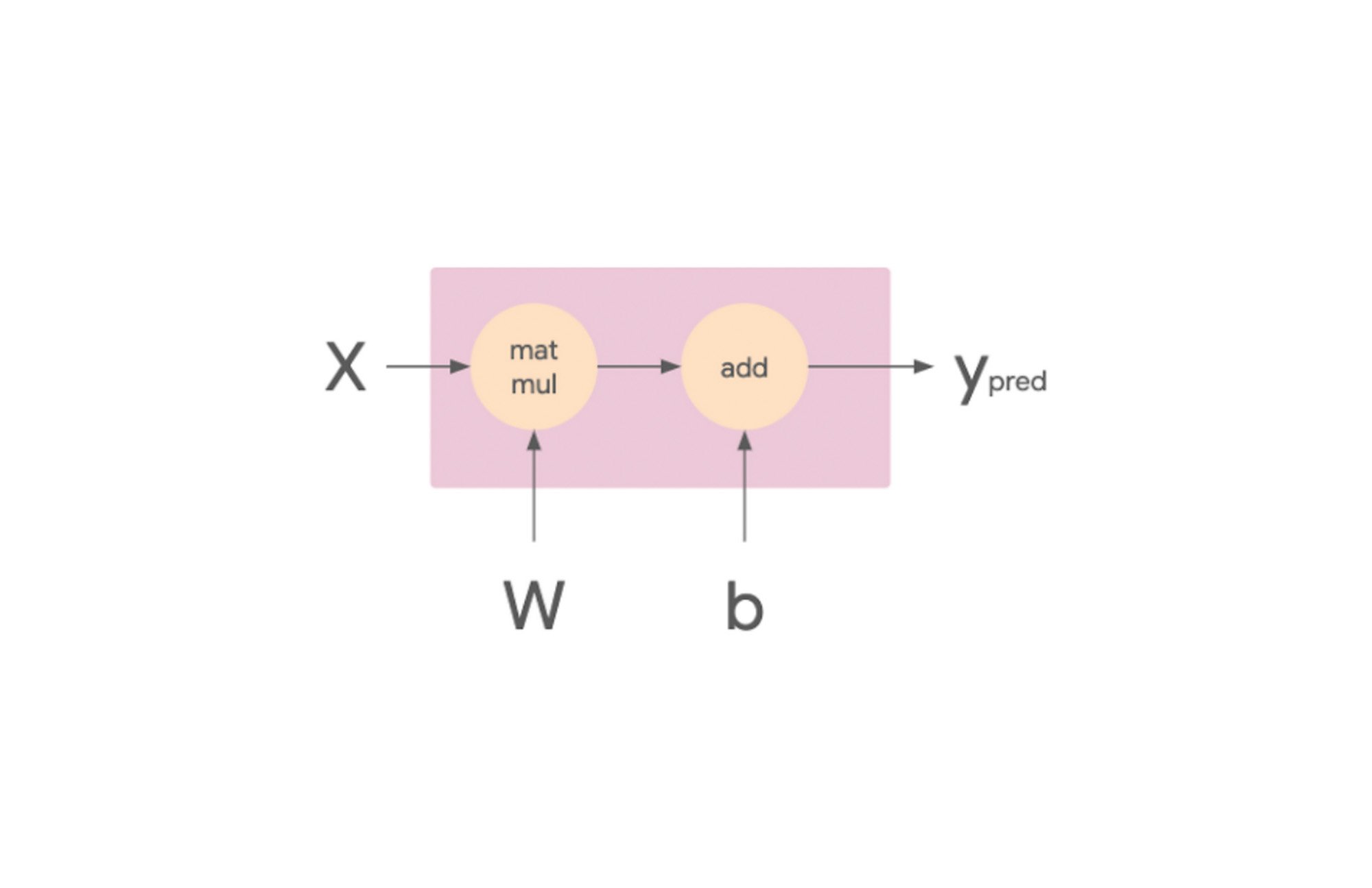
この計算グラフを、複数のワーカーを活用できる手法で実行したいと思います。この方法の一つとして、入力バッチ X を半分に分割し、片方のスライスを GPU 0 に、もう一方を GPU 1 に送信するというやり方があります。この場合、各 GPU ワーカーは同じ op を、データの異なるスライスに対して計算します。
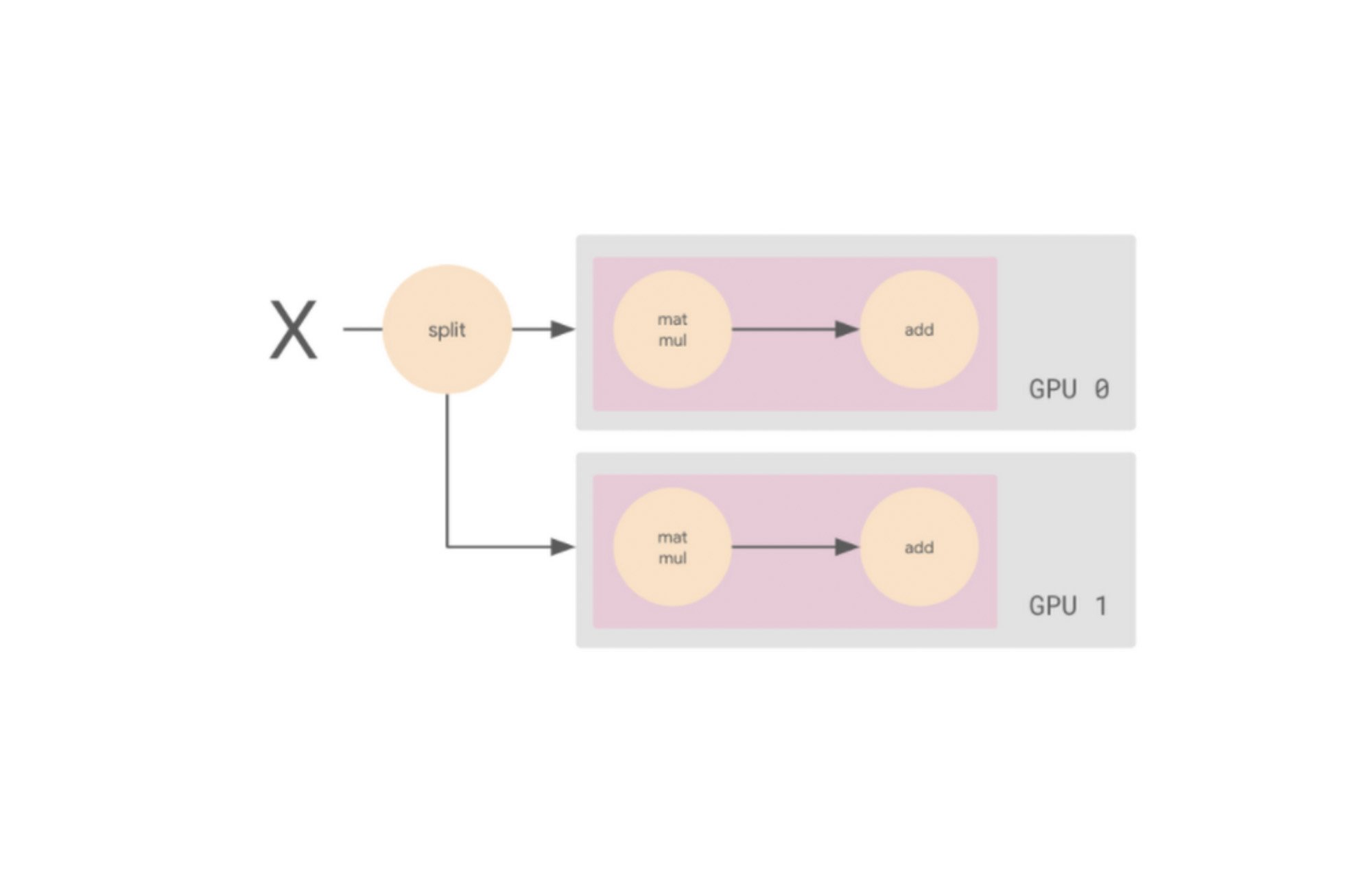
このワーカーを追加することで、バッチサイズを 2 倍にできます。各 GPU は個別のデータスライスを取得し、勾配を計算して、これらの勾配を平均化します。つまり、GPU を 2 つ使用するとバッチサイズは 64 になり、GPU を 4 つ使用するとバッチサイズは 128 になります。GPU が多いほど、各トレーニング ステップでモデルが参照できるデータも増え、1 エポック(トレーニング データをひととおり処理すること)にかかる時間が短くなります。これがデータ並列処理の核となる考え方です。
実はここに重要なポイントがあります。もう少し細かい視点で考えてみましょう。両方のワーカーが異なるデータスライスの勾配を計算する場合、両者は異なる勾配を計算します。つまり、バックワード パスの最後に 2 つの異なる勾配のセットができるということです。
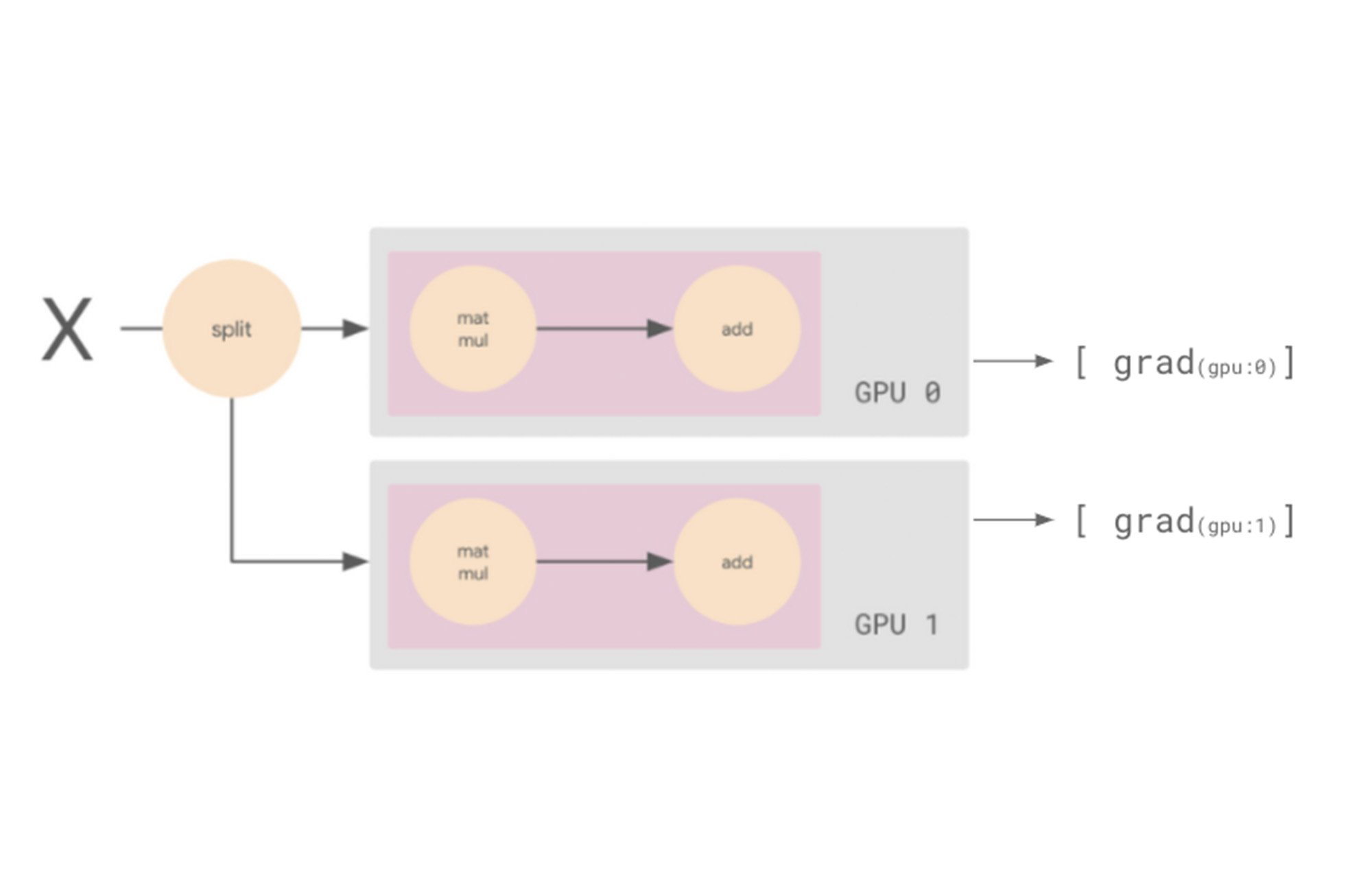
同期データ並列トレーニングを行う場合は、これらの複数の勾配セットを 1 つに変換する必要があります。これを行うには、AllReduce というプロセスで勾配を平均化し、この平均化された勾配を使用してオプティマイザを更新します。
平均を計算するために、各ワーカーは他のすべてのワーカーが計算した勾配の値を知る必要があります。ここで大切なのは、ノード間でこの情報をできるだけ効率的に渡すこと、使用する帯域幅をなるべく抑えることです。この集約を効率的に実装するためのアルゴリズムとして、Ring AllReduce や、他のツリーベースのアルゴリズムなど、さまざまなものが存在します。Vertex AI では、同期データ並列型アルゴリズムにあわせて、NVIDIA GPU 上のマルチノード分散トレーニングの帯域幅とレイテンシを最適化する Reduction Server を使用できます。
要約すると、分散データ並列型設定は以下のように動作します。
各ワーカー デバイスは、入力データの別のスライスに対してフォワードパスを実行して、損失を計算します。
各ワーカー デバイスは、損失関数に基づいて勾配を計算します。
これらの勾配は、すべてのデバイス全体で集約(リダクション)されます。
最適化アルゴリズムがリダクションされた勾配を使用して重みを更新し、デバイスの同期状態を維持します。
Vertex AI Reduction Server
なお、データの並列処理は、単一マシン上の複数のデバイスで行うトレーニングも、クラスタ内の複数のマシンで行うトレーニングも高速化できますが、Reduction Server は後者の場合に特化して機能します。
Vertex Reduction Server には、追加のワーカーロールであるレデューサが導入されています。レデューサが提供するのは、ワーカーからの勾配の集約という 1 つの機能だけです。また、機能が限られているため、レデューサは多くの計算能力を必要とせず、比較的低コストなコンピューティング ノードでも実行できます。
次の図は、4 つの GPU ワーカーと 5 つのレデューサを持つクラスタを示しています。GPU ワーカーはモデルのレプリカを維持して、勾配を計算し、パラメータを更新します。レデューサは GPU ワーカーから勾配のブロックを受信して、ブロックをリダクションし、リダクションされたブロックを GPU ワーカーに対して再分配します。
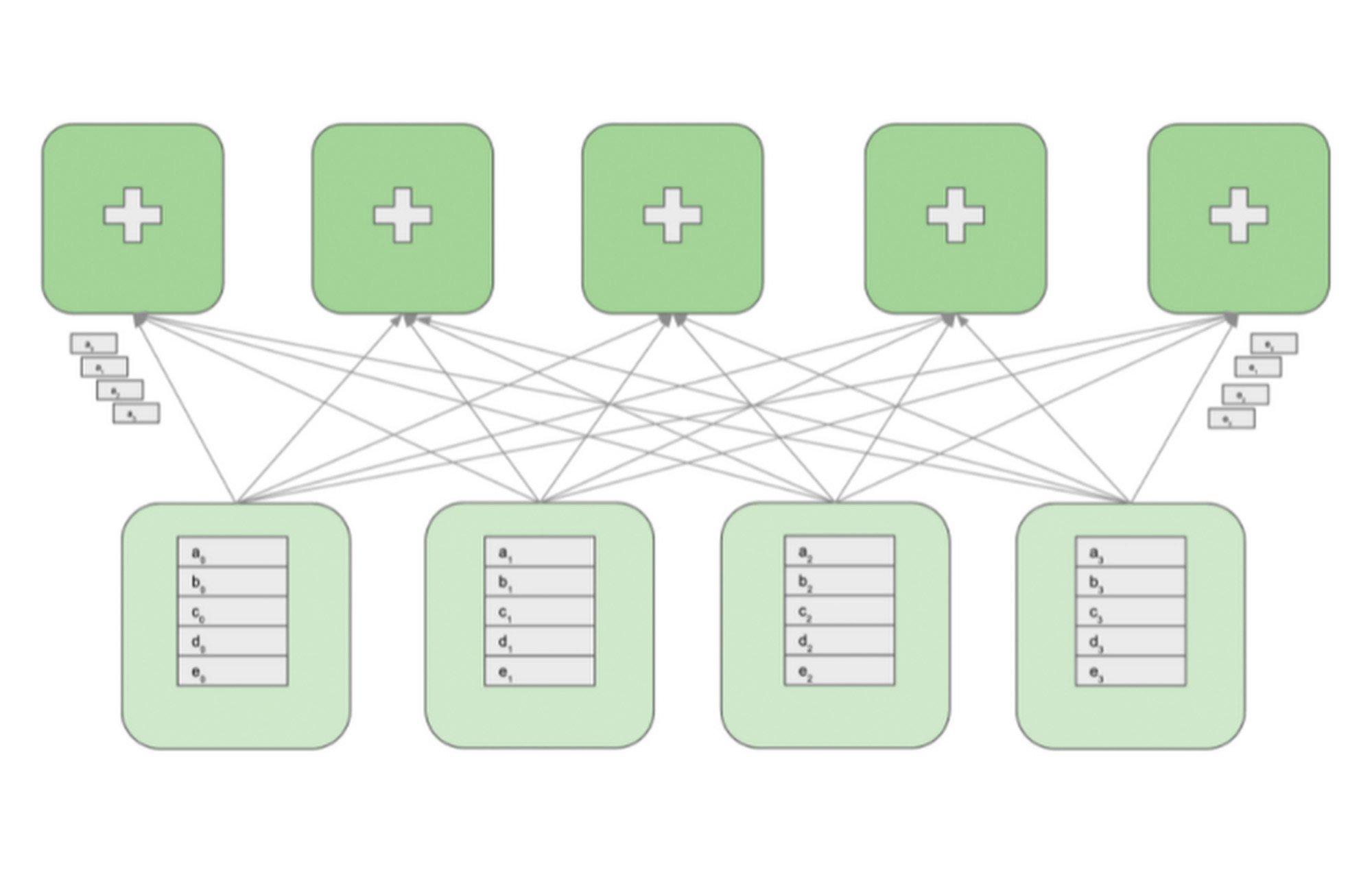
all-reduce オペレーションを実行するために、各 GPU ワーカーの勾配配列は最初に M 個のブロックにパーティショニングされます。M はレデューサの数です。特定のレデューサは、すべての GPU ワーカーから送られてくる、勾配の同じパーティションを処理します。例として上の図では、最初のレデューサは a0 から a3 までのブロックをリダクションし、2 番目のレデューサは b0 から b3 までのブロックをリダクションします。受信したブロックをリダクションした後、レデューサはリダクションされたパーティションをすべての GPU ワーカーに送り返します。
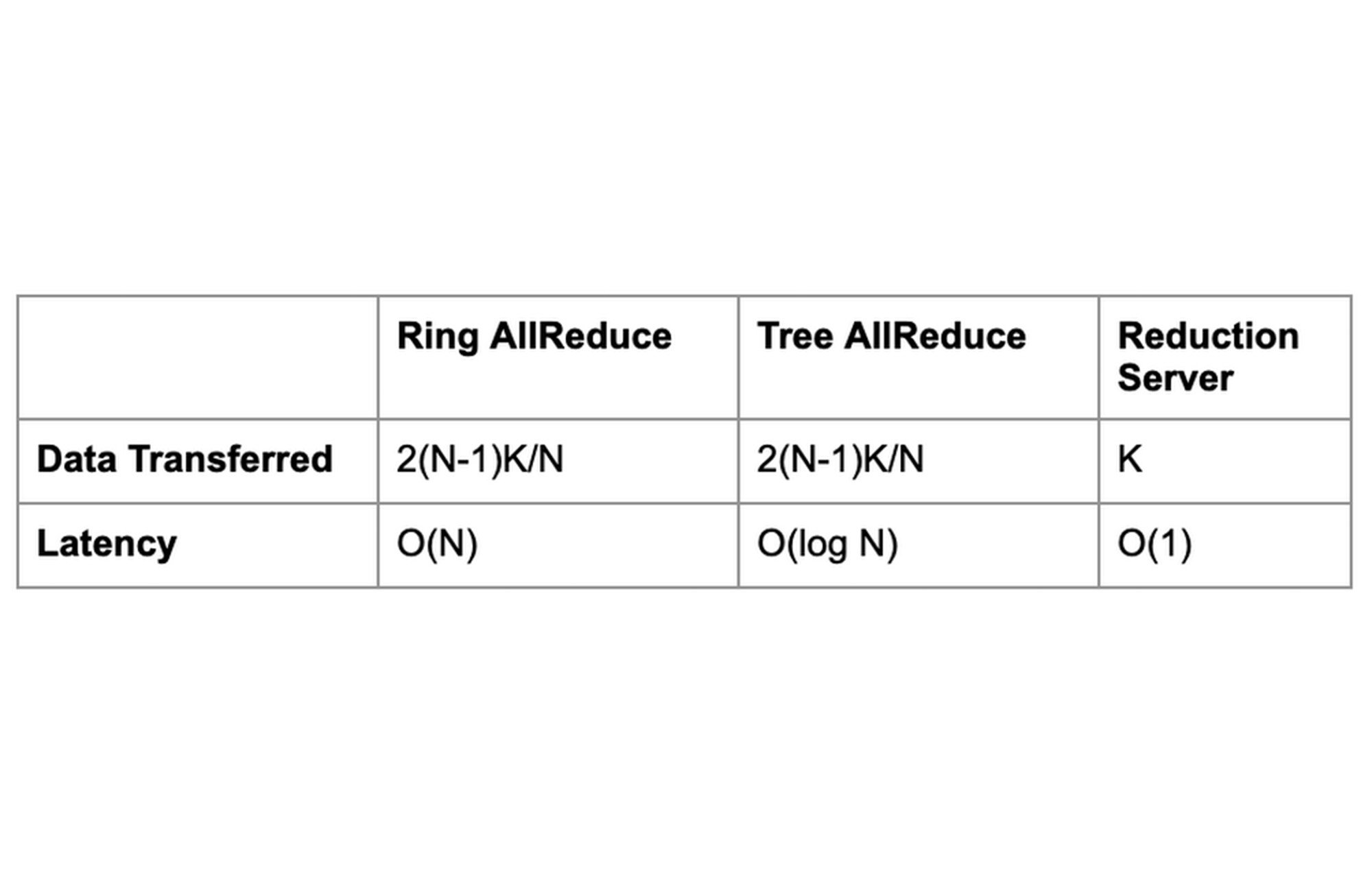
勾配配列のサイズが K バイトの場合、トポロジの各ノードは K バイトのデータを送受信します。これは、リングおよびツリーベースの all-reduce 実装で交換されるデータのおよそ半分です。また、レイテンシがワーカーの数に依存しないことも Reduction Server の利点の一つです。
PyTorch での Reduction Server の使用
Reduction Server は、all-reduce 集団オペレーションに対して NVIDIA NCCL ライブラリを使用する分散トレーニング フレームワークとともに使用できます。トレーニング アプリケーションを変更または再コンパイルする必要はありません。
PyTorch の場合、DistributedDataParallel(DDP)または FullyShardedDataParallel(FSDP)という分散トレーニング戦略を使用できます。Reduction Server を利用するには、PyTorch トレーニング コードに必要な変更を加えた後、次のようにします。
トレーニング コンテナ イメージに、Reduction Server NVIDIA NCCL トランスポート プラグインをインストールします。
Reduction Server ワーカープールを含む Vertex AI Training のカスタムジョブを構成します。
Reduction Server NVIDIA NCCL トランスポート プラグインのインストール
Reduction Server は、NVIDIA NCCL トランスポート プラグインとして実装されます。このプラグインは、トレーニング アプリケーションを実行するために使用するコンテナ イメージにインストールする必要があります。このプラグインは、Vertex AI のビルド済みトレーニング コンテナに含まれています。
また、Dockerfile に以下を含めることで、自分でプラグインをインストールすることも可能です。
トレーニング ジョブの構成と送信
Vertex AI は、分散トレーニングを行う際に発生するさまざまなタイプのマシンタスクに対応するため、最大 4 つのワーカープールを提供します。ワーカーは単一のマシンと見なすことができます。また、各ワーカープールは、類似するタスクを実行するマシンの集合です。
ワーカープール 0 は、プライマリ、チーフ、スケジューラ、または「マスター」を構成します。このワーカーは通常、チェックポイントの保存やサマリー ファイルの書き込みなど、いくつかの追加の作業を引き受けます。クラスタにチーフワーカーは 1 つしかないので、ワーカープール 0 のワーカー数は必ず 1 になります。
ワーカープール 1 で、クラスタの残りのワーカーを構成します。
ワーカープール 2 は、Reduction Server のレデューサを管理します。レデューサの数と種類を選択する際に、レデューサ レプリカのマシンタイプでサポートされているネットワーク帯域幅を考慮する必要があります。Google Cloud では、VM のマシンタイプによって最大の下り(外向き)帯域幅が決まります。たとえば、n1-highcpu-16 マシンタイプの下り(外向き)帯域幅は、32 Gbps に制限されています。
まず、ジョブを定義します。次の例では、コードが Python ソース ディストリビューションとして構造化されていることを前提としていますが、カスタム コンテナも同様に機能します。
ジョブを定義したら、run を呼び出して、Reduction Server レデューサを含むクラスタ構成を指定できます。
上記の run 構成では、合計 7 台のマシンを含むクラスタが指定されています。
1 つのチーフワーカー
2 つの追加ワーカー
4 つのレデューサ
レデューサは、Vertex AI が提供する Reduction Server コンテナ イメージを実行する必要があります。
サンプルコードを確認したい場合は、こちらのノートブックをご覧ください。
パフォーマンス上のメリットの分析
通常、Reduction Server の効果が最大化するのは、トレーニング モデルに大量のパラメータが含まれていて、妥当な時間内にトレーニングを完了するために多数の GPU を必要とする、計算負荷が高いワークロードになります。これは、標準のリングおよびツリーベースの all-reduce 集団オペレーションのレイテンシが、GPU ワーカーの数と勾配配列のサイズに比例するためです。Reduction Server ではその両方を最適化します。レイテンシは GPU ワーカーの数に依存せず、all-reduce オペレーション中に転送されるデータの量は、リングおよびツリーベースの実装よりも少なくなります。
このカテゴリに属するワークロードの例として、BERT などの言語モデルの事前トレーニングと微調整が挙げられます。予備実験では、この種類のワークロードの場合、トレーニング時間は 30% 以上減少することが確認されています。
次の図は、マルチノードおよびマルチ処理環境で Reduction Server を使用した場合と使用しない場合とで、PyTorch 分散トレーニング ジョブのトレーニング パフォーマンスを比較したものです。ジョブの内容は、感情分類のために imdb データセットの Hugging Face から事前トレーニングされた BERT 大規模モデル bert-large-cased を微調整することでした。
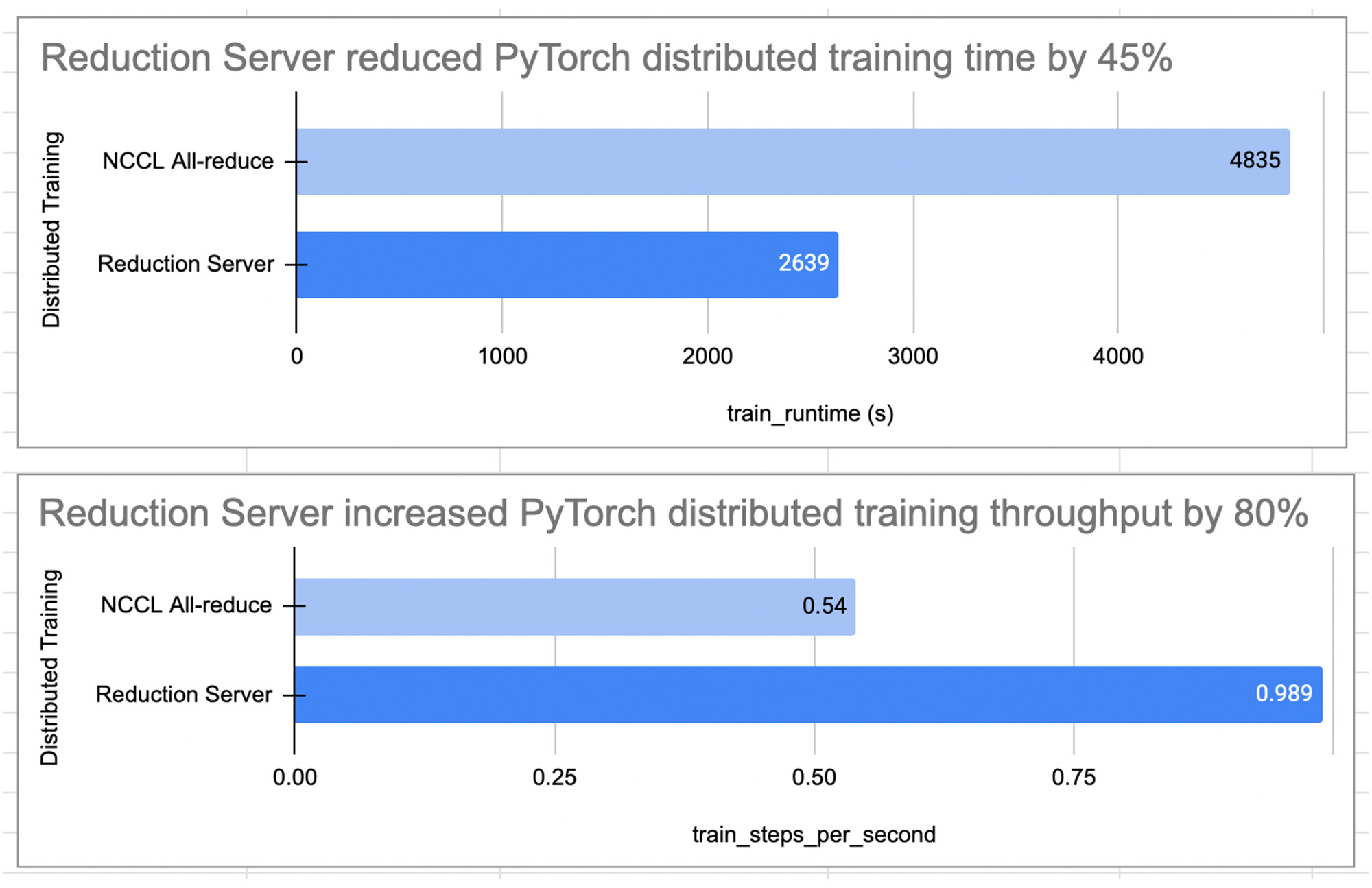
この実験では、Reduction Server によってトレーニングのスループットが 80% 向上し、トレーニング時間、ひいてはトレーニング費用が 45% 以上削減されることを確認できました。
このベンチマーク結果から、GPU 上での PyTorch 分散トレーニングを最適化するのに Reduction Server が有効であることがわかります。ただし、Reduction Server を使用することでトレーニング時間やスループットに実際にどのような効果があるかは、個々のトレーニング ワークロードの特性によって異なるという点にも留意しましょう。
次のステップ
この記事では、勾配集約に特化した特別なワーカータイプを使用することによってレイテンシと転送データを最小化する、AllReduce の実装を提供する Vertex AI Reduction Server アーキテクチャについて説明しました。実際の例で最初から最後まで試してみたい方は、こちらのノートブックをご覧ください。また、Vertex AI での PyTorch 分散トレーニングについてさらに詳しく知りたい場合は、こちらの動画をご覧ください。
Reduction Server を使用して、ぜひご自身でテストしてみてください。
- デベロッパー アドボケイト、Nikita Namjoshi
- デベロッパー プログラム エンジニア、Eric Dong




