GKE 上の GPU で LLM のサービング スループットを最適化する - 実践ガイド
Ashok Chandrasekar
Software Engineer
Anna Pendleton
Software Engineer
※この投稿は米国時間 2024 年 8 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
残念ながら、大規模言語モデル(LLM)などの AI 基盤モデルのサービングには多額のコストがかかる場合があります。低レイテンシを実現するためにハードウェア アクセラレータが必要であり、これらのアクセラレータを効率的に利用していない組織が多いため、トークンあたりのコストを最小限に抑えながら、LLM を大規模にサービングできる AI プラットフォームが必要とされています。Google Kubernetes Engine(GKE)は、ワークロードとインフラストラクチャの自動スケーリングやロード バランシングなどの機能によって、この要件を満たします。
LLM をアプリケーションに統合する場合は、一定のレイテンシ制限内で最大限のスループットを提供しながら、LLM を優れた費用対効果でサービングする方法を検討する必要があります。Google は、お客様を支援するため、クラスタの作成から推論サーバーのデプロイとベンチマークまで、エンドツーエンドの設定を自動化する GKE 用のパフォーマンス ベンチマーク ツールを開発しました。このツールを使用して、このようなパフォーマンスのトレードオフを測定および分析できます。
以下は、GKE 上の NVIDIA GPU のサービング スループットを最大化するための推奨事項です。これらの推奨事項をパフォーマンス ベンチマーク ツールと組み合わせることで、GKE で推論スタックを設定する際にデータドリブンな意思決定を行うことができます。また、特定の推論ワークロードに対してモデルサーバー プラットフォームを最適化する方法についても説明します。
インフラストラクチャに関する決定
モデルに適合し、費用対効果に優れたインフラストラクチャを選択するには、以下の事項を確認する必要があります。
-
モデルの量子化が必要か。必要な場合は、どの量子化を使用すべきか。
-
モデルに適合するマシンタイプをどのように選択するか。
-
どの GPU を使用すべきか。
これらの事項を詳しく見ていきましょう。
1. モデルの量子化が必要か。どの量子化を使用すべきか。
量子化は、モデルの重み付けを読み込むために必要なアクセラレータ メモリの量を削減する手法です。そのために、重みと活性化をより精度の低いデータ型で表します。量子化によってメモリ使用量が削減されるため、コストが低下し、レイテンシとスループットが改善されます。しかし、ある時点で、モデルの量子化によってモデルの精度が著しく低下します。
量子化には複数の種類がありますが、FP16 および Bfloat16 量子化は、半分のメモリ使用量で FP32 とほぼ同じ精度を実現します(こちらのペーパーで示されているようにモデルによって差があります)。新しいモデル チェックポイントのほとんどは、すでに 16 ビット適合率で公開されています。FP8 と INT8 は、モデルの重み付けに対するメモリ使用量を最大 50% 削減できます(KV キャッシュのメモリ使用量は、モデルサーバーによって個別に量子化されない場合はほぼ同じです)。多くの場合、精度の低下は最小限に抑えられます。
INT4 や INT3 など、4 ビット以下の量子化では精度が低下します。4 ビットの量子化を使用する前に、必ずモデルの精度を評価してください。また、精度の低下軽減に役立つ Activation Aware Quantization(AWQ)のようなトレーニング後の量子化手法もいくつかあります。
Google の自動化ツールを使用して、さまざまな量子化手法で任意のモデルをデプロイし、ニーズとの適合性を評価できます。
推奨事項 1: 量子化を使用して、メモリの使用量とコストを削減します。適合率が 8 ビット未満の場合は、必ず最初にモデルの精度を評価してください。
2. モデルに適合するマシンタイプをどのように選択するか。
必要なマシンタイプを簡単に計算するには、モデルのパラメータ数とモデルの重み付けのデータ型を考慮します。
モデルサイズ(バイト)= モデルのパラメータ数 × データ型(バイト)
つまり、FP16 や BF16 などの 16 ビット適合率の量子化技術を使用する 7b モデルでは以下が必要です。
70 億 × 2 バイト = 140 億バイト = 14 GiB
同様に、FP8 や INT8 などの 8 ビット適合率の 7b モデルでは以下が必要です。
70 億 × 1 バイト = 70 億バイト = 7 GiB
下の表は、これらのガイドラインを適用して、いくつかの一般的なオープンウェイト LLM に必要なアクセラレータ メモリの量を示しています。
注: 上の表はあくまで参考用です。パラメータの正確な数は、モデル名に記載されているパラメータの数(例: Llama 3 8b や Gemma 7b)と異なる場合があります。オープンモデルについては、Hugging Face のモデルカード ページに正確なパラメータ数が記載されています。
メモリの最大 80% をモデルの重み付けに割り当て、KV キャッシュ(効率的なトークン生成のためにモデルサーバーで使用される Key-Value キャッシュ)用に 20% を確保するアクセラレータを選択するのがベスト プラクティスです。たとえば、単一の NVIDIA L4 Tensor Core GPU(24 GB)を搭載した G2 マシンタイプの場合、モデルの重み付けに 19.2 GB(24 × 0.8)を使用できます。トークンの長さと処理されるリクエストの数に応じて、KV キャッシュ用に最大 35% が必要になることがあります。100 万トークンなど、コンテキストが非常に長い場合は、KV キャッシュにより多くのメモリを割り当てる必要があり、それがメモリ使用量の大部分を占めることが予想されます。
推奨事項 2: モデルのメモリ要件に基づいて、NVIDIA GPU を選択します。単一 GPU で十分ではない場合は、テンソル並列処理によるマルチ GPU シャーディングを使用します。
3. どの GPU を使用すべきか。
GKE では、NVIDIA GPU を搭載した幅広い VM が提供されています。モデルのサービングに使用する GPU はどのように決定すればよいでしょうか。
下の表は、推論ワークロードを実行するための一般的な NVIDIA GPU と、そのパフォーマンス特性のリストです。
注: A3 および G2 VM では、パフォーマンスの向上に使用できる構造的スパース性がサポートされています。記載されているのは、スパース性ありの値です。スパース性なしでは、記載されている仕様の値が半分になります。
モデルの特性に基づき、スループットとレイテンシは 3 つの異なるディメンションによって制限される可能性があります。
-
スループットは GPU メモリ(GB / GPU)によって制限される場合があります。GPU メモリには、モデルの重み付けと KV キャッシュが保持されます。一括処理によってスループットは向上しますが、KV キャッシュの増加によって最終的にはメモリ上限に達します。
-
レイテンシは GPU HBM 帯域幅(GB / 秒)によって制限される場合があります。モデルの重み付けと KV キャッシュの状態は、メモリ帯域幅に応じて、生成されるトークンごとに読み取られます。
-
大きなモデルの場合、レイテンシは GPU FLOPS によって制限される場合があります。テンソル計算は GPU FLOPS に依存します。隠れ層とアテンション ヘッドが多いほど、より多くの FLOPS が利用されています。
レイテンシとスループットのニーズに合わせて最適なアクセラレータを選択する場合は、これらのディメンションを考慮してください。
以下は、Llama 2 7b モデルと Llama 2 70b モデルに対する G2 と A3 の $1 あたりのスループットの比較です。このグラフでは、正規化された $1 あたりのスループットが使用されており、G2 のパフォーマンスが 1 に設定され、A3 のパフォーマンスがそれと比較されています。
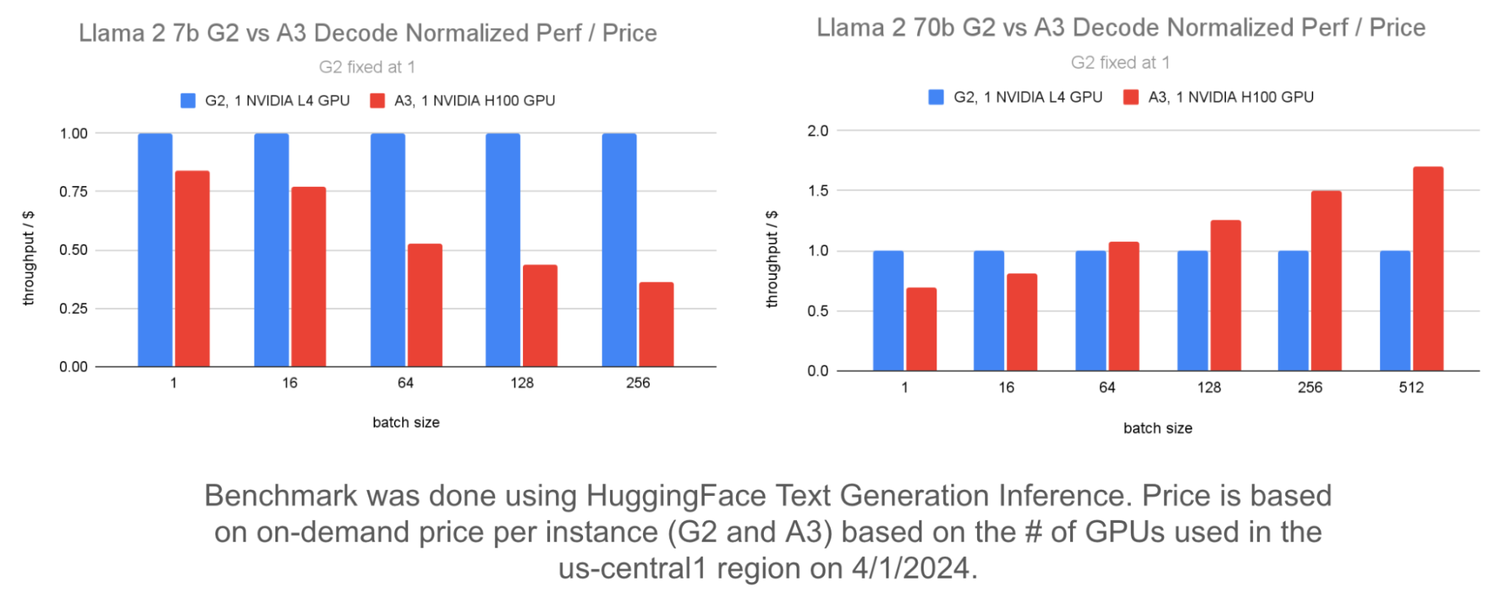
左のグラフは、バッチサイズが大きい場合、Llama 2 7b モデルでは G2 で A3 と比較して $1 あたりのスループットが向上することを示しています。右のグラフは、複数の GPU を使用して Llama 2 70b モデルをサービングする場合に、バッチサイズが大きいと、A3 は G2 と比較して $1 あたりのスループットが優れていることを示しています。これは、Falcon 7b や Flan T5 など、似たようなサイズの他のモデルについても同様です。
任意の GPU マシンを選択し、Google の自動化ツールを使用して GKE クラスタを作成できます。作成した GKE クラスタは、任意のモデルとモデルサーバーを実行するために使用できます。
推奨事項 3: レイテンシを許容できる限り、7b パラメータ以下のモデルには G2 を使用することでコスト パフォーマンスが向上します。大きなモデルには A3 を使用します。
モデルサーバーの最適化
GKE 上での LLM のサービングに利用できるモデルサーバーは HuggingFace TGI、JetStream、NVIDIA Triton および TensorRT-LLM、vLLM です。一部のモデルサーバーでは、LLM の全体的なパフォーマンス向上につながる一括処理、PagedAttention、量子化などの重要な最適化がサポートされています。LLM ワークロード用にモデルサーバーを設定する際には、以下の事項を確認する必要があります。
入力長が長いユースケースと出力長が長いユースケース向けの最適化はどのように実行するか。
LLM 推論は、プレフィルとデコードという 2 つのフェーズで構成されています。
-
プレフィル フェーズでは、プロンプト内のトークンを並列処理し、KV キャッシュを構築します。これは、デコード フェーズと比較すると、スループットが高く、レイテンシが低いオペレーションです。
-
デコード フェーズは、プレフィル フェーズに続くフェーズで、KV キャッシュの状態と以前に生成されたトークンに基づいて新しいトークンが順番に生成されます。これは、プレフィル フェーズと比較すると、スループットが低く、レイテンシが高いオペレーションです。
ユースケースによって、入力長がより長くなる場合(要約、分類など)、出力長がより長くなる場合(コンテンツ生成)、入力長と出力長がほぼ同じになる場合があります。
以下は、G2 と A3 のプレフィル スループットの比較です。
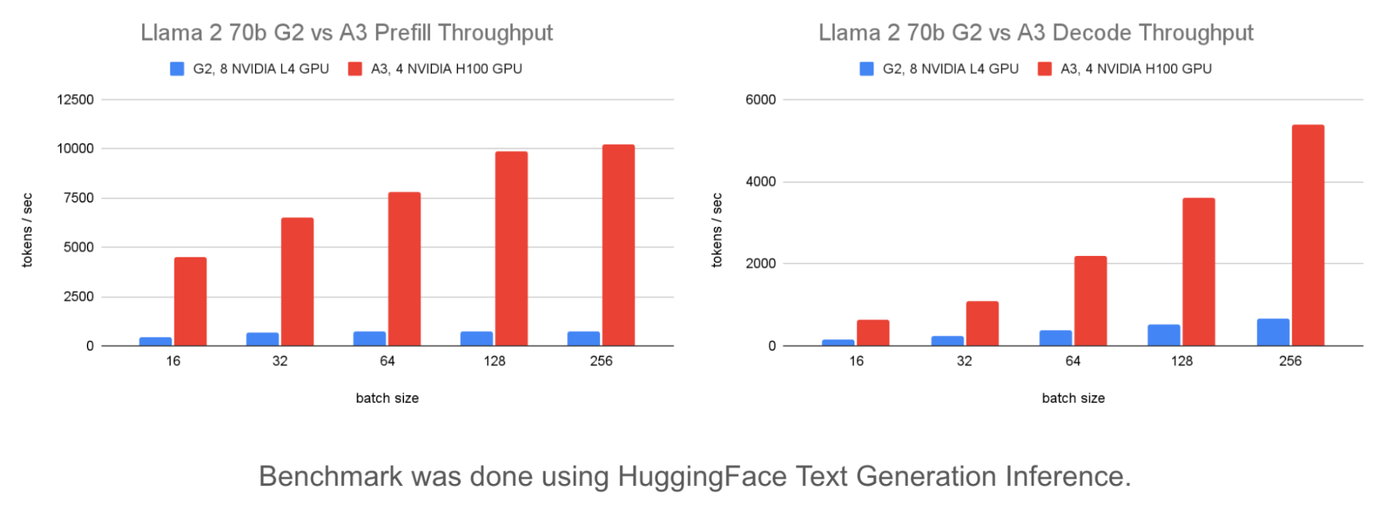
上のグラフは、A3 は G2 と比較してプレフィル スループットが 13.8 倍、コストが 5.5 倍であることを示しています。そのため、入力長がより長いユースケースでは、A3 は $1 あたりのスループットが 2.5 倍になります。
ベンチマーク ツールを使用してニーズに適したさまざまな出力 / 入力パターンをシミュレートし、それらのパフォーマンスを検証できます。
推奨事項 4: 出力よりも入力プロンプトがはるかに長いモデルでは、コスト パフォーマンスを向上させるために A3 を使用します。モデルの入力 / 出力パターンを分析して、ユースケースのコスト パフォーマンスが最適化されるインフラストラクチャを選択します。
一括処理のパフォーマンスへの影響
一括処理リクエストは、コストを増やすことなく、より多くの GPU メモリ、HBM 帯域幅、GPU FLOPS を利用するため、スループットの向上に不可欠です。
以下では、固定入力 / 出力長と静的バッチを使用した異なるバッチサイズの比較により、スループットとレイテンシへの影響が示されています。
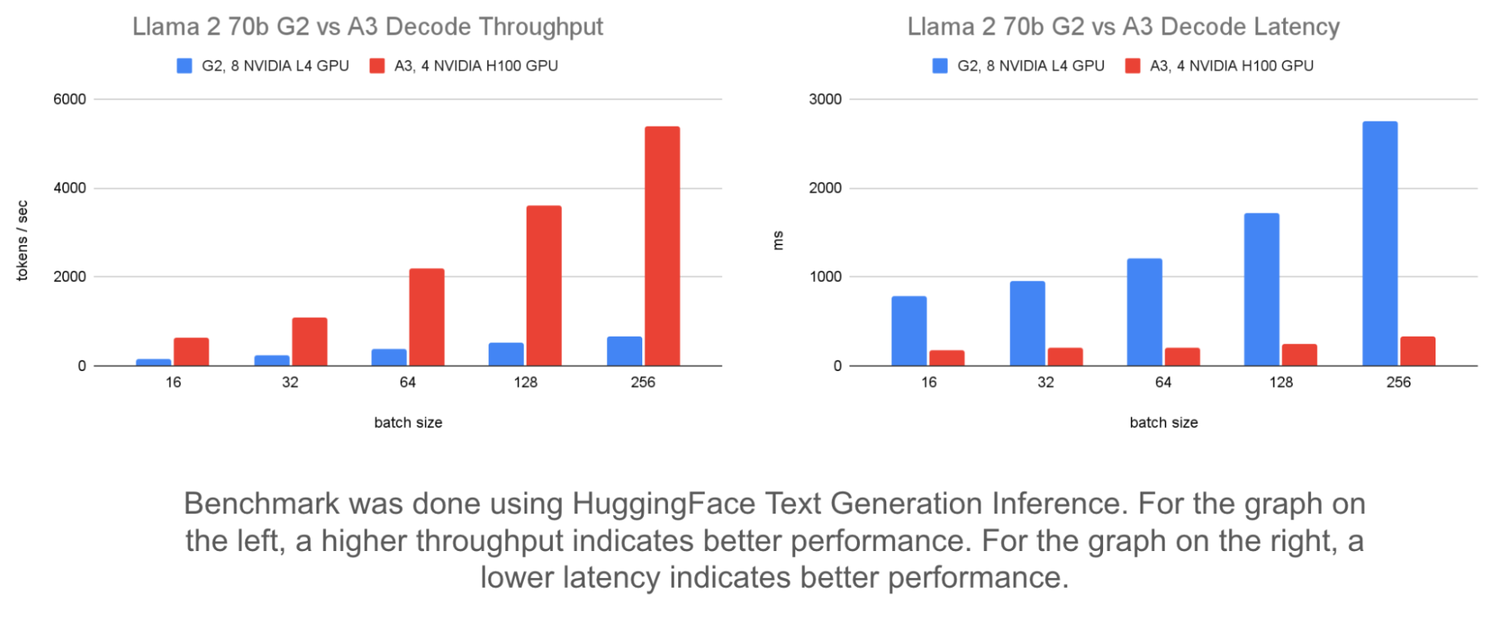
左のグラフは、バッチサイズを 16 から 256 に増やすと、A3 でサービングされる Llama 2 70b モデルのスループットが最大 8 倍向上することを示しています。これにより、G2 のスループットを最大 4 倍向上させることができます。
右のグラフは、一括処理のレイテンシへの影響を示しています。レイテンシは G2 では 1,963 ミリ秒、A3 では 155 ミリ秒増加します。これは、バッチサイズがコンピューティング能力による制約を受けるほど大きくなるまでは、A3 がレイテンシの増加を最小限に抑えながら、より大きなバッチサイズを処理できることを示しています。
理想的なバッチサイズを選択するには、レイテンシ目標に達するか、スループットがそれ以上改善されなくなるまでバッチサイズを増やします。
ベンチマーク ツールで提供されるモニタリングの自動化を使用して、モデルサーバーのバッチサイズをモニタリングでき、それに基づいて設定に最適なバッチサイズを特定できます。
推奨事項 5: バッチ処理を使用してスループットを改善します。最適なバッチサイズは、レイテンシ要件に依存します。低レイテンシを必要とする場合は、A3 を選択します。レイテンシが若干高くなることが許容される場合は、G2 を選択してコストを削減します。
GPU を最大限に活用する
このブログ記事では、モデルの特性、インフラストラクチャの選択、モデルサーバーの最適化が、モデル サービングのパフォーマンスにどのように影響するのかを説明しました。これは、さまざまな条件下でモデルのパフォーマンスを測定し、GKE でのサービング スループットを最大化するための理想的な設定を特定することの重要性を示しています。最初に、ai-on-gke/benchmarks リポジトリに記載されている手順を踏んでください。
GKE 上の A3 または G2 マシンに推論ワークロードをデプロイするには、Triton の Gemma、TGI の Gemma、vLLM の Gemma に関するドキュメントに記載されている手順を踏んでください。これらのドキュメントには、それぞれ TensorRT-LLM、HuggingFace TGI、vLLM を使用して、Triton に Gemma-7b モデルと Gemma-2b モデルをデプロイする方法が記載されています。TGI と vLLM を使用してこれらの最適化手法をデプロイする追加の例については、GKE でのモデルの最適化と構成の提供に関するドキュメントをご覧ください。
-シニア ソフトウェア エンジニア Ashok Chandrasekar
-ソフトウェア エンジニア Anna Pendleton



