Maximize your LLM serving throughput for GPUs on GKE — a practical guide
Ashok Chandrasekar
Software Engineer
Anna Pendleton
Software Engineer
Let’s face it: Serving AI foundation models such as large language models (LLMs) can be expensive. Between the need for hardware accelerators to achieve lower latency and the fact that these accelerators are typically not efficiently utilized, organizations need an AI platform that can serve LLMs at scale while minimizing the cost per token. Through features like workload and infrastructure autoscaling and load balancing, Google Kubernetes Engine (GKE) can help you do just that.
When integrating LLMs into an application, you need to consider how to serve it cost effectively while still providing the highest throughput within a certain latency bound. To help, we created a performance benchmarking tool for GKE that automates the end-to-end setup — from cluster creation to inference server deployment and benchmarking — which you can use to measure and analyze these performance tradeoffs.
Below are some recommendations that can help you maximize your serving throughput on NVIDIA GPUs on GKE. Combining these recommendations with the performance benchmarking tool will enable you to make data-driven decisions when setting up your inference stack on GKE. We also touch on how to optimize a model server platform for a given inference workload.
Infrastructure decisions
When selecting infrastructure that fits your model and is cost effective, you need to answer the following questions:
-
Should you quantize your model? And if so, which quantization should you use?
-
How do you pick a machine type to fit your model?
-
Which GPU should you use?
Let’s take a deeper look at these questions.
1. Should you quantize your model? Which quantization should you use?
Quantization is a technique that decreases the amount of accelerator memory required to load the model weights; it does so by representing weights and activations with a lower-precision data type. Quantization results in cost savings and can improve latency and throughput due to having a lower memory footprint. But at a certain point, quantizing a model results in a noticeable loss in model accuracy.
Among quantization types, FP16 and Bfloat16 quantization provide virtually the same accuracy as FP32 (depending on the model, as shown in this paper), with half the memory usage. Most newer model checkpoints are already published in 16-bit precision. FP8 and INT8 can provide up to a 50% reduction in memory usage for model weights (KV cache will still consume similar memory if not quantized separately by the model server), often with minimal loss of accuracy.
Accuracy suffers with quantization of 4-bit or less, like INT4 or INT3. Be sure to evaluate model accuracy before using 4-bit quantization. There are also some post-training quantization techniques such as Activation Aware Quantization (AWQ) that can help reduce a loss of accuracy.
You can deploy the model of your choice with different quantization techniques using our automation tool and evaluate them to see how it fits your needs.
Recommendation 1: Use quantization to save memory and cost. If you use less than 8-bit precision, do so only after evaluating model accuracy.
2. How do you pick a machine type to fit your model?
A simple way to calculate the machine type that you need is to consider the number of parameters in the model and the data type of the model weights.
model size (in bytes) = # of model parameters * data type in bytes
Thus, for a 7b model using 16-bit precision quantization technique such as FP16 or BF16, you would need:
7 billion * 2 bytes = 14 billion bytes = 14 GiB
Likewise, for a 7b model in 8-bit precision such as FP8 or INT8, you’d need:
7 billion * 1 byte = 7 billion bytes = 7 GiB
In the table below, we've applied these guidelines to show how much accelerator memory you might need for some popular open-weight LLMs.
Note: The above table is provided just as a reference. The exact number of parameters may be different from the number of parameters mentioned in the model name, e.g., Llama 3 8b or Gemma 7b. For open models, you can find the exact number of parameters in the Hugging Face model card page.
A best practice is to choose an accelerator that allocates up to 80% of its memory for model weights, saving 20% for the KV cache (key-value cache used by the model server for efficient token generation). For example, for a G2 machine type with a single NVIDIA L4 Tensor Core GPU (24GB), you can use 19.2 GB for model weights (24 * 0.8). Depending on the token length and the number of requests served, you might need up to 35% for the KV cache. For very long context lengths like 1M tokens, you will need to allocate even more memory for the KV cache and expect it to dominate the memory usage.
Recommendation 2: Choose your NVIDIA GPU based on the memory requirements of the model. When a single GPU is not enough, use multi-GPU sharding with tensor parallelism.
3. Which GPU should you use?
GKE offers a wide variety of VMs powered by NVIDIA GPUs. How do you decide which GPU to use to serve your model?
The table below shows a list of popular NVIDIA GPUs for running inference workloads along with their performance characteristics.
Note: A3 and G2 VMs support structural sparsity, which you can use to achieve more performance. The values shown are with sparsity. Without sparsity, the listed specifications are one-half lower.
Based on a model’s characteristics, throughput and latency can be bound by three different dimensions:
-
Throughput may be bound by GPU memory (GB / GPU): GPU memory holds the model weights and KV cache. Batching increases throughput, but the KV cache growth eventually hits a memory limit.
-
Latency may be bound by GPU HBM bandwidth (GB/s): Model weights and KV cache state are read for every single token that is generated, relying on the memory bandwidth.
-
For larger models, latency may be bound by GPU FLOPS: Tensor computations rely on the GPU FLOPS. More hidden layers and attention heads indicate more FLOPS being utilized.
Consider these dimensions when choosing the optimal accelerator to fit your latency and throughput needs.
Below, we compare the throughput/$ of G2 and A3 for Llama 2 7b and Llama 2 70b models. The chart uses normalized throughput/$ where G2's performance is set to 1 and A3's performance is compared against it.
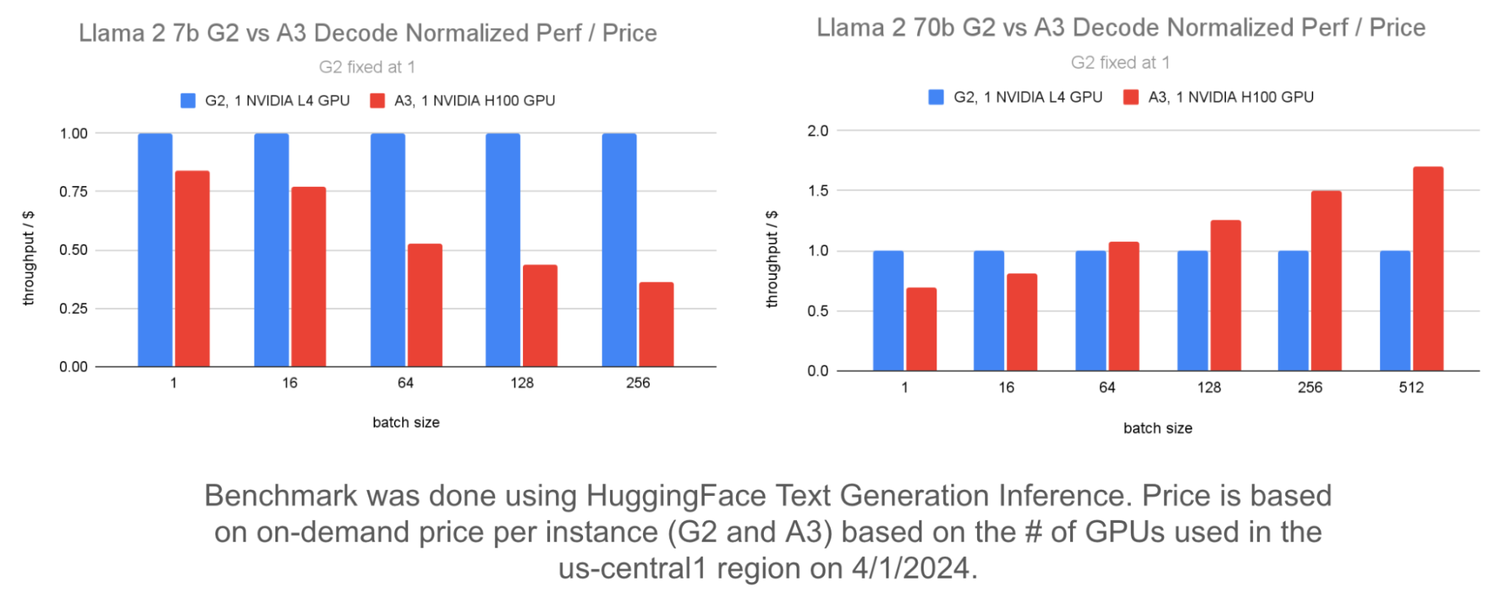
The graph on the left shows that the Llama 2 7b model provides better throughput/$ with G2 compared to A3 at higher batch sizes. The right-hand graph shows that when using multiple GPUs to serve the Llama 2 70b model, A3 provides better throughput/$ compared to G2 at higher batch sizes. The same holds true for other models of similar sizes like Falcon 7b and Flan T5.
You can choose the GPU machine of your choice and create GKE clusters using our automation tool which you can then use to run the model and model server of your choice.
Recommendation 3: Use G2 for models with 7b parameters or less for better price/perf as long as the latency is acceptable. Use A3 for bigger models.
Model server optimizations
There are multiple model servers available for serving your LLM on GKE: HuggingFace TGI, JetStream, NVIDIA Triton and TensorRT-LLM, and vLLM. Some model servers support important optimizations like batching, PagedAttention, quantization, etc., that can improve your LLM's overall performance. Here are a few questions to ask when setting up the model server for your LLM workloads.
How do you optimize for input-heavy vs. output-heavy use-cases?
LLM inference involves two phases: prefill and decode.
-
The prefill phase processes the tokens in a prompt in parallel and builds the KV cache. It is a higher throughput and lower latency operation compared to the decode phase.
-
The decode phase follows the prefill phase where new tokens are generated sequentially based on the KV cache state and the previously generated tokens. It is a lower throughput and higher latency operation compared to the prefill phase.
Based on your use-case, you might have a larger input length (eg. summarization, classification), larger output length (content generation) or a fairly even split between the two.
A comparison of G2 and A3 prefill throughput is shown below.
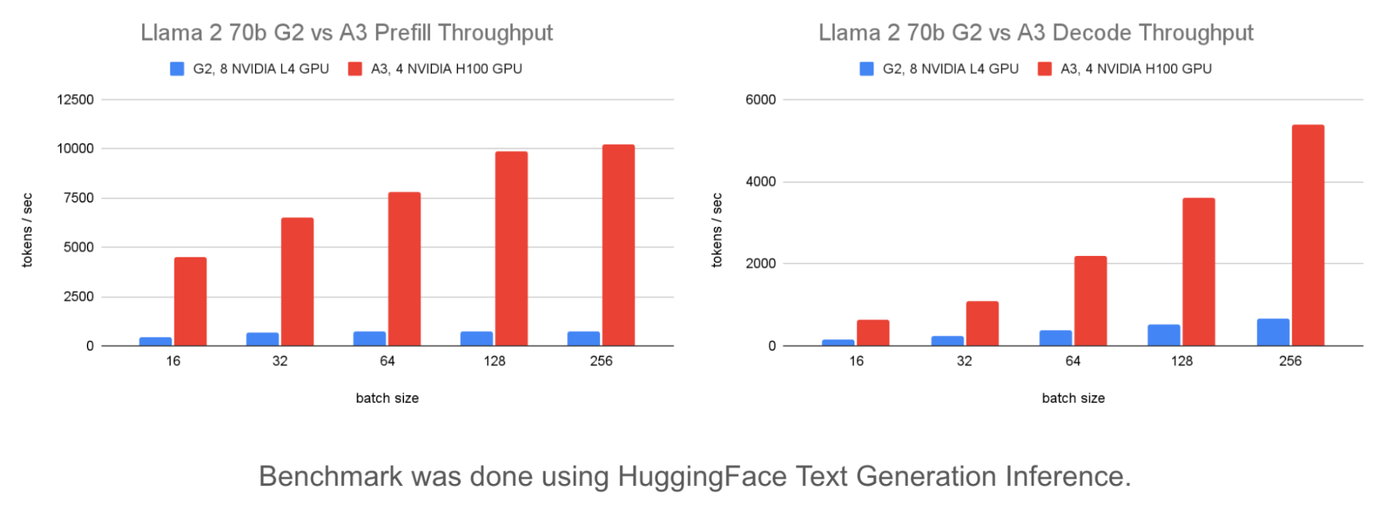
The graphs show that A3 provides 13.8x the prefill throughput of G2 at 5.5x the cost. So, if your use case has a larger input length, then A3 will provide 2.5x better throughput per $.
You can simulate different input / output patterns that fit your needs using the benchmarking tool and validate their performance.
Recommendation 4: Use A3 for better price/perf on models that have a much longer input prompt than output. Analyze the input / output pattern of your model and choose the infrastructure which will provide the best price/perf for your use case.
How does batching affect performance?
Batch requests are essential for achieving higher throughput since they utilize more GPU memory, HBM bandwidth and GPU FLOPS with no increase in cost.
A comparison below of different batch sizes using fixed input / output length and static batches shows the effect on throughput and latency.
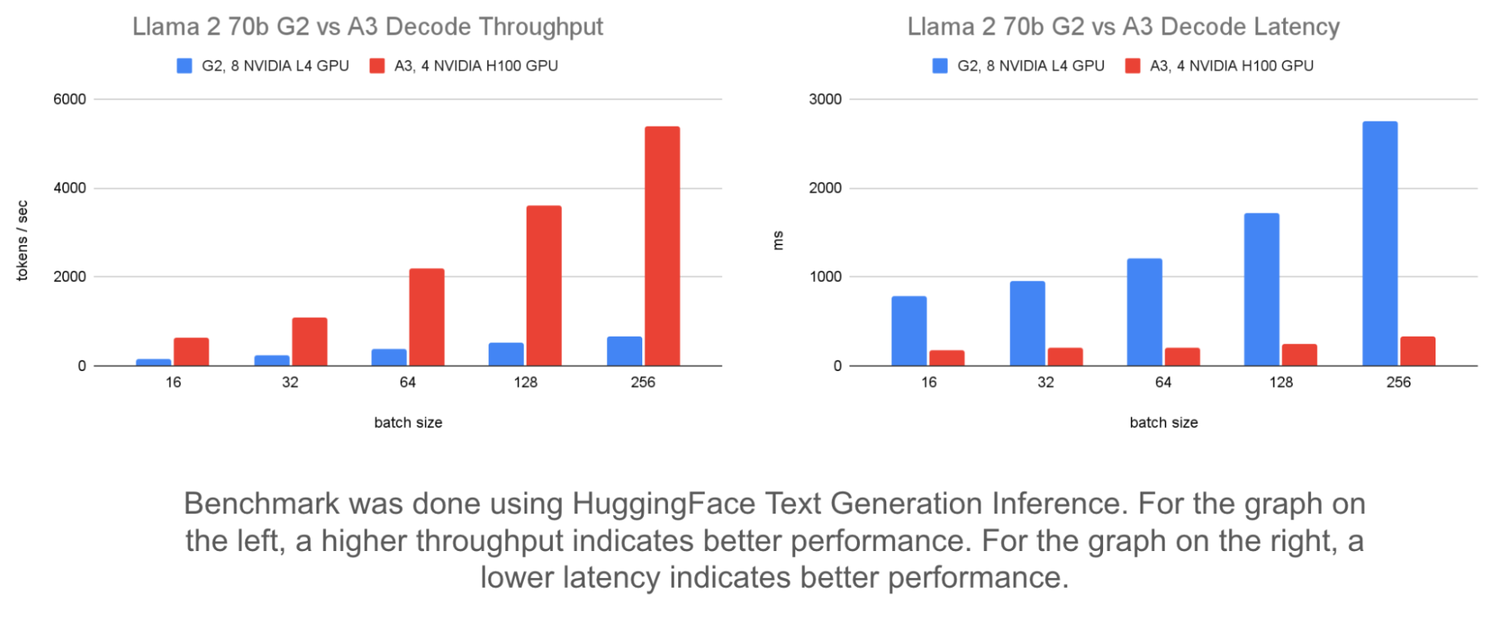
The graph on the left shows that increasing batch size from 16 to 256 improves throughput by up to 8x on a Llama 2 70b model served on A3. It can improve throughput on G2 up to 4x.
The graph on the right shows how batching affects latency. On the G2, latency increases by 1,963 ms. But on A3, latency increases by 155 ms. This shows that A3 can handle larger batch sizes with minimal increases in latency until the batch size is large enough to be compute-bound.
Choosing the ideal batch size involves increasing your batch size until you either hit your latency target or when there is no additional improvement in throughput.
You can monitor the batch size of your model server using the monitoring automation that the benchmarking tool provides. You can then use that to identify the ideal batch size for your setup.
Recommendation 5: Use batching to improve throughput. The optimal batch size depends on your latency requirements. Choose A3 for lower latency. Choose G2 to save money where a slightly higher latency is acceptable.
Maximize those GPUs
In this blog, you’ve seen how model characteristics, infrastructure choices and model server optimizations can determine model serving performance. This underscores how important it is to measure the performance of your model under different conditions and identify the ideal setup to maximize your serving throughput on GKE. To get started, please follow the steps listed in the ai-on-gke/benchmarks repository.
To deploy inference workloads on A3 or G2 machines on GKE, please follow the steps listed in Gemma on Triton, Gemma on TGI or Gemma on vLLM, which demonstrate how you can deploy the Gemma-7b and Gemma-2b models on Triton with TensorRT-LLM, HuggingFace TGI and vLLM respectively. For additional examples of deploying these optimization techniques with TGI and vLLM, see Optimizing Model and Serving Configurations on GKE.


