Vertex AI Matching Engine を利用したニュース記事のレコメンデーション
Google Cloud Japan Team
記事の閲覧に基づいた次に読む記事のレコメンデーション
※この投稿は米国時間 2023 年 4 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
レコメンデーション システムの核となる機能の一つに、候補とアンカー検索アイテムの間の類似性を見つける能力があります。たとえば、ある記事を読んだ後で、それに類似した別の記事にも興味が出てくることがあります。レコメンデーション システムがあればそうした記事を見つけることができます。
レコメンデーション システムは、ユーザー エクスペリエンスの改善やユーザーが購入する可能性の高いアイテムの送信による販売促進、またユーザーが継続して使用する可能性の高いアイテムを提案することで、顧客の離脱抑止なども可能となります。
このようなシステムの構築において、ML エンジニアは次のようないくつかの問題に直面します。
大量のデータを収集し保存する必要性。このデータは、ウェブサイトやアプリでのユーザー インタラクション、データベースの過去のデータなど、多様なソースから取得が可能。
データの収集後は、ML モデルが処理しやすい形式でデータを保存する必要がある。
データを使用して ML モデルをトレーニングする必要性。これは、時間と計算費用がかかるプロセスになる可能性がある。
モデルのトレーニング実施後は、リアルタイムでレコメンデーションを生成できることが必要。
このブログ投稿では、Vertex AI Matching Engine を使用して、テキストデータの文脈類似性から類似文書を見つけるレコメンデーション システムを構築する方法について説明します。
Vertex AI Matching Engine は、レコメンデーション システムを構築し、デプロイするための高スケーラブルで低レイテンシのフルマネージド型類似性検索ソリューションです。データセットのベクトル表現を圧縮して、高速な近似距離計算ができるようにすることに重点を置いています。以降のセクションでは、このツールを他の Google Cloud サービスと合わせて利用することで、ニュースや記事のレコメンデーション システムを構築し、類似の記事や書式なしテキストのクエリを実現する方法について紹介します。
アプローチ
Google Cloud でレコメンデーション ツールを構築する手順は次のとおりです。
記事のデータを取り込み、Dataflow パイプラインを通して変換します。
事前トレーニング済みのエンベディング NLP モデル(universal-sentence-encoder)を使用してテキストを数値ベクトルに埋め込みます(ラベル付きのデータが十分にあれば、独自のモデルをトレーニングするか事前トレーニング済みモデルの微調整を検討します)。
エンベディング ベクトルのクラスタリングに使用する Vertex AI Matching Engine のインデックスを作成します。これらのベクトルが類似記事のクエリに役立ちます。
このブログ投稿にあるソースコードは、こちらのノートブックでアクセスできます。
前提条件
Google Cloud 上でこのソリューションを実行するためには、請求先アカウントと紐づいた Google Cloud プロジェクトが必要です。ユーザーの認証情報は、Storage、Vertex AI、Dataflow などのサービスの利用に必要な権限を備えている必要があります。
以下は、類似の記事を抽出するために提案されたソリューションを示す Google Cloud 上で構築されたサンプル アーキテクチャです。
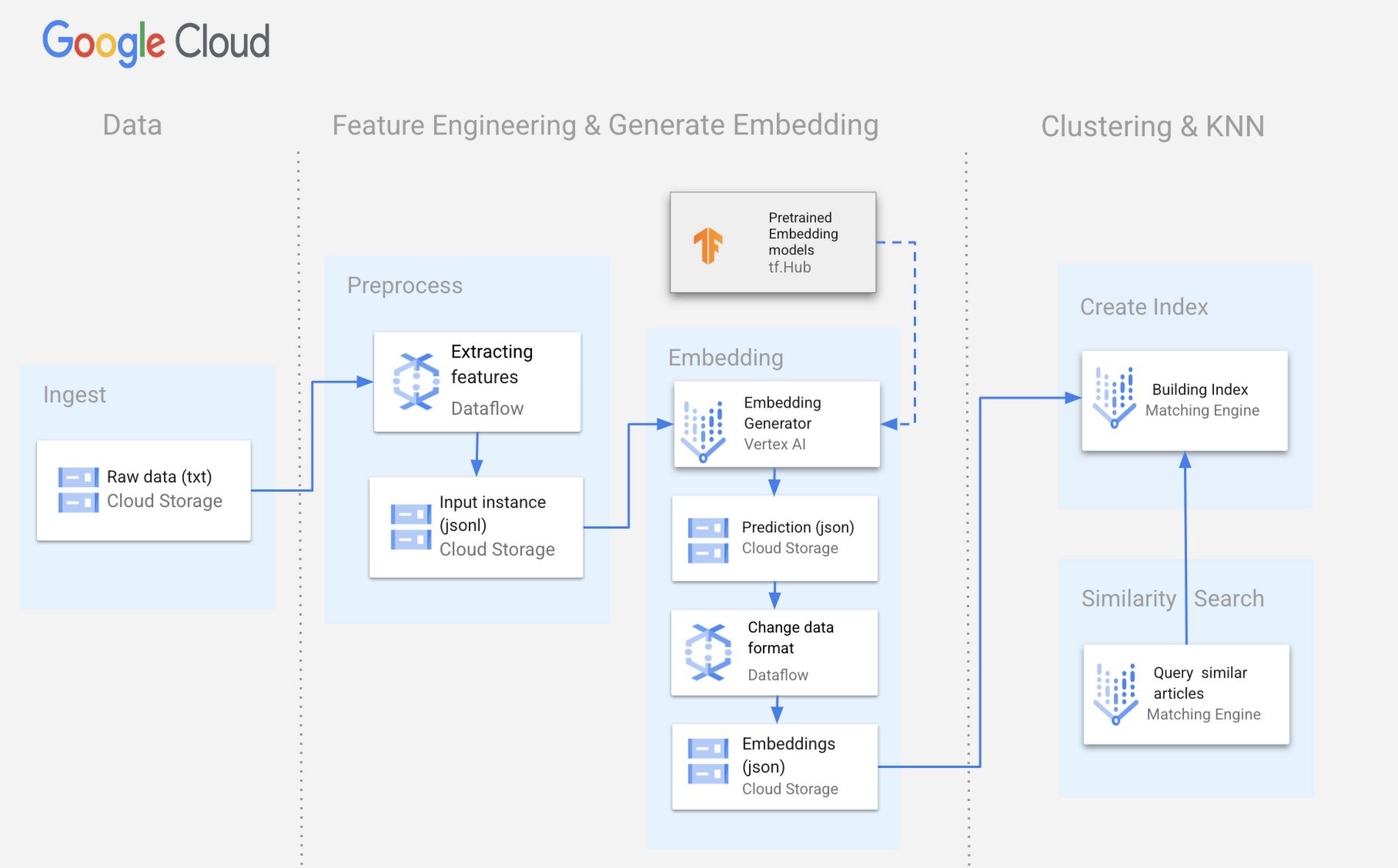
データの取り込み
記事のデータは Google Cloud Storage に保存されており、タイトル、URL、本文、記事に関連するその他のメタデータを含む書式なしテキストの形式であると仮定します。
このデータを抽出して変換するために、Dataflow のパイプラインを作成し、記事データを変換した結果を Vertex AI で処理できる適切なフォーマットで Google Cloud Storage に書き出すようにします。
Google Cloud Dataflow は、データ パイプラインの作成と管理を実施するフルマネージド サービスです。プログラミング モデル、ライブラリ、データ処理パイプラインの構築と管理を行うツール群を提供します。
Dataflow のパイプラインは一連のステップとして定義され、各ステップはさまざまなプログラミング言語、たとえば Java、Python、Go などで記述できます。
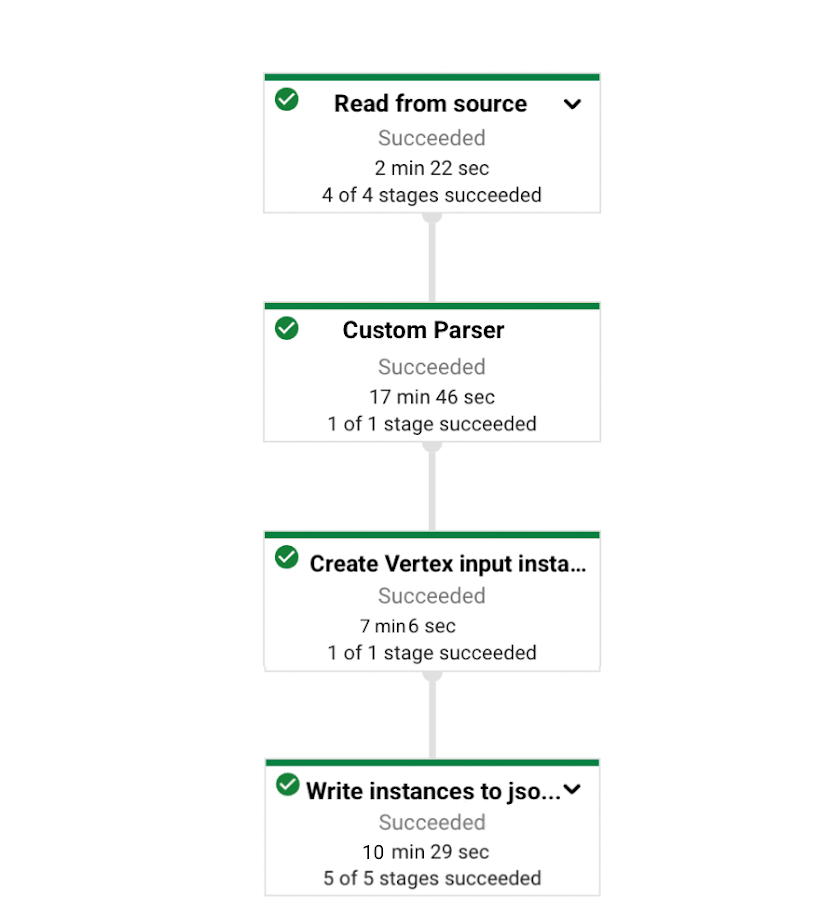
今回のパイプラインでは次のようなステップを実行します。
Google Cloud Storage に保存されているテキスト(txt)ファイルを読み込む。
ファイルをパースして、特殊文字(‘、”、/ など)を除去し、タイトルと本文を結合する。
変換済みのデータを GCS に Vertex AI がバッチ予測ジョブの入力として処理できる JSONL 形式(すなわち予測の入力インスタンス)で書き込む。
このパイプラインの実装例を示します。
custom_parser は、データをパースして、タイトルと本文を結合し、特殊文字を除去する関数です。
create_instance は、Vertex AI バッチ予測に使用する JSONL 形式の入力インスタンスを生成する関数です。これで得られる入力インスタンスは、{ “bytes_inputs”: text , “article_id”: id} の形式になります(詳細はエンベディングのセクションに記載)。
エンベディング
エンベディングを使用すれば、言葉を数値ベクトルの形式で表現することが可能になります。そのベクトルによって、類似性の指標を計算し、Vertex AI Matching Engine のインデックスを作成できます。ML 分野では、セマンティック検索ツール、レコメンデーション システム、テキストの分類、広告ターゲット設定システム、chatbot、バーチャル アシスタントなどに高次ベクトル エンベディングが活用されています。今回の例ではラベル付きのデータが存在しないので、TensorFlow Hub の事前トレーニング済みモデルを使用します。事前トレーニング済みのエンベディング モデルを使用するのではなく、手持ちのデータでエンベディング モデルのトレーニングを行うことで、モデル エンベディングの性能が改善し得ることに注意してください。TensorFlow Hub には利用可能な事前トレーニング済みテキスト エンベディング モデルが数多くあります。これらのモデルは大規模なテキスト コーパスを用いてトレーニングされており、多様な言語で言葉の意味を表現するのに使用できます。
記事のエンベディングには、英語のコーパスを使用して Google が開発とトレーニングを行った universal-sentence-encoder を選択しました。
モデル アーティファクトのダウンロード
TensorFlow Hub からモデルファイルをダウンロードし、GCS バケットにアップロードします。この GCS バケットは次の手順で使用します。
モデル シグネチャの変更
ここでダウンロードしたモデルは、テキストを入力として受け付け、順序が正しくない可能性があるエンベディング ベクトルを返します。それぞれの記事とそのエンベディングをたどれるように、出力をカスタマイズして、各エンベディングが article_id と対応づくようにします。
Eg: {"article_id": article_id,"embedding": [1,1,1,1,1,...]}
この関数は元々のモデルをもとに、出力形式(すなわち TensorFLow が保存したモデル シグネチャからの出力)に article_id を追加して変更し、新しいモデルを「ラップされた」バージョンとして GCS に保存します。
エンベディング モデルの Vertex AI へのアップロード
次は、エンベディング モデルをインポートし、Vertex AI で使用できるようにします。これを Vertex AI のクライアント SDK を使用してプログラムで実施する方法の例を示します。
display_name: 人間が判読できるモデルリソースの名前。
artifact_uri: トレーニング済みの署名付きモデル アーティファクトの Google Cloud Storage 上の場所(/wrapped_model)。
serving_container_image_uri: サービング コンテナ イメージ。事前構築済みのコンテナ イメージを利用可能。
sync: アップロードを非同期で行うか同期で行うかを指定。
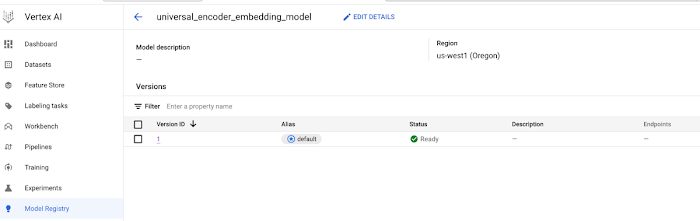
アップロードが完了すると、次のスクリーンショットのように、モデルが Vertex AI 上で確認できます。モデルがインポートできていることを確認してから次の手順に進んでください。
エンベディング モデルによるバッチ予測
Vertex AI 上のモデルで予測を実施する方法には、バッチ予測とリアルタイム予測の 2 つがあります。ここで扱うテキスト入力は、膨大な数になり得るため、Vertex AI で使用できるバッチ予測ジョブサービスを使用してすべての記事を変換し、エンベディングを JSON 形式で GCS に保存します。
job_display_name: 人間が判読できるバッチ予測ジョブの名前。
gcs_source: 1 つ以上のバッチ リクエスト入力ファイルのリスト。
gcs_destination_prefix: バッチ予測の結果を格納する Google Cloud Storage 上の場所。
instances_format: 入力インスタンスのフォーマットで、「csv」か「jsonl」のいずれか。デフォルトは「jsonl」。
predictions_format: 出力される予測のフォーマットで、「csv」か「jsonl」のいずれか。デフォルトは「jsonl」。
generate_explanations: True に設定すると説明を生成する。
sync: True に設定すると、非同期バッチジョブが完了するまで呼び出しをブロックする。
予測が完了すると、Vertex AI ダッシュボードの [バッチ予測] タブにジョブが完了として表示されます。
オンライン予測エンドポイントへのモデルの提供
バッチ予測の場合と異なり、リアルタイム予測を実行するにはモデルを Vertex AI のエンドポイントにデプロイする必要があります。
この手順は、一度に 1 件の記事を入手し、これをエンベディングにマッピングして、類似の記事をクエリすることが想定される本番環境で役立ちます。
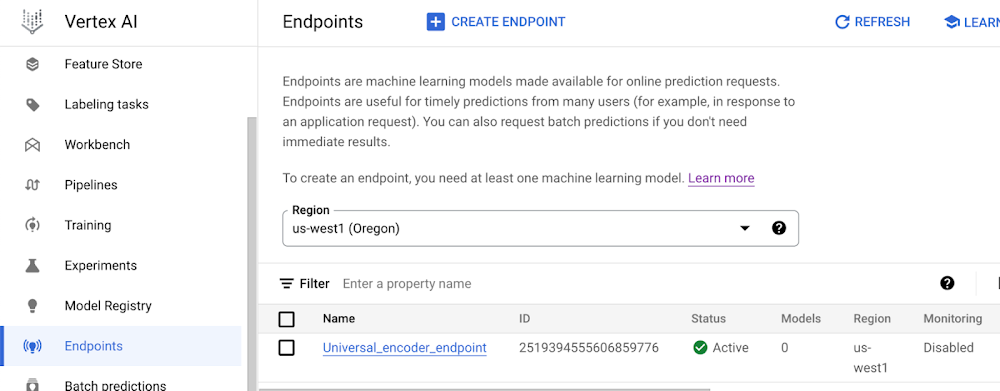
エンドポイントを作成し、アップロード済みのモデルをデプロイする手順を示します。
エンドポイントの準備が整うと、Vertex AI ダッシュボードに以下のように表示されます。
エンドポイントの準備が整ったので、次にオンライン予測の実行方法を示します。
類似性の検出
記事をエンベディングとして表現したので、類似性モデルを実行し、第一の目標である「新しい記事を指定し、エンベディングされた記事のデータベースから類似のものを選び出す」という作業を達成できます。Vertex AI Matching Engine を使用すると、これを大規模に実施できます。
Vertex AI Matching Engine
Vertex AI Matching Engine は大規模で低レイテンシのベクトル データベースを提供します。スケーラブルな最近傍探索(ScaNN)をバックグラウンドで利用します。ScaNN は最新の近似最近傍探索の最先端な実装です。膨大なデータセットに対する最近傍探索の実行を劇的に高速化できます。ANN の実装として、ScaNN は Tree-AH と呼ばれる近似アルゴリズムを使用して最近傍を見つけます。これは何百万という大量のデータポイントを扱う場合、現実的な時間内に真の最近傍を見つけられないことが多いためです。
Vertex AI Matching Engine では、類似性スコアに基づいてエンベディング ベクトルを格納、取得するために、インデックスを使用します。この構造により、Vertex AI Matching Engine は類似性検索を大規模に実施し、高い QPS、再現率、費用対効果を得ることが可能です。
インデックスの作成
ここまでで、以前のバッチ予測ジョブで予測されたエンベディング ベクトルをすべて含む JSON ファイルがバケットに保存されています。このエンベディングを Vertex AI Matching Engine のインデックス作成関数の入力として使用するには、記事 ID とエンベディング ベクトルを JSON ファイルに次のような形式で記述する必要があります。
では、Vertex AI Matching Engine のインデックスを作成してみましょう。
2 種類のアルゴリズムが Vertex AI Matching Engine のインデックス作成に使用可能です。その 1 つは前述した ANN アルゴリズムを使用するもので、もう 1 つのオプションはブルート フォース アルゴリズムを使用します。ブルート フォースは基本的な最近傍探索アルゴリズム(線形ブルート フォース探索)を用います。これは効率が低いため、本番環境での使用は推奨されません。正解データとして扱うことができ、これによって取得された近傍はインデックスの性能の評価に利用できます。
インデックスの作成に当たっては、バッチ アップデートとストリーム アップデートのどちらをサポートするかを指定する必要があります。バッチ アップデートは大量のアイテムをまとめて更新する作業に使用され、ストリーム アップデートはアイテムの到着ごとの更新に使用されます(詳細はバッチ アップデートとストリーム アップデートを参照)。
以下のスクリプトでは、bruteforce と stream_update フラグで設定を切り換えられるようになっています。設定するパラメータのリストは以下のとおりです。
display_name: 人間が判読できるインデックスの名前。
contents_delta_uri: インデックスのデータ(エンベディング ベクトル)を含む GCS バケットの URL。
dimensions: エンベディング ベクトルの次元。
approximate_neighbors_count: 並べ替え前の近似検索に含まれる近傍の数。この値を大きくすると、複数のツリーからの結果を並べ替えるため、クエリ時間のレイテンシが増加します。
distance_measure_type: インデックスに使用する距離指標の種類。
leaf_node_embedding_count: ツリーの中のリーフノードそれぞれに置くエンベディングの数。
leaf_nodes_to_search_percent: クエリに対して検索するリーフノードのパーセンテージ。
description: インデックスの説明。
インデックスのデプロイ
インデックスが作成されたら(作成にかかる時間はベクトルの数によって変わります)、クエリを実行して新しいエンベディング ベクトルの最近傍を取得するためには、エンドポイントへのデプロイが必要となります。
インデックスをデプロイする前に、VPC ネットワーク ピアリング接続を設定し、限定公開サービス アクセスを有効にして、ベクトルマッチのオンライン クエリを低レイテンシで実行できるようにします。これは、1 回限りの設定です。既存の VPC を再利用できます。
以下のコード スニペットでは、作成したインデックスを Vertex AI Matching Engine のエンドポイントにデプロイしています。このエンドポイントは限定公開であるため、呼び出し元はインデックスと同じネットワーク内にある必要があります(現時点で Vertex AI Matching Engine サービスには公開エンドポイントがありません)。インデックスをエンドポイントにデプロイするためには、以下のパラメータが必要です。
vpc_network はデプロイされるインデックスの ID。
インデックスのクエリ
では、新しい未読の記事を使ってインデックスにクエリを実行してみましょう。新しい記事を与えられ、エンベディングを抽出するとします。リアルタイムあるいはオンライン エンベディング予測を行う場合、「aiplatform.Endpoint.create」を使用してエンドポイントに Vertex AI の登録済みエンベディング モデルをデプロイする必要があります。
最も類似した 10 件の記事をクエリします。
Candidates_embedding: 近傍をクエリする新しい記事のエンベディング ベクトル。
インデックスの更新
インデックスがデプロイされている場合は、バッチ アップデートまたはストリーム アップデートで更新が可能です。バッチ アップデートではバッチ スケジュールでインデックスの更新ができます。ストリーム アップデートでは短い時間(数秒)でインデックスの更新とクエリができます。
新しいレコードはメモリ中に別のインデックスとして保存され、それに対するクエリも可能です。そのため、数件のレコードを更新する処理を効率良く柔軟に実施できます。この方法では、新しいデータやコンパクションされていないデータが 1 GB を超えるか 3 日以上経過すると、インデックスの再構築、別名コンパクションが発生します(詳細についてはインデックスの更新を参照)。料金の詳細については、Vertex AI の料金ページをご覧ください。
リアルタイムのエンドツーエンド実行
リアルタイムでの実行には、冒頭で説明したのと同じパイプラインに記事データを流し、変換後の出力を使用してエンベディング ベクトルを抽出する必要があります。エンベディング モデルからオンライン予測の出力が n 次元のベクトルとして返されるので、これを Vertex AI Matching Engine のインデックスに送信して、上位 K 個のレコメンデーション(最近傍)をクエリできます。
これで、上位 K 件のおすすめ記事の ID のクエリを実行できました。
まとめ
Vertex AI Matching Engine ではベクトル空間での類似性検索サービスが利用できるため、類似性があり、メディア ライターや編集者に推薦できる記事を特定できます。この機能を利用するためには、まずテキストデータをエンベディングあるいは特徴ベクトルに変換することが必要ですが、通常これは深層ニューラル NLP モデルを使用して実現されます。このブログ投稿では、Wikipedia とウェブのリソースで事前トレーニング済みのユニバーサル センテンス エンコーダの高度なエンベディング能力を使用して、記事のベクトルを Vertex AI Matching Engine の入力ベクトルに変換しました。その後、これらのベクトルを使用してインデックスを生成し、エンドポイントにデプロイしました。同じエンベディングの方法を使用することで、編集者なら新しい記事のドラフトを埋め込み、そのインデックスを使用してベクトル空間で上位 K 個の最近傍を取得し、返された記事 ID から類似の記事にアクセスできます。このソリューションを使用して、コンテンツが似ている記事を推薦するツールとして活用することも可能です。
詳細にご興味があれば、こちらもご覧ください。
- Google、クラウド テクニカル レジデント Christian Bagaya
- Google、AI エンジニア Saeedeh Afshari



