Recommending news articles using Vertex AI Matching Engine
Christian Bagaya
Cloud Technical Resident, Google
Saeedeh Afshari
AI Engineer, Google
Recommend a next step based on consumption of an article
One of the core aspects of recommendation systems is finding similarities among the candidates and the anchor search items. For example, If you just read an article, you might be interested in other articles that are similar; a recommendation system can help you find those articles.
Recommendation systems can also improve the user experience, increase sales by sending items that users are more likely to purchase, and reduce customer churn by recommending items that users are more likely to continue using.
When building such systems, ML engineers face multiple problems including:
The need to collect and store a large amount of data. This data can come from a variety of sources, such as user interactions with a website or app, or historical data from a database.
Once the data is collected, it needs to be stored in a format that can be easily processed by a machine learning model.
The need to train a machine learning model on the data. This can be a time-consuming and computationally expensive process.
Once the model is trained, it needs to be able to make recommendations in real time.
In this blog post, we will discuss how to build a recommendation system that leverages context similarity of text data to find similar documents using Vertex AI Matching Engine.
Vertex AI Matching Engine is a fully managed, highly scalable, and low latency similarity search solution to build and deploy recommendation systems. It focuses on compressing vector representations of the dataset to enable fast approximate distance computation. In the following sections, you will learn how to use this tool along with other Google Cloud services to build a news/article recommendation system and query for similar articles or plain texts.
Approach
Here are the steps taken to build the recommendation tool on Google Cloud:
Ingest article data and transform it through a Dataflow pipeline.
Use a pre-trained embedding NLP model (universal-sentence-encoder) to embed your text into numerical vectors (if you have enough data with labels, consider training your own model or fine-tune a pre-trained model).
Create a Vertex AI Matching Engine Index for clustering the embedding vectors which will help query for similar articles.
You can access the source code of this blog post in this notebook.
Prerequisites
To execute this solution on Google Cloud, you need a Google Cloud project which is attached to a billing account. User credentials need to get required permissions to use services including Storage, Vertex AI, Dataflow.
Here is a sample architecture built on Google Cloud that shows our solution proposed for extracting similar articles.
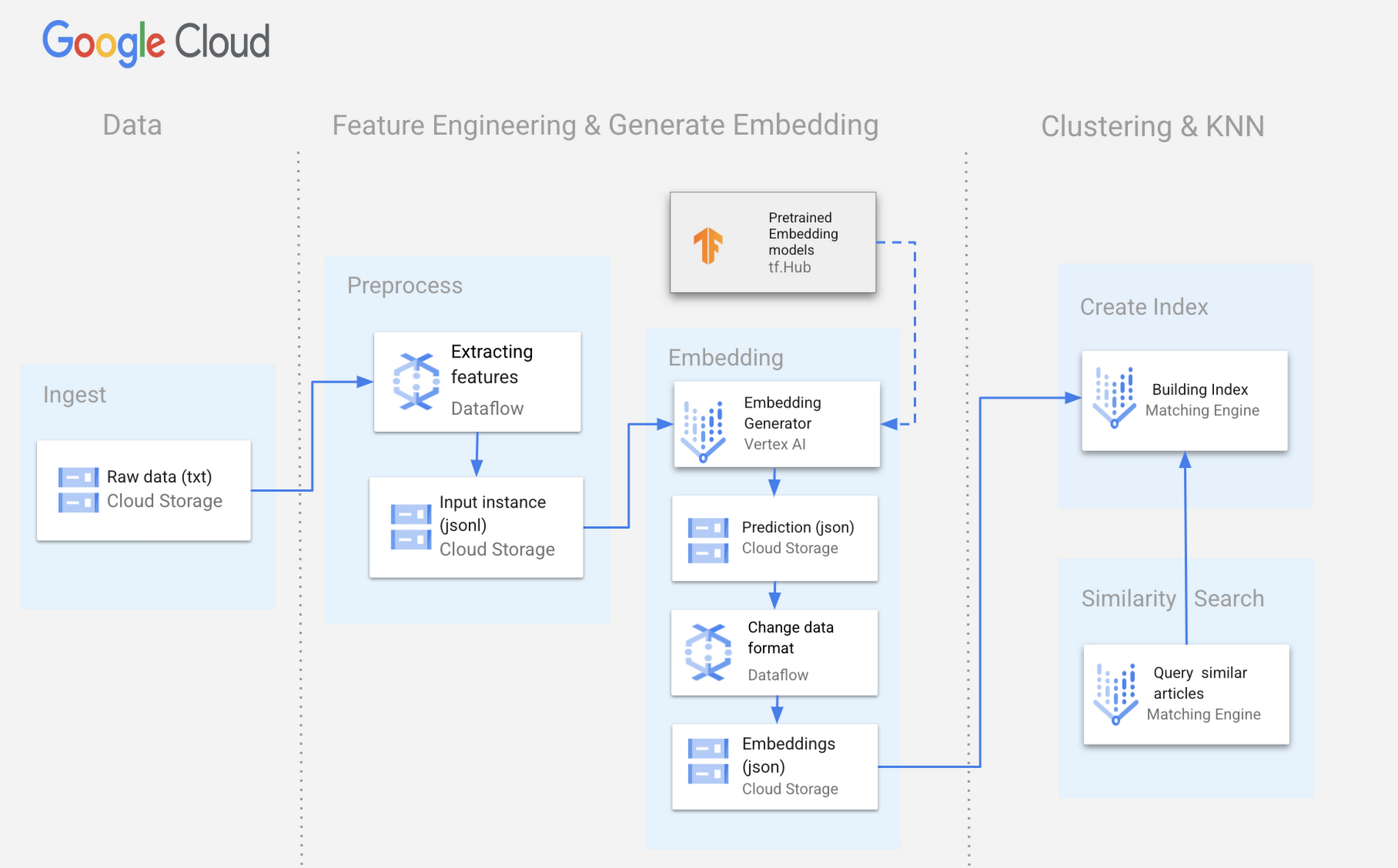
Data Ingestion
Let’s assume the article data is stored in Google Cloud Storage in the form of plain text containing the title, url, body and other metadata related to the article.
To extract and transform this data, we can set up a Dataflow pipeline that transforms the article data and writes the results into Google Cloud Storage with the right format to be consumed by Vertex AI.
Google Cloud Dataflow is a fully managed service for creating and managing data pipelines. It provides a programming model, libraries, and a set of tools for building and managing data processing pipelines.
Dataflow pipelines are defined as a series of steps, each of which can be written in a variety of programming languages, including Java, Python, and Go.
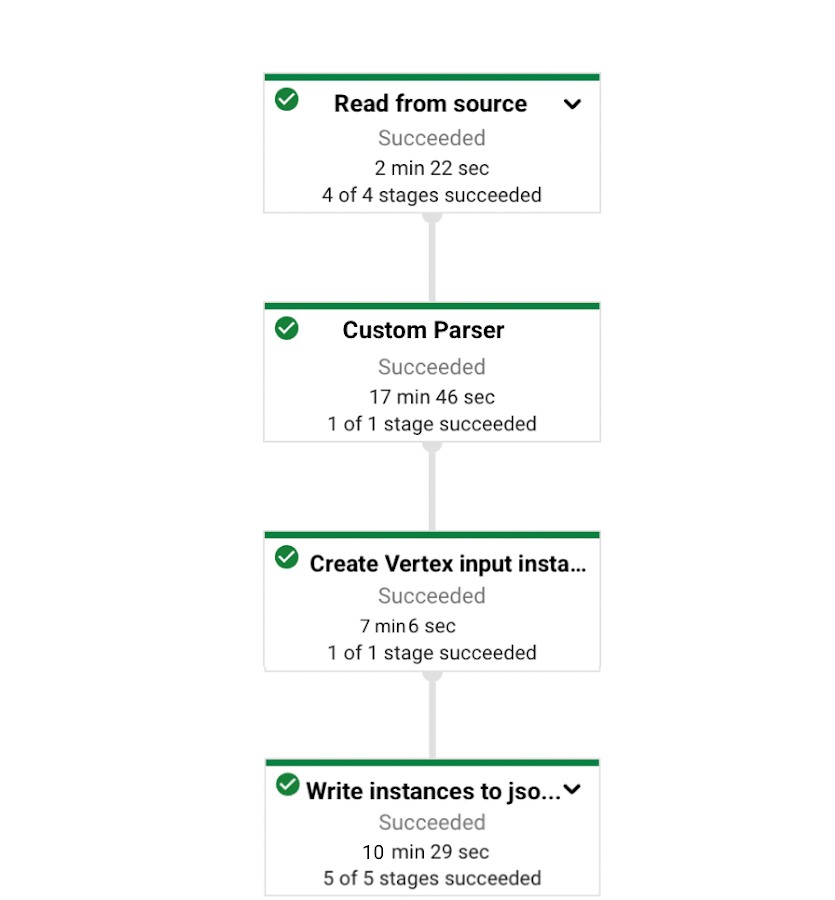
Here are the steps we will take in our pipeline:
Read the txt files stored in Google Cloud Storage,
Parse the files, remove special characters like ‘ , ” , / and concatenate the title and body.
Write the transformed data into GCS in a JSONL format (i.e. prediction input instances) that Vertex AI can consume as input for batch prediction jobs.
Here is an example of how this pipeline would be implemented.
custom_parser is the function that parses the data, concatenates the title and body and removes special characters.
create_instance is the function that creates input instances for Vertex AI Batch Prediction in JSONL format. The resulting input instance is in the format: { “bytes_inputs”: text , “article_id”: id} (more details in the Embedding section)
Embedding
Embeddings give us the ability to represent words in the form of numerical vectors. With vectors, we will be able to calculate similarity metrics and create Vertex AI Matching Engine indexes. In ML, dense vector embeddings power semantic search tools, recommendation systems, text classification, Ad targeting systems, chatbots and virtual assistants. Given that we do not have labeled data in this example, we will use a pre-trained model from TensorFlow Hub. Note that the performance of our model embeddings could be improved by training an embedding model on our data instead of using a pre-trained embedding model. TensorFlow Hub has a number of pre-trained text embedding models available. These models are trained on large corpora of text and can be used to represent the meaning of words in a variety of languages.
For embedding the articles, we chose the universal-sentence-encoder developed and trained by Google on an English corpus.
Download the model artifact
From TensorFlow Hub, download the model files and upload them into a GCS bucket. We will use the GCS bucket in the next step.
Changing the model signature
The model we previously downloaded takes text as input, and returns embedding vectors that might not be in order. To keep track of each article and its embedding, we will customize the output such that each embedding is mapped to the article_id.
Eg: {"article_id": article_id,"embedding": [1,1,1,1,1,...]}
This function takes the original model, changes the output format (i.e. outputs from TensorFlow saved model signature) by adding the article_id, and saves a new copy as a 'wrapped' version in GCS.
Upload the embedding model into Vertex AI
Now, let’s import the embedding model and make it available for use in Vertex AI. Here is an example of how it can be achieved programmatically using the Vertex AI client SDK.
display_name: The human readable name for the Model resource.
artifact_uri: The Google Cloud Storage location of the trained model artifacts with signature (/wraped_model).
serving_container_image_uri: The serving container image. You can use one of the pre-built container images
sync: Whether to execute the upload asynchronously or synchronously.
When it’s done uploading, the model will show in Vertex AI as shown in the screenshot below. Make sure your model has been imported before moving onto the next step.
Embedding model batch prediction
There are two ways to get predictions from a model on Vertex AI: batch prediction and real time prediction. Since we are dealing with potentially millions of text input, we will use a batch prediction job service available in Vertex AI to transform all the articles and save the embeddings in GCS in JSON format.
job_display_name: The human readable name for the batch prediction job.
gcs_source: A list of one or more batch request input files.
gcs_destination_prefix: The Google Cloud Storage location for storing the batch prediction results.
instances_format: The format for the input instances, either 'csv' or 'jsonl'. Defaults to 'jsonl'.
predictions_format: The format for the output predictions, either 'csv' or 'jsonl'. Defaults to 'jsonl'.
generate_explanations: Set to True to generate explanations.
sync: If set to True, the call will block while waiting for the asynchronous batch job to complete.
When the prediction completes, the job will show as finished on the Vertex AI dashboard, batch predictions tab.
Serve the model to an online prediction endpoint
Unlike batch prediction, you cannot perform real time prediction without deploying your model to an endpoint on Vertex AI.
This step will come in handy in production when we expect to receive one article at a time, map it to an embedding and query similar ones.
Here is how you can create an endpoint and deploy the uploaded model.
When the endpoint is ready, it will show on the Vertex AI dashboard as shown below.
Now that the endpoint is ready, here is how you can run an online prediction.
Finding similarity
Having represented our articles as embeddings, we can now run similarity models to achieve our primary goal: given a new article, retrieve similar ones from our database of embedded articles. We will use Vertex AI Matching Engine to achieve this at scale.
Vertex AI Matching Engine
Vertex AI Matching Engine provides a high-scale low latency vector database. It uses Scalable Nearest Neighbor (ScaNN) in the background. ScaNN is a state of the art implementation of modern Approximate Nearest Neighbor. it provides a significant speedup in nearest neighbors search for massive datasets. As an implementation of ANN, ScaNN uses an approximation algorithm called Tree-AH to find the nearest neighbor because it is often impossible to find the actual nearest neighbor in a reasonable amount of time when dealing with millions of data points.
In Vertex AI Matching Engine, an index is used to store and retrieve embedding vectors based on their similarity scores. This structure enables Vertex AI Matching Engine to deliver similarity search at scale, with high QPS, high recall, and cost efficiency.
Create Index
So far, we have a JSON file stored into a bucket containing all the predicted embedding vectors from our previous batch prediction jobs. To use those embeddings as the input to Vertex AI Matching Engine index creation function, you need to write the article ids and embeddings vectors to a json file with the below format.
Now, let’s create a Vertex AI Matching Engine index.
There are two algorithms that can be used to create the Vertex AI Matching Engine index. One way is to use the ANN algorithm that we have outlined before and the other option is to use the brute-force algorithm. Brute-force uses the naive nearest neighbor search algorithm (linear brute-force search). It is inefficient hence it is recommended to not be used in production. It serves as the ground truth and the neighbors retrieved from it can be used to evaluate the index performance.
When creating an index, we also need to specify whether it supports batch or stream update. Batch update is used to update a large number of items at once, whereas stream update is used to update items as they arrive (more detail in batch vs stream update)
In the below scripts, the bruteforce and stream_update flags allow us to alternate between these choices. The list of parameters to set are:
display_name: The human readable name of the index.
contents_delta_uri: the URI of the gcs buckets that contains the data(embedding vectors) for the index.
dimensions: the dimensionality of the embedding vectors.
approximate_neighbors_count: the number of neighbors included in approximate search before reordering. Increasing this value increases the latency in query time due to reordering the results from multiple trees.
distance_measure_type: the type of distance measure to use for the index.
leaf_node_embedding_count: the number of embeddings on each leaf node in the tree.
leaf_nodes_to_search_percent: the percentage of leaf nodes to search for any query.
description: a description of the index.
Deploy Index
Once the Index has been created (the number of vectors will affect how long it takes to be created), it has to be deployed on an endpoint in order to make queries and retrieve the nearest neighbors of new embedding vectors.
Before deploying the index, set up VPC network peering connection and enable private service access to make vector matching online query with low latency. This is a one-time setup. You can reuse an existing VPC.
The below code snippet deploys the created Index to a Vertex AI Matching Engine endpoint. Now, the endpoint is private and the caller has to be in the same network as the Index (there is no public endpoint for Vertex AI Matching Engine service at this moment). The below parameters are required to deploy the Index to an endpoint.
vpc_network is the ID of the deployed index.
Query Index
Now let’s query the index using a new and unseen article. Let’s assume we’re given a new article and we extract the embeddings. For real-time or online embedding prediction, we need to deploy the registered embedding model in Vertex AI to an endpoint using ‘aiplatform.Endpoint.create’.
Here we query for 10 most similar articles.
Candidates_embedding: the embedding vector of the new article for which we want to query neighbors.
Update index
When the index is deployed, we can update it using batch or stream updates. Batch update lets you update the index through a batch schedule. With stream updates, you can update and query the index within a short amount of time (few seconds).
New records are stored in memory as separate indexes, which can be queried. This allows for a more streamlined process and more flexibility when updating a few records. In this method, the rebuilding of the index, also known as compaction occurs when new data or uncompacted data is > 1 GB or it is at least 3 days old (more detail on index update). To learn more about pricing, see the Vertex AI pricing page.
Real time end-to-end execution
For the real time execution, we have to run the article data into the same pipeline as described at the beginning, then use the output of the transformation to extract the embedding vector. The embedding model returns the online prediction output as a n dimension vector that can be submitted to a Vertex AI Matching Engine index to query the top K recommendations (nearest neighbors).
Finally, we can query the top K recommended article ids.
Conclusion
The Vertex AI Matching Engine offers a similarity search service in the vector space, which enables the identification of articles that share similarities and can be recommended to media writers and editors. To utilize this feature, text data must first be transformed into embedding or feature vectors, typically achieved through the use of deep neural NLP models. In this blog post, we utilized the powerful embedding capabilities of the universal sentence encoder, which has been pre-trained on Wikipedia and web resources, to convert article vectors into Vertex AI Matching Engine input vectors. These vectors were then used to generate an index and deployed to an endpoint. By using the same embedding method, editors can embed their new drafts and use the index to retrieve the top K nearest neighbors in vector space, based on returned article IDs, and access similar articles. Editors can make use of this solution as a tool for recommending articles that are similar in content.



