Google Cloud データベースを使用したエンタープライズ向け生成 AI アプリの構築
Google Cloud Japan Team
※この投稿は米国時間 2024 年 1 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
大規模言語モデル(LLM)は、幅広いトピックを網羅した一般公開されている膨大なデータコーパスに基づいてトレーニングされており、さまざまな点で便利であるものの、改善の余地もあります。
トレーニング データのサイズが大きいことから、頻繁にトレーニングするには大量のリソースが必要となり、結果として、LLM に最新の情報が反映されない場合があります。さらには、利用可能なデータに基づいてトレーニングされるため、企業のファイアウォールの内側にあるデータについては網羅しようがありません。LLM に最新のスポーツゲームの勝敗や健康保険の保険料を質問しても、その答えを知らない可能性が高いでしょう。このような制限は、一般常識の範囲の質問であれば問題ないかもしれません。しかし、企業は LLM を活用してリアルタイムの情報にアクセスし、複雑な会話エクスペリエンスをサポートできる高精度な生成 AI アプリを作成することを目指しています。
この課題に対して一般的になりつつあるアプローチが、検索拡張生成(RAG)という手法を利用した LLM の「グラウンディング」です。このアプローチは、LLM プロンプトを強化して関連性の高い正確な情報を提供することで、最新のデータや自社データを活用できる生成 AI アプリを構築する新たな機会を企業にもたらします。機密情報に関する規制を遵守しなければならない企業や業界にとって、これは特に重要です。
RAG アプローチ
在庫状況、価格、返品に関するポリシーなどの幅広い質問に答えることができるカスタマー サービス chatbot を例に、RAG の仕組みを見てみましょう。標準的な LLM に「5 歳未満の子どもに人気のあるおもちゃは何ですか?」といった一般的な質問をした場合、答えを返すことはできるでしょう。しかし、LLM は店舗の現在の在庫状況を知らないため、買い物客に対して適切な答えを返すことはできません。カスタマー サポート chatbot が最新のデータとポリシーを使用して回答できるようにするには、RAG アプローチが効果的と言えるでしょう。
ここで示す簡略的な RAG の例は、準備ステップと 4 つのステップで構成され、ベクトル インデックスをサポートするデータベースの類似検索機能を利用して、アプリが確かな情報に基づく回答を提供するプロセスの流れを示しています。
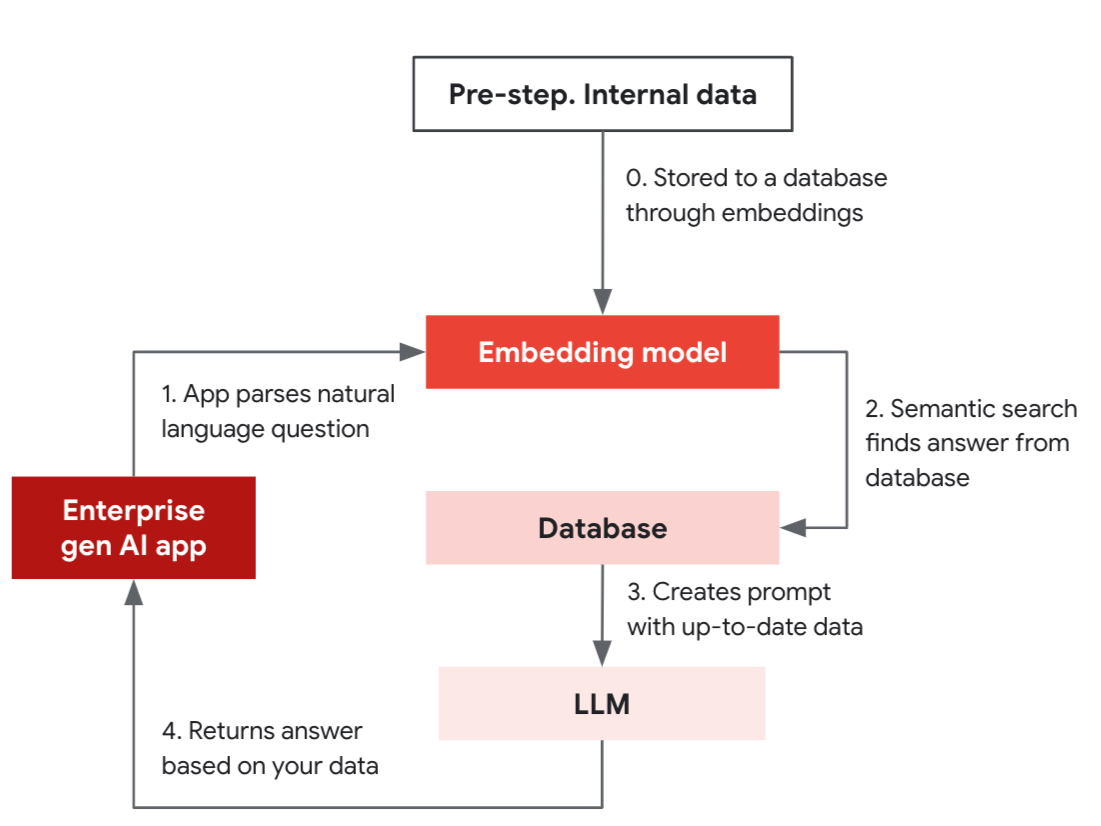
準備ステップ: 内部データが、エンべディング モデルを使用してデータベースに保存されます。
- 生成 AI アプリは、エンべディング モデルを使用して、自然言語による質問(A、B、C の機能を搭載した商品 X はありますか?)をベクトルに変換します。
- エンべディング モデルを使用すると、質問をベクトルに変換し、データベースでセマンティック検索が行えるようになります。
- データベースは LLM のプロンプトの一部として使用されるデータを返します。
- LLM はそのデータに基づいて正確な答えを生成します。
LLM とデータベースは連携してリアルタイムの結果を提供します。最初の設定では、商品説明などの内部データを、エンべディング モデルを使用してベクトルとして運用データベースに保存します。これにより、アプリはデータに基づいて検索し、最新の正確な結果を提供できるようになります。この設定が完了すると、アプリはデータベースの類似検索を使用して質問に回答できるようになり、LLM のプロンプトを組み合わせて適切な回答を提供できます。
エンべディングでは、近似最近傍述語を使用して、類似性に基づいてデータをフィルタできます。このようなタイプのクエリにより、商品のレコメンデーションなどの機能が実現可能になり、以前なんらかのインタラクションのあった商品と類似した商品を検索できます。そのため、プロンプトの作成に使用すると、LLM がより強力になります。というのも、LLM 自体には入力サイズに上限があり、状態の概念もないため、プロンプト内で完全なコンテキストを常に提供できるとは限らないからです。したがって、エンべディングを使用することで、データベース、ドキュメント、チャット履歴などの大規模なコンテキストを検索することが可能になり、長期記憶をシミュレートし、ビジネス特有の知識を理解できるようになります。
ベクトル データベース
RAG アプローチの重要な要素は、ベクトル エンベディングを使用することです。Google Cloud は、ベクトル エンベディングを保存するためのオプションをいくつか提供しています。Vertex AI ベクトル検索は、ベクトルを大量かつ低レイテンシで保存し取得するための専用ツールです。PostgreSQL を使い慣れているのであれば、pgvector 拡張機能を使用すると、ベクトルクエリをデータベースに簡単に追加して、生成 AI アプリケーションをサポートできます。Cloud SQL と AlloyDB は pgvector に対応しており、AlloyDB AI は、IVFFlat インデックス モードを使用した場合、標準の PostgreSQL と比較して最大 4 倍のベクトルサイズと最大 10 倍の高速パフォーマンスを実現します。
エンタープライズ向け生成 AI アプリの構築は難しいように思われるかもしれませんが、LangChain のようなオープンソース対応のツールを利用し、Google Cloud のリソースを活用することで、この投稿で説明した概念とツールを用いて簡単に構築を始めることができます。Cloud SQL と AlloyDB で pgvector を使用する方法について詳しくは、こちらのブログをご覧ください。
-Google Cloud、プロダクト管理担当 Sean Rhee




