AutoML Tables を使用してワークロードの失敗を事前に予測する
Google Cloud Japan Team
※この投稿は米国時間 2020 年 6 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
高性能コンピューティングと高スループット コンピューティングの世界的なコミュニティは、大規模な研究機関から構成されています。こうした研究機関は、数百ペタバイトのデータを格納し、年間数百万のコンピューティング ワークロードを実行しています。また、世界中に分散しているデータセンターの相互接続網にアクセスすることもできます。そのため、研究者はリソースを使用可能なサイトで、テスト用のコンピューティング ワークロードをスケジュール設定して実行できます。
ほとんどのワークロードは成功しますが、10~15% のワークロードは最終的に失敗し、時間の損失、コンピューティング リソースの不適切な使用、研究費の浪費といった結果に終わります。ワークロードが失敗する原因は、コマンドの誤入力、メモリの要求、時間帯などさまざまです。ワークロードが失敗した場合は失敗のタイプごとに一意の情報が格納されるため、研究者はそれをワークロードの実行に役立てることができます。たとえば、メモリが原因でワークロードが失敗する可能性があることを機械学習(ML)モデルが予測した場合(Run-Held-Memory クラスを予測した場合)、研究者はメモリの要件を調整し、リソースを無駄にすることなく、ワークロードを再送信できます。
AI を使用してワークロードの失敗を効果的に予測することで、研究コミュニティではインフラストラクチャ費用を最適化し、CPU サイクルの浪費を削減できます。この投稿では、研究者がワークロードを実行する前にこうした失敗を予測できるよう、AutoML Tables を活用する方法について説明します。
7,300 万のイベントの処理
私たちは、各行が 1 つのワークロードを表す 7,300 万行以上の年間データセットを使用して、失敗する可能性があり、網内で処理すべきでないワークロードを予測するために AutoML Tables を活用できるか確認することにしました。失敗する可能性があり、実行すべきでないワークロードを予測できれば、リソースを解放し、CPU サイクルを浪費せずに済むため、研究費を効率よく使うことができます。
4 行分のサンプル データセットを以下に示します。
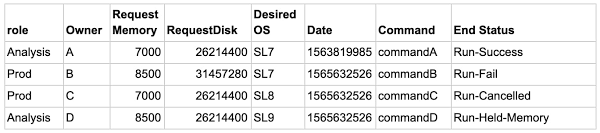
予測する特徴は End Status です。このサンプルでは、End Status は 10 個の値(クラス)のいずれかです。これには、Run-Fail、Run-Success、Run-Cancelled、Run-Held-Memory などが含まれます。また、成功した実行の数は失敗した数を上回ります。 このような状況において、ML モデルは通常、よくあるイベント(成功)を適切に予測しますが、まれなイベント(失敗)を予測できないことがあります。
私たちは、最終的にいずれのタイプの失敗も正確に予測したいと考えています。ML の用語で表現すると、マルチクラス分類モデルを使用し、各クラスの再現率を最大化する必要があります。
データ例外がある場合の手順

単純なアプローチから始めましょう。BigQuery を使用したエンタープライズ クラスのソリューションについては、今後の投稿で取り上げます。
通常、同種の問題を解決する場合は、Cloud Storage に保存された CSV ファイルを最初に使用します。最初のステップは、Google Cloud の AI Platform Notebooks にファイルを読み込み、Python を使用して初期データ探索を行うことです。
まれなイベントを予測する場合、一部のクラスの桁数は他と比べて多くなる傾向にあります(「クラスの不均衡」と呼ばれます)。
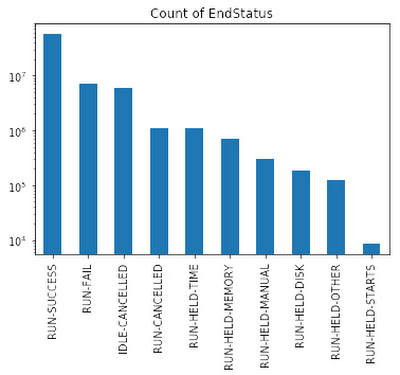
そのようなデータセットでトレーニングされたモデルは、最も一般的なクラスを予測し、その他を無視します。これを修正するには、支配的なクラスのアンダーサンプリングと重み付けの技術を組み合わせて使用します。データセットの各行の重み付けを計算してから、各クラスについて同数のデータポイントを持つデータセットのサブセットを生成するコードを以下に示します。
AI Platform Notebooks を使用して前処理を行った後、以下に示すように、結果のデータセットを BigQuery にエクスポートし、それを AutoML Tables のデータソースとして使用できます。
AutoML Tables のメリット
Google Cloud で新しい ML の問題を処理する場合、AutoML モデルを利用できます。これを行うには、前処理済みのデータセットを BigQuery から AutoML Tables にインポートし、ターゲット ラベル(この例では、EndStatus)の列を指定して、重み付けを割り当てます。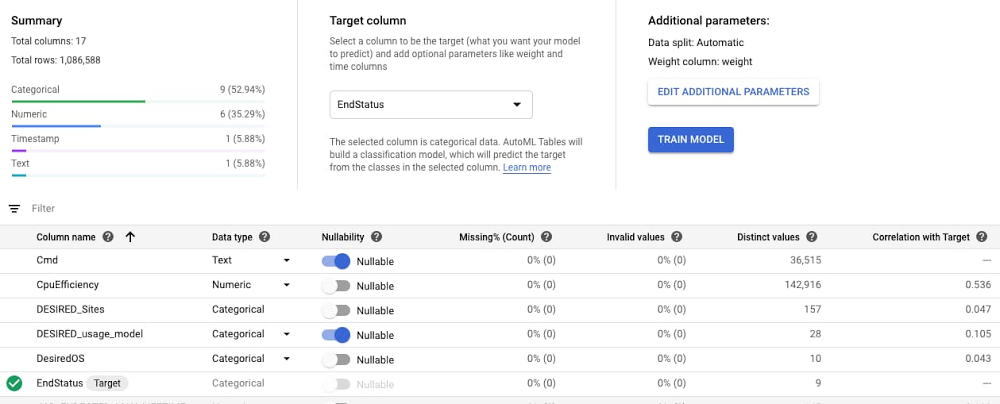
デフォルトの自動データ分割では、トレーニングに 80%、検証に 10%、テストに 10% が使用されます。また、推奨トレーニング時間はデータセットのサイズに基づきます。AutoML は必要な特徴量エンジニアリングを実行し、さまざまな分類アルゴリズムを検索し、パラメータを調整してから、最適なモデルを返します。アルゴリズムの検索プロセスは、ログを確認することで追跡できます。このユースケースでは、AutoML によりマルチレイヤ ニューラル ネットワークが推奨されました。
バイナリモデルを選択した理由

予測を改善するために、複数の ML モデルを使用できます。たとえば、まず、問題を簡素化してバイナリなものにできるか確認します。このユースケースでは、成功していないすべてのクラスを失敗クラスに集約できます。
私たちは、以下に示すように、まずバイナリモデルを使用してデータを実行しました。予測が成功であれば、研究者はワークロードを送信できます。予測が失敗であれば、2 つ目のモデルをトリガーして、失敗の原因を予測します。その後、研究者にメッセージを送信し、ワークロードが失敗する可能性があること、また、先に進む前に送信をチェックする必要があることを伝えることができます。

結果
トレーニングが終了し、最適なモデルが用意された後、AutoML Tables によって混同行列が提示されます。以下の混同行列は、Run-Success ワークロードの 88%、Run-Fail ワークロードの 87% がモデルによって正確に予測されたことを示しています。
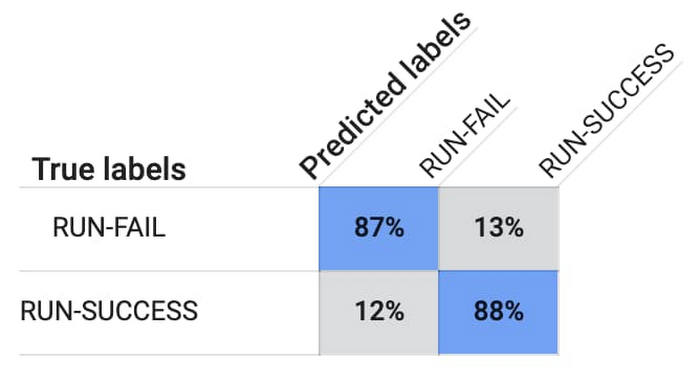
ワークロードが失敗する可能性があることがモデルによって予測された場合、偽陰性の結果を回避し、潜在的な失敗の原因を研究者に提供するために、私たちはマルチクラス分類モデルを使用してワークロードを実行します。
マルチクラス モデルは、ワークロードが失敗する原因(ディスク スペースやメモリの問題など)を予測し、ワークロードが失敗する可能性があることを研究者に通知します。
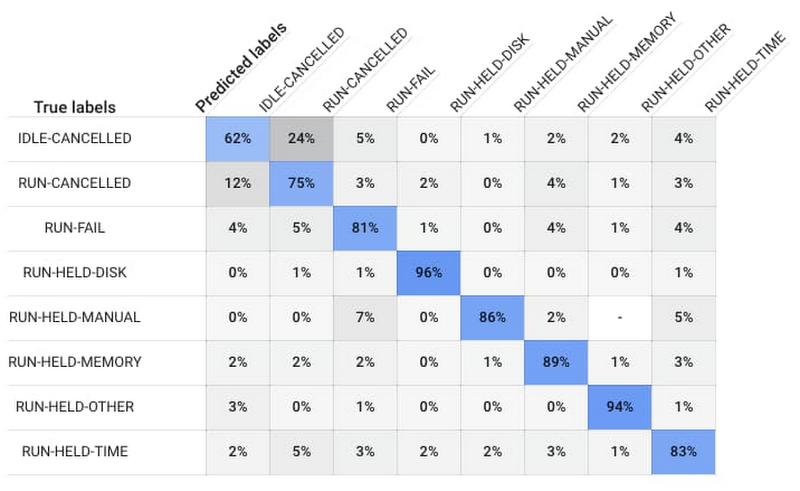
完全なモデルは存在しません。また、予測が常に困難なケースもあります。たとえば、ユーザーが手動でジョブをキャンセルするタイミングを予測することは困難です。
結果が満足なものであれば、AutoML Tables コンソールから直接、または Python ライブラリを介してモデルをデプロイできます。モデルはマネージド クラスタでコンテナとして実行されます。また、公開される REST API に対して、直接クエリを実行することも、サポートされているクライアント ライブラリ(Python や Java など)から実行することもできます。
デプロイしたモデルでは、オンライン予測とバッチ予測の両方がサポートされます。オンライン予測は、入力として JSON オブジェクトを必要とし、JSON オブジェクトを返します。バッチ予測は、BigQuery テーブルまたは Cloud Storage の CSV ファイルとして入力データセットの URL を取得し、BigQuery または Cloud Storage に結果を返します。
ここで説明したモデルをオンプレミス ワークロードの処理ワークフローに組み込むと、成功する可能性のあるワークロードのみを処理できるようになるので、オンプレミス インフラストラクチャの費用を最適化しながら、有意義な情報をユーザーに提供できます。
次のステップ
ぜひお試しください。Google Cloud に登録すると、AutoML Tables や BigQuery の一般公開データセットを使用して、金融詐欺などのまれなイベントの予測が可能になります。また、このシリーズのパート 2 では、AutoML Tables や BigQuery を使用してマルチクラス分類モデルをエンタープライズ規模で実装する方法について説明する予定ですので、ぜひご注目ください。
- カスタマー エンジニア Giovanni Marchetti、ソリューションズ コンサルタント Ema Kaminskaya



