Predict workload failures before they happen with AutoML Tables
Giovanni Marchetti
Customer Engineer
Ema Kaminskaya
Solutions Consultant
The worldwide High Performance and High Throughput Computing community consists of large research institutions that store hundreds of petabytes of data and run millions of compute workloads per year. These institutions have access to a grid of interconnected data centers distributed across the globe, which allows researchers to schedule and run the compute workloads for their experiments at a grid site where resources are available.
While most workloads succeed, about 10-15% of them eventually fail, resulting in lost time, misused compute resources, and wasted research funds. These workloads can fail for any number of reasons—incorrectly entered commands, requested memory, or even the time of day—and each type of failure contains unique information that can help the researcher trying to run it. For example, if a machine learning (ML) model could predict a workload was likely to fail because of memory (Run-Held-Memory class is predicted), the researcher could adjust the memory requirement and resubmit the workload without wasting the resources an actual failure would.
Using AI to effectively predict which workloads will fail allows the research community to optimize its infrastructure costs and decrease wasted CPU cycles. In this post we’ll look at how AutoML Tables can help researchers predict these failures before they ever run their workloads.
Journey of 73 million events
With an annual dataset consisting of more than 73 million rows, each representing a workload, we decided to see if AutoML Tables can help us predict which workloads are likely to fail and therefore should not be processed on the grid. Successfully predicting which workloads will fail—and shouldn’t be run at all—helps free up resources, reduces wasted CPU cycles, and lets us spend research funds wisely.
Here’s a sample dataset of four rows:
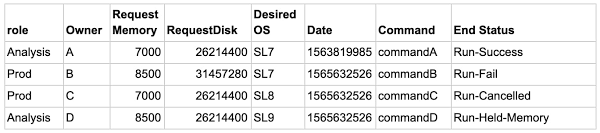
The feature we’re predicting is End Status. In this sample, End Status can take one of 10 values (aka classes), including Run-Fail, Run-Success, Run-Cancelled, Run-Held-Memory, and so on, and there are more successful runs than failed ones. In these situations, ML models usually predict common events (e.g. successes) well, but struggle to predict rare events (e.g. failures).
We ultimately want to accurately predict each type of failure. Using ML terminology, we need to use a multi-class classification model and maximize recall for each of the classes.
I have a data anomaly, where do I start?

Let’s start with a simple approach. We’ll discuss an enterprise-grade solution using BigQuery in future posts.
When solving similar types of problems, you often start with a CSV file saved in Cloud Storage. The first step is to load the file into an AI Platform Notebook on Google Cloud and do initial data exploration using Python.
|
When predicting rare events, you’ll often see that some classes are orders of magnitude more represented than others—also known as a class imbalance.
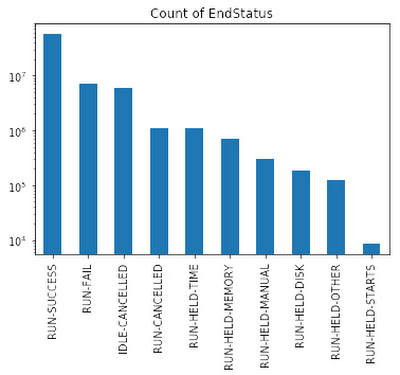
A model trained on such a dataset will forecast the most common class and ignore the others. To correct this, you can use a combination of undersampling of dominant classes and weighting techniques. Below is the code that computes weights for each row in the dataset and then generates a subset of the dataset with an equal number of datapoints for each class.
After pre-processing using AI Platform Notebooks, you can export the resulting dataset to BigQuery, as shown below, and use it as a data source for AutoML Tables.
The magic of AutoML Tables
When you’re getting started with a new ML problem on Google Cloud, you can take advantage of AutoML models. To do this, you’ll import the pre-processed dataset from BigQuery to AutoML Tables, specify the column with the target labels (EndStatus in our example), and assign the weight.
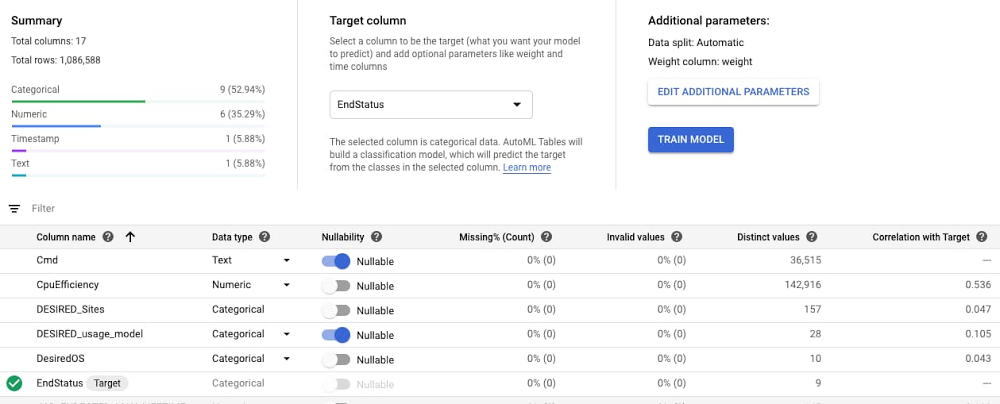
The default automatic data split is 80% training, 10% validation, 10% test, and the suggested training time is based on the size of the dataset. AutoML performs the necessary feature engineering, searches among a variety of classification algorithms and tunes their parameters, and then returns the best model. You can follow the algorithm search process by examining the logs. In our use case, AutoML suggested a multi-layer neural network.
Why use one model when you can use two?

To improve predictions, you can use multiple ML models. For example, you can first see if your problem can be simplified into a binary one. In our case, we can aggregate all the classes that are not successful into a failure class.
We first run our data through a binary model, as shown below. If the forecast is successful, the researcher should go ahead and submit the workload. If the forecast is failure, you trigger the second model to predict the causes of failure. You can then send a message to the researcher informing them that their workload is likely to fail and that they should check the submission before proceeding.

Results
After training is over and you have the best performing model, AutoML Tables will present you with a confusion matrix. The confusion matrix below tells you that the model predicted 88% of Run-Success and 87% of Run-Fail workloads accurately.
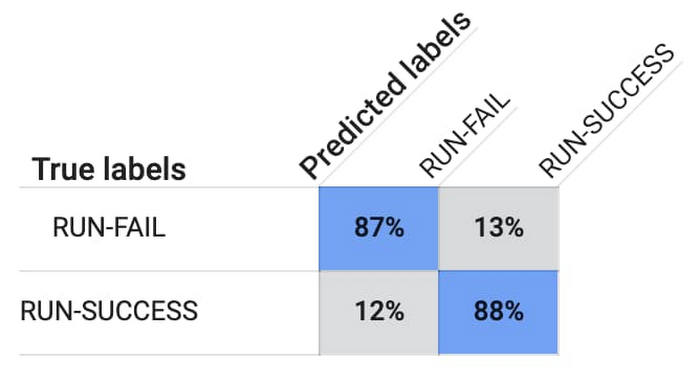
If the model predicts that the workload is likely to fail, to avoid a false negative result and provide the researcher with the cause of a potential failure, we run the workload through a multi-class classification model.
The multi-class model will then predict why the workload will fail, for example because of disk space or memory issues, and inform the researcher that the workload is likely to fail.
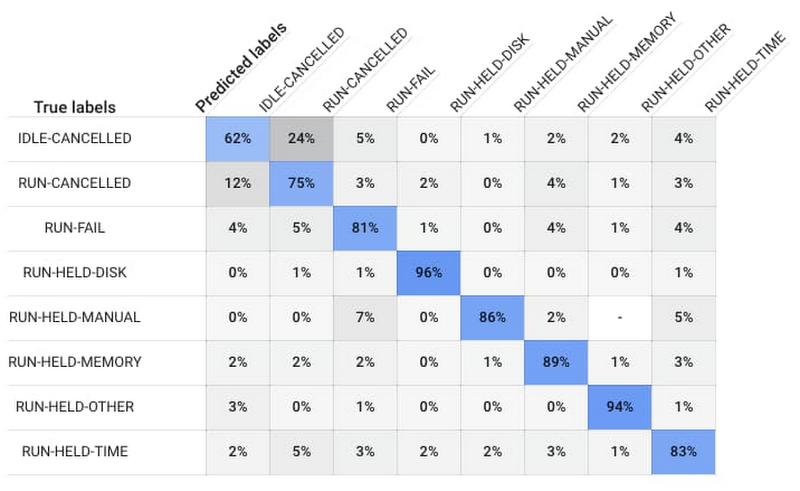
There is no perfect model, and some cases will always be harder to predict than others. For instance, it’s difficult to predict when a user decides to cancel a job manually.
When you’re happy with the results, you can deploy the models directly from the AutoML Tables console or via the Python library. Models run as containers on a managed cluster and expose a REST API, which you can query directly or via one of the supported client libraries, including Python or Java.
The deployed model supports both online and batch prediction. The online prediction will require a JSON object as input and will return a JSON object. The batch prediction will take a URL to an input dataset as either a BigQuery table or a CSV file in Cloud Storage and will return results in either BigQuery or Cloud Storage respectively.
Incorporating the model described here into your on-premises workload processing workflow will let you process only the workloads that are likely to succeed, helping you optimize your on-premises infrastructure costs while providing meaningful information to your users.
Next Steps
Want to give it a try? Once you sign up for Google Cloud, you can practice predicting rare events, such as financial fraud, using AutoML Tables and a public dataset in BigQuery. Then, keep an eye out for part two of this series which will describe an enterprise-grade implementation of a multi-class classification model with AutoML Tables and BigQuery.



