〜AutoMLで実践する〜 ビジネスユーザーのための機械学習入門シリーズ 【第 4 回】AutoML のための ML デザイン

尾崎 隆
Google ビジネス インサイト & アナリティクスチーム データサイエンティスト
機械学習の根幹をなす、理論やアルゴリズム、さらにはプログラミングによる実装技術などは日進月歩の勢いで進歩しており、AutoML もまたその進歩が結実したものとも言えます。しかしながら、これほどまでに機械学習そのものが進歩しているにもかかわらず、実務の現場ではなかなか機械学習による成果を出せないケースが少なくないようです。
テクノロジー業界には、”Garbage in, garbage out” というあまりにも有名な格言があります。これは、機械学習という文脈からは「ゴミのようなデータ・モデル・実践方法から返ってくるのはゴミだけである」とも解釈できます。実務上の成果につながらない機械学習の中には、まさにそのようなシチュエーションに陥っているものも少なくないのではないでしょうか。
機械学習の実践においては、理論面・技術面での取り組みに加えて、それらを確かならしめるための「メタ」な枠組みも必要とされます。代表的なものとして汎化性能の概念や、適切な交差検証といったものが挙げられます。この記事では、それらのメタな枠組みを総称し、統計学における実験計画法 (Experimental Design) になぞらえて「ML デザイン」という概念にまとめています。
ML デザインはまだまだ発展途上の概念であり、なおかつ現状ではそこまで広く浸透している考え方ではありませんが、必ずしも理論やアルゴリズム、もしくはプログラミング実装の知識がなくとも機械学習を実践できる AutoML 時代においては、機械学習を利用する全ての人が知っておくべき枠組みであると、私たちは位置付けています。
この記事では、そんな AutoML 時代において重要な ML デザインがどのようなものであるかを、10のポイントに分けて詳説していきます。
目的変数の性質と最適化のターゲット
機械学習においては、まず大前提として機械学習モデルに「何をさせたいか」という「目的」を決める必要があります。これは AutoML であっても同じことが言えます。一般に、目的変数(従属変数)ないし学習ラベルに何を選ぶかによって自ずと機械学習モデルの形が変わってきます。
目的変数がカテゴリを表す場合、すなわちサンプルをクラス0 vs. クラス1のように二値クラスに分けるものや、はたまた A, B, C, D, E… のように複数クラスに分けるようなものであるケースでは、分類 (classification) モデルが適用されます。
分類モデルは、イメージとしてはサンプル同士の間に「出来るだけサンプルの各クラスへの割り振りが間違わないように」決定境界を引いて分類するというものです。この決定境界の引き方に工夫を凝らすのが機械学習の醍醐味と言っても過言ではないでしょう。
これに対して目的変数が連続値の場合、すなわち売上高が100万円とか1000万円というような連続する数値であるケースでは、回帰 (regression) モデルが適用されます。
回帰モデルは、イメージとしてはサンプル同士を巧みにつないで近似曲線(曲面)を引くというものです。重要な点として、分類モデルとは違って「出来るだけサンプルと近似曲線(曲面)との距離が離れないように」するという点が挙げられます。
分類モデルであれ、回帰モデルであれ、機械学習モデルは一般に
仮に置いたモデルを学習データに当てはめる
モデルをデータに当てはめた結果と実際のデータとの誤差を測定する
誤差を小さくする方向にモデルのパラメータを変更する
1に戻る
という作業を任意の回数繰り返します。これは数学的には「最適化計画」を解いていることと同じであり、機械学習においてはその最適化のターゲットをどう選ぶかも重要になってきます。
例えば分類モデルにおいては、最適化のターゲットとして対数損失 (log loss) や交差エントロピー (cross entropy) といった「サンプルの各クラスへの割り振りが間違っている度合い」を選び、これを最小化するような最適化計画を解くことが多いです。AutoML では対数損失や交差エントロピーも選択できますが、デフォルトの設定では一般的な分類性能を表す指標である AUC ROC (Area Under the Curve of Receiver Operating Characteristic) をターゲットにするようになっています。
一方回帰モデルにおいては、最適化のターゲットとして RMSE(Root Mean Square Error: 二乗平均平方根誤差)のような「サンプルが近似曲線(曲面)から離れている度合い」を選び、これを最小化することが多いです。AutoML ではデフォルトとして RMSE が選択されますが、他にも MAE(Mean Abusolute Error: 平均絶対誤差)なども必要に応じて選べます。
これらの詳細については AutoML Tables の「モデルのトレーニング」に関するドキュメントをご覧ください1。
特徴量の性質
特徴量(説明変数)にどのような値を用いるかは機械学習において重要なポイントです。一般に、大半の特徴量は以下の2通りのいずれかに分けられます。
カテゴリ型変数
数値型変数
カテゴリ型変数には、「過去に購入経験があるorない」のような Yes / No を表す二値データや、「旅行に行くとしたら世界五大陸のどれが良いか」のような A, B, C… などの複数分類データが当てはまります。
これに対して、数値型にはそれ以外の「長さ」「重さ」「売上高」のような連続値を取るデータが当てはまります。
AutoML Tables では、原則として全ての特徴量に対してこのカテゴリ型と数値型のいずれであるかを自動的に判別し(ユーザー側で明示的に指定することもできます)、必要に応じて以下のような特徴量エンジニアリングをモデル学習時に実行します2,3。
数値の特徴を正規化し、バケット化する。
カテゴリ特徴のワンホット エンコーディングと埋め込みを作成する。
テキストの特徴の基本処理を実施する。
タイムスタンプ列から日付および時刻に関連する特徴を抽出する。
いずれもモデル学習時に予測精度を高めることが知られていたり、用いるモデルによっては元の特徴量よりも扱いやすくなることが知られているデータ変換の方法です。
汎化性能と過学習
機械学習を含めて、あらゆる予測モデルにおいて最も重要なことの一つが汎化性能です。これは端的に言えば「モデルが学習データによく当てはまるだけでなく未知の新規データにもよく当てはまる」ような、モデルの一般化(汎化)の度合いのことを指します。
1. https://cloud.google.com/automl-tables/docs/train?hl=ja#opt-obj
2. https://cloud.google.com/automl-tables/docs/features
3. https://cloud.google.com/automl-tables/docs/data-best-practices#tables-does
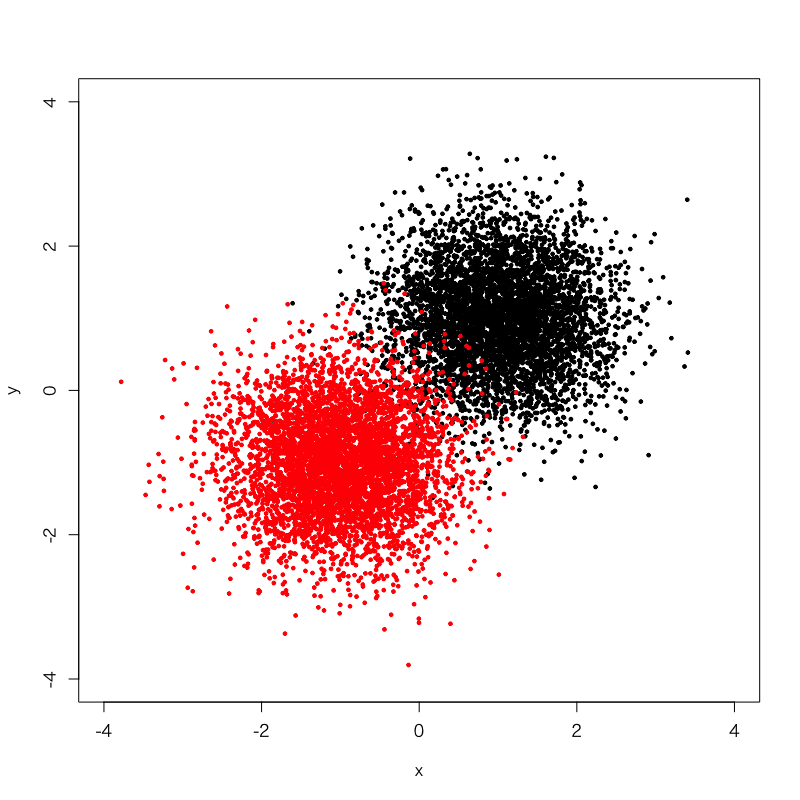
例えば、このような赤と黒の点で示されたサンプルがあるとしましょう。それぞれ、概ね第4象限と第1象限に分布するように、二次元正規分布に従う乱数を用いて生成したデータです。赤と黒がそれぞれ同じグループに属するとした場合、この2つのグループの間に適切な境界線を引くとしたらどのような境界線を引くべきでしょうか。
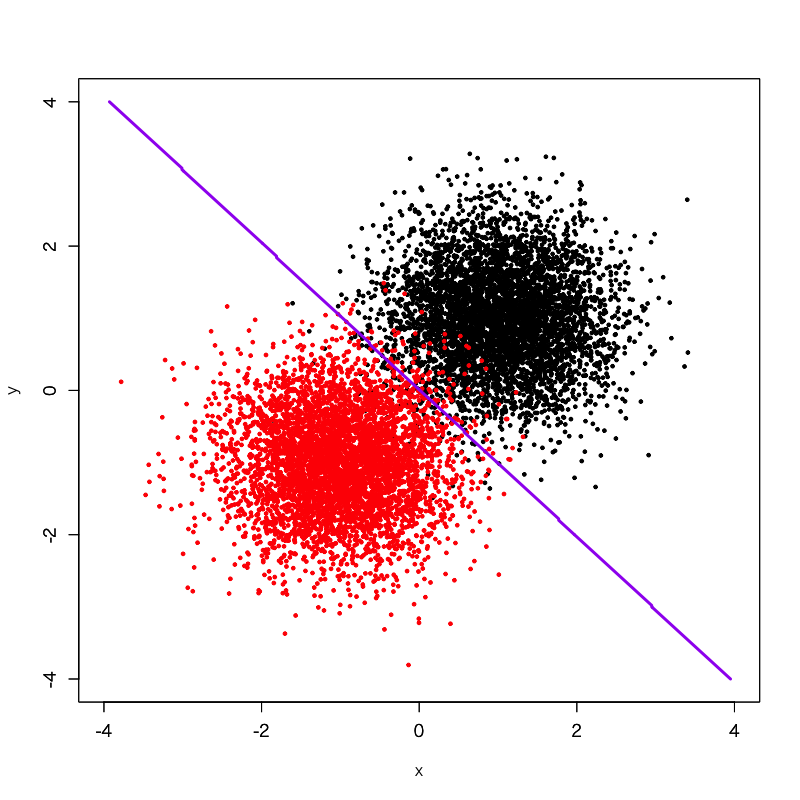
素朴に考えれば、このようにちょうど赤と黒のグループの真ん中を通るような直線を引くのが妥当でしょう。実際、これはロジスティック回帰というシンプルな機械学習モデルを使って境界線を引いてみた例です。
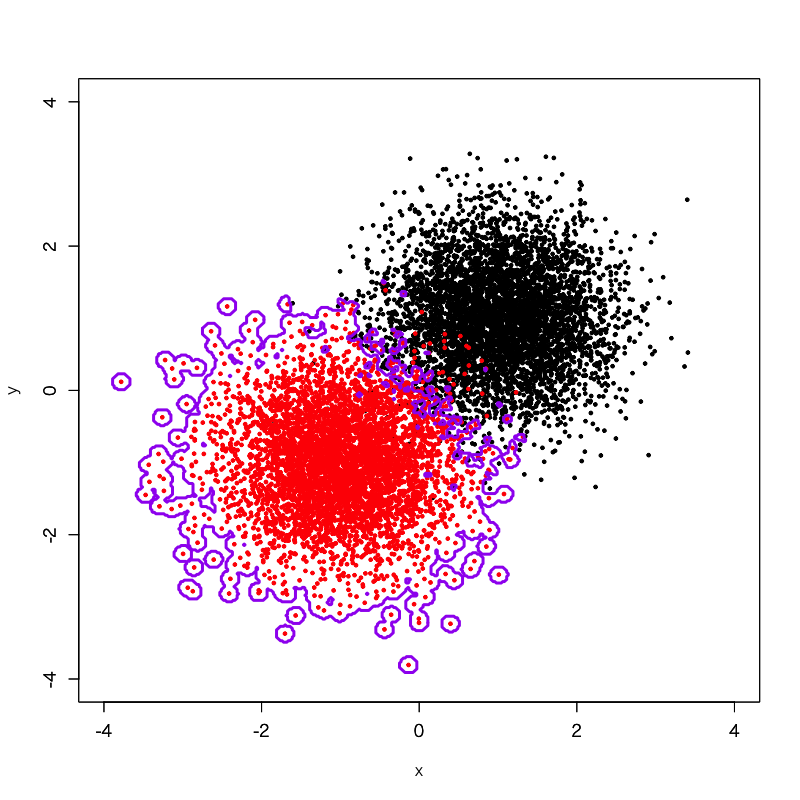
ところが、別の非線形な機械学習モデルを使い、さらに極端なパラメータ設定を与えて、境界線を引いてみるとこうなります。この境界線は確かに赤と黒のグループを互いに分けていますが、一方で赤のグループがなす凸凹にまでぐにゃぐにゃとフィットしてしまっています。本来、この凸凹にフィットすることは赤と黒のグループを互いに分ける上では何の意味もなく、そもそもこの凸凹は一種のノイズであるとも言えます。にもかかわらず、この境界線はそのノイズに過ぎない凸凹にまでフィットしてしまっているというわけです。これでは、例えば赤のグループの左下方向の僅かに外側に離れた位置に新たに点を加えたとしても、明らかに第4象限にあるにもかかわらず「黒」と判定されてしまうことになります。これは元々のデータの分布を考えると明らかにおかしな結果です。
このように、真のシグナルどころかノイズにまでモデルがフィットしてしまっている状態のことを過学習 (overfitting) もしくは過剰適合と呼びます。過学習してしまっているモデルは、学習データへの当てはまりは非常に良いのですが、未知データへの当てはまりが悪くなります。よって、機械学習モデルを学習させる際には過学習を避けつつ、尚且つ未知データへの当てはまりが可能な限り良くなる(汎化する)ように学習パラメータの調整をしていき、モデルの汎化性能を確保しなければいけません。これを実現する方法が、交差検証です。
交差検証
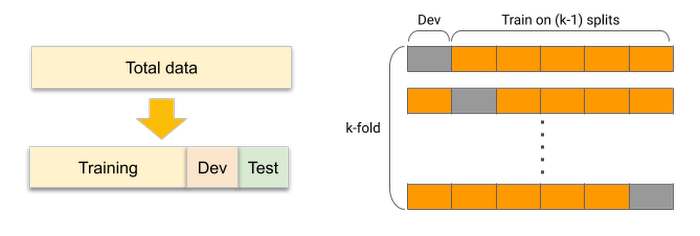
過学習が「学習データへの当てはまりが良過ぎて未知データへの当てはまりが悪くなる」ことによって起きるものであるならば、「学習データから擬似的に未知データを作り」「その擬似的な未知データへの当てはまりが良くなる(汎化する)ようにモデル学習のパラメータを調整する」ことで、これを回避できると共に汎化性能を高められるものと期待されます。
この枠組みのことを「交差検証」 (cross validation) と呼びます。一般に、学習データ全体を Training / Dev / Test の3つのパートに分け、
Training データで機械学習モデルの学習を行い、そのモデルを Dev データに当てはめた(予測した)際のスコアをモニタリングしながら学習パラメータを調整する、という作業を繰り返して機械学習モデルの汎化性能を向上させていく
Test データは独立した評価用データとして取り置き、最終的に得られた機械学習モデルの性能評価に用いる
という手順を踏みます。特にモデル学習においては汎化性能を高めるために Training + Dev データの組み合わせをランダムサンプリングして何度も繰り返すことが多く、代表的な手法としては k-fold 交差検証があります。これは学習データ全体を k 個のグループ (fold) に分割し、そのうち1個を Dev データとして選び、残りの k-1 個を Training データとしてモデルの学習に使い、これを Dev データに選ぶ fold をスライドさせていきながら k 回繰り返す(1エポック当たり)というものです。ここで k をサンプルサイズ全体にまで拡大し、毎回 Dev データとして1サンプルのみ選ぶものを特に LOO(Leave-One-Out: 「一つ抜き」の意)交差検証と呼びます。
実際には層化 (stratified) k-fold 交差検証のような手法が必要になることがあります。これは多クラス分類課題において単純にランダムサンプリングすると Dev データの中に含まれるクラス数に偏りが出てしまうのを防ぐため、各々の fold に含まれるクラス数とその割合が揃うように予め調整しておくものです。この他にも fold 内での偏りを避けるための交差検証手法は複数ありますので4、扱う課題に応じて適切に手法を選ぶ必要があります。
AutoML Tables では、特に皆さん自身が意識しなくとも自動的に交差検証が行われます5。デフォルトではランダムサンプリングを行うことで、Training / Dev / Test データにそれぞれ80%, 10%, 10%の割合でインポートされたデータを分割します。ただし、現在の AutoML Tables の仕様では層化サンプリングの機能がないため、層化 k-fold 交差検証をはじめとして追加の設定が必要な交差検証を行いたい場合には、データ分割列を元データに追加した上で、個々の行(サンプル)を TRAIN / VALIDATE / TEST / UNASSIGNED のいずれかに手動でランダムにラベリングして割り振る必要があります。
4. 『Kaggleで勝つデータ分析の技術』(門脇 大輔, 阪田 隆司, 保坂 桂佑, 平松 雄司: 技術評論社, 2019年)
5. https://cloud.google.com/automl-tables/docs/prepare?hl=ja#split
Early stopping
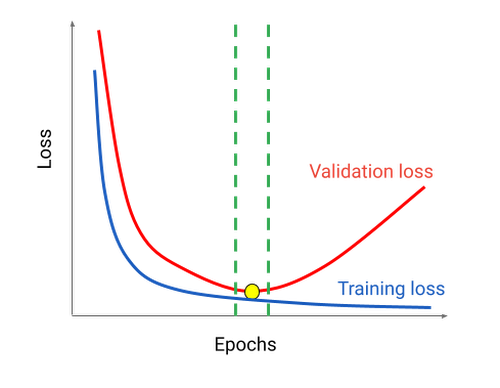
交差検証は「データ構成の観点から過学習を避けて汎化性能を確保する」ための枠組みですが、一方で過学習がモデル学習のどのフェーズで生じるかについても考える必要があります。
例えば、ニューラルネットワークにおいて学習データの繰り返し読み込み回数(イテレーション・エポック数)が過剰である、という場合について考えてみましょう。
このような場合、学習誤差 (Training loss) は下がり続けますが、Dev (Validation) データに対する交差検証誤差 (Validation loss) は途中から増えてしまいます。この状態を放置したままモデルの学習を続けると過学習に繋がります。
そこで過学習を避けるために、学習データに対する学習を進めながら同時に Dev データに対する交差検証誤差をモニタリングし、これが下がらなくなったら学習を打ち切る必要があります。この手順を Early Stopping(早期停止)と呼びます。AutoML Tables においてもこの機能がデフォルトで ON に設定されており、過学習を避けるようになっています6。
リーク (Leakage)
機械学習モデルの予測精度が低くなってしまう現象の一つとして、リーク (Leakage) というものがあります。語源に従って言えば、これは Dev / Test データの中にあるべき変数が学習データの側に漏れてしまっている、つまり leak してしまっていることです。
リークには様々な原因があります。例を挙げると、
Dev / Test データが学習データに混入する。
正しい予測値や(既知の)真の値が Dev / Test データに混入する。
未来の情報を過去に混入させる。
意図的に難読化・無作為化・匿名化されたデータを復元したものを含める。
モデルの運用環境に存在しないデータを含める。
学習データに加えられた第三者のデータに上記のいずれかが存在する。
などといった理由が考えられます7。
6. https://cloud.google.com/automl-tables/docs/train?hl=ja#training_a_model
7. https://www.kaggle.com/alexisbcook/data-leakage など

例えばプロテニス選手のプレー統計から勝敗を予測するモデルに、「選手の名前」を変数に入れてしまうというのは分かりやすい例かと思います。この場合、暗黙のうちに「選手同士の相性」という、本来ならモデルから予測されるべき(匿名化されたはずの)情報が学習データに紛れ込んでしまうわけです。
他にも、直接学習ラベルやその値と連動する変数を使ってしまう、というのもよくあるパターンです。これらは「本来その変数なしで学習及び予測を行い、後からテストデータに対する予測結果から照合すべき」値を先に使ってしまっているため、いわば正解を先に与えているのと同じになってしまい、不自然にモデルの分類・回帰性能が高くなります。分類課題だと100%に達することもあります。
そしてリークはデータの性質そのものが引き起こす現象であるため、どれほど AutoML Tables の設定を適切に行ってもこれを回避するには限界があります8。うまい話には裏がある、too good to be true と思われる時はリークを疑いましょう。
時系列データに固有の問題
これまではいわゆるテーブルデータを対象としてきましたが、時系列データに機械学習モデルを当てはめる場合にはまた別の問題が生じてきます。
現実の時系列データの多くは、トレンドや季節調整(周期成分)など、非線形な自己相関に由来する成分が混じってきます。端的にいえば、データサンプルひとつひとつが隣同士、さらには隣の隣同士などと強い関係性を持っているということです。
8. https://cloud.google.com/automl-tables/docs/evaluate?hl=ja#perfect_performance

そのようなデータに対して、例えば上の図のように漫然とランダム分割による交差検証を行うと、非線形な自己相関成分に由来するリークが起きてしまうことがあります。近隣の Training データのサンプルからの影響が Dev データに混入してしまうことで、不自然に予測性能が跳ね上がってしまうという結果につながりかねません。

よって、時系列データの予測モデルを構築する際は、左の図のように時系列順に前から80%, 10%, 10%となるようにデータを Training / Dev / Test に分割するか、右の図のように sliding time window split を行う、といった対処が必要です。
AutoML Tables では、時系列データに対しては左の図のタイプの交差検証を行うようになっています。ただしデータに時間列を追加した上で、Timestamp 型で個々の行について時刻を指定しておく必要があります9。
不均衡データとモデルの性能評価


性能評価と不均衡データの問題も重要なポイントです。上に挙げたのは、分類モデルにおいて基本的な性能評価に用いられる混同行列 (Confusion Matrix) と、そこから派生して用いられる各種性能評価指標です。AutoML Tables でもこれらの性能評価指標が用いられています10。
9. https://cloud.google.com/automl-tables/docs/prepare?hl=ja
10. https://cloud.google.com/automl-tables/docs/evaluate?hl=ja

例えば、こういうデータを考えてみましょう。サンプルサイズは10万。実際は正で負と予測されたサンプルが5000、実際は負で予測も負だったサンプルが9万5000。この場合、accuracy は95%に達します。
ところが、その他の性能指標を見てみると precision は0、recall も0。F1-score も0。全てが0になってしまいます(ここでは0除算は便宜上0とします)。これはいわゆる不均衡データの問題で、正例と負例の比が極端に偏ると生じるものです。この場合、モデル学習自体が強く負例側に寄ってしまうため、そもそも学習結果自体が偏ってしまいます。そこで漫然と accuracy を見てもモデル性能を評価するのは難しくなります。
実際にはこれまでに様々な不均衡データへの対処法が提案されていますので、それらの方法のいずれかで対処する必要があります。AutoML Tables では AUC PR を最適化の目標に選ぶ、もしくは weight column を用いるという方法が用意されています11。AUC PR は precision, recall のバランスを最適化するものです12。Weight column はクラス数比の逆数で最適化に重み付けをかけることで、より正例の側にモデル学習の度合いを寄せていくものです。これにより個々の行(サンプル)ごとにクラス数の偏りに応じてモデル学習の強弱をつけて、バランスを取れるようになります。
11. https://cloud.google.com/automl-tables/docs/prepare?hl=ja#weight
12. https://cloud.google.com/automl-tables/docs/beginners-guide#evaluate_your_model
特徴量の重要度の取り扱い

AutoML Tables 及び樹木モデルでは「特徴量の重要度」という形で、個々の特徴量がどれくらい目的変数にとって重要かを可視化することができます13。ただ、どのように目的変数にとって重要かは、別の分析と併せて検討する必要があります。
例えば、オープンデータであるワインのテイスティングスコアのデータセット14に対して分類モデルを推定すると、AutoML Tables は左図のような特徴量の重要度を返します。しかしながら、例えば xgboost という機械学習モデル15と SHAP (Shapley Additive Explanations) という解釈手法16を用いて特徴量と目的変数との関係性を可視化したプロットを確認してみると、正負はおろか線形に比例する関係ですらない変数があることが分かります。こういった点への注意が必要です。
13. https://cloud.google.com/automl-tables/docs/evaluate?hl=ja
14. https://archive.ics.uci.edu/ml/datasets/wine+quality
15. https://arxiv.org/abs/1603.02754
16. https://arxiv.org/abs/1705.07874
バイアスと公正性
社会的なデータを用いて機械学習システムを開発する際に重要な問題として、「バイアス」と「公正性」があります。
例えば、カメラの前に手をかざすと自動的にハンドソープを出すディスペンサーのために画像認識 AI を開発するというシチュエーションを考えてみましょう。この場合、学習データとして開発者と同じ肌の色の人たちの手の画像だけを用いてしまうと、もっと肌の色が濃い、もしくは薄い人に対しては動作しない、という事態が生じる可能性があります。
同様の問題はもっと複雑なデータを用いた機械学習でも起こり得ます。例えば、人事採用 AI を開発する際に「A という属性の候補者が過去に採用されたことがない」という過去データを用いてモデルを学習させることを考えてみましょう。この場合、A という属性の候補者が自動的に不採用になるだけでなく、それどころか A という属性の人々が勤務歴を持つことが多い B という業界の出身の候補者までもが自動的に不採用になる、ということが生じかねません。すなわち、A という属性に対する差別に加えて、B という業界出身の候補者の人々に対する差別までもが生じるということです。
データそのものに差別などのバイアスが含まれていれば、そのデータから学習した機械学習モデルもまた同様に差別などのバイアスをもたらします。そして、そのバイアスは往々にして開発者自身の意図しないところで生じ得ます。まずデータを取得する時点で、公正性に基づくバイアスの排除や補正を考える必要があります。
Google ではこれらの問題に対処する指針をまとめて「インクルーシブ ML ガイド」として公開しています17。社会的なデータに基づく機械学習システムを開発する際には、ぜひその前にご一読ください。
まとめ
以上、ML デザインにとって重要な10のポイントを挙げてみました。今後機械学習のモデル作成がどんどん自動化されていくにつれて、これらのモデルの「外」に向けられた課題意識は相対的にその重要度を増していくはずです。AutoML 時代なればこその機械学習における新たなスタンダードとして、ML デザインの考え方が広まっていくことを私たちは願っています。
この記事で挙げた ML デザインに関連する各項目についてより深く学ぶためには、例えば『はじめてのパターン認識』(平井 有三: 森北出版, 2012年)、『Kaggle で勝つデータ分析の技術』(門脇 大輔, 阪田 隆司, 保坂 桂佑, 平松 雄司: 技術評論社, 2019年)などの書籍をご参照ください。





