BigQuery を活用した新しい Vertex AI Feature Store が予測 AI と生成 AI に対応
Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
Vertex AI は、ML モデルや AI アプリケーションのトレーニングやデプロイのための Google Cloud の ML プラットフォームであり、データ エンジニアリング、データ サイエンス、ML エンジニアリングのワークフローに必要なものがすべて揃っています。このたび、これらのワークフローをサポートする、新しい Vertex AI Feature Store の公開プレビュー版がリリースされました。これにより、組織の既存の BigQuery インフラストラクチャをフル活用して、あらゆる規模の予測 AI と生成 AI のワークロードに対応できるようになりました。また、特徴量のルックアップを低レイテンシで実現する新しいリアルタイム サービング オプションも追加されます。新たに追加されたベクトル検索機能は BigQuery と直接統合されるため、特徴量ストアでエンべディングがネイティブにサポートされます。
特徴量ストアとは
特徴量ストアは、ML の入力、つまり特徴量の管理と処理のための中央リポジトリです。特徴量ストアは、エンドツーエンドの MLOps フレームワークに欠かせない要素です。特徴量ストアにより、データ サイエンティストや ML の実務担当者は、組織全体で ML の特徴量を整理し、AI / ML デプロイのサイクルタイムを短縮できます。また、ML アプリケーション用データの作成、保存、共有、検出、提供が容易かつ効率的になります。
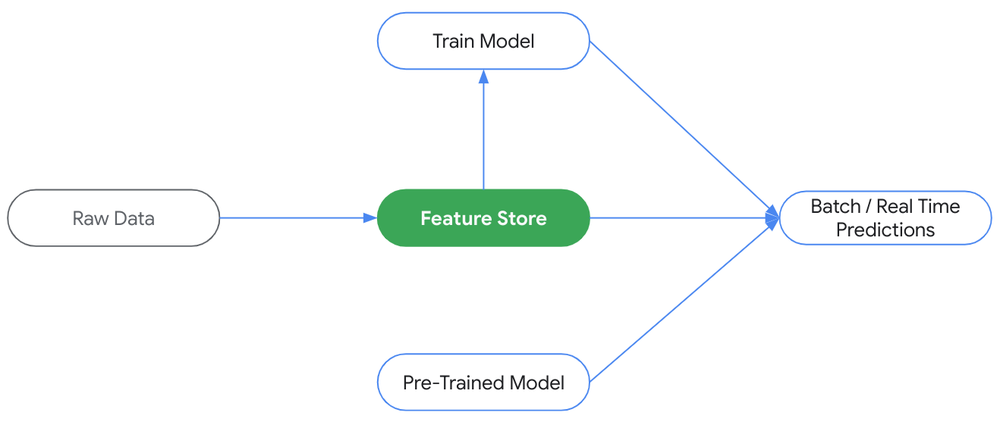
特徴量ストアは ML の中核
ほとんどの ML チームは、次の 3 つの主要な課題に対応するために特徴量ストアを導入しています。
- 特徴量の再利用と共有の欠如 - 複数のデータ サイエンス チームが同じ特徴量を再作成していると、作業の重複、不必要な保存容量やコンピューティングの費用、生産性の低下が生じます。
- オフラインとオンラインでの特徴量の不一致 - 一般に、本番環境モデルのパフォーマンスがトレーニング時ほど高くならない原因は、トレーニング時とサービング時の間のスキューです。スキューが発生するのは、トレーニング時のパイプラインとサービング時のパイプラインの間で、データの扱いに変化があった場合です。
- リアルタイムのデータ サービングは困難 - 大規模環境で低レイテンシかつ高可用性を確保しながら特徴値を提供するのは難しく、費用がかさみます。通常、複雑なインフラストラクチャを構築し、維持していくには複数のチームが必要です。
特徴量ストアは、検出のしやすさとオブザーバビリティをエクスペリエンスにもたらし、トレーニング時と予測時にデータ使用の管理とガードレールを用意し、ML データをスケーラブルかつ効率的に提供できるようオンラインのサービング データベースを管理することで、こうした課題に対応します。
次世代の Vertex AI Feature Store のご紹介
改善された新しい Vertex AI Feature Store は、主に以下の 3 つの領域にわたり、より効率的で魅力的なエクスペリエンスをユーザーに提供します。
- BigQuery を活用 - BigQuery を組織のオフライン ストアとして使用できるようになりました。企業は特徴量ストアのエクスペリエンスを既存の BigQuery インフラストラクチャに移行することで、データの重複を防ぎ、費用を削減できます。また、使い慣れたデータアクセスとガバナンスの設定とともに、BigQuery SQL の機能性と柔軟性を最大限に活用して、特徴量を取得および変更できます。
- 低レイテンシのサービング - 必要に応じてスケールできる、フルマネージド、高パフォーマンスのリアルタイム サービング インフラストラクチャを活用できるため、複雑なオンライン アーキテクチャのオーケストレーションは不要になります。Feature Store では、リクエストの 99% が 2 ミリ秒以内に完了し(社内ベンチマークによる)、Bigtable のオンライン サービングに加え、最適化された新しいオンライン サービングにより、リアルタイムのユーザー エクスペリエンスがサポートされます。任意のサイズの BigQuery データを任意の QPS で提供するために、組織がクラスタの構成やデータ同期の競合について心配する必要はありません。
- 予測 AI と生成 AI の両方に対応 - Feature Store の他の特徴量と同じように、ベクトル エンベディングを BigQuery に格納し、リアルタイム サービング用に容易にデプロイできます。BigQuery のスケーラビリティに優れたインフラストラクチャを活用して、モデルのトレーニング中、試験運用中、バッチ ワークロード中に、大規模な類似度検索を実行できます。リアルタイムの類似データの取得には、Feature Store API 内のネイティブのエンベディング手法を使用できます。追加のインフラストラクチャを設定したり、データを専用のデータベースにコピーしたりする必要はありません。あらゆる規模において、任意の QPS で極めて低レイテンシで類似値を取得できます。

BigQuery が Vertex AI Feature Store のエクスペリエンスの中心に
お客様の初期の反応
Feature Store チームは、Google Cloud の多くのお客様にご協力いただき、フィードバックを反映し、プロダクトのエクスペリエンスを改善して、シンプルさ、スピード、エンベディングのサポートを実現してきました。ご協力いただいたお客様のうち、Wayfair と Shopify からのコメントを以下にご紹介します。
「Vertex Feature Store の新機能は、我々のチームに運用面で大きな利点をもたらします。次のような分野で全体的な改善が期待されます。
- 推論とトレーニング - ネイティブの BigQuery オペレーションは高速で直感的に使用できるため、MLOps パイプラインが簡素化されるだけでなく、データ サイエンティストがシームレスに試験運用できます。
- 機能の共有 - 使い慣れた権限管理機能を搭載した BigQuery データセットを使用することで、既存のツールを用いてデータのカタログ化を改善できます。
- エンべディングのサポート - 詐欺検出のための顧客行動のエンコードなど、多くのアプリケーションで社内アルゴリズムによって生成されたカスタム ベクトル エンべディングを活用しています。ベクトルが Vertex AI Feature Store の最高レベルの構成要素になったことは喜ばしいことです。メンテナンスが必要なシステムの数が減ると、MLOps チームが他のタスクに時間をかけられるようになるため、より短時間でモデルを本番環境に導入できます。」
Wayfair、シニア ML エンジニア Gabriele Lanaro 氏
「Feature Store 2.0 は設計が大幅に改良されています。BigQuery がオフライン ストアとして再構成されたのは重要な変更点であり、これによりデータ複製の必要がなくなりました。低レイテンシのオンライン ストアのスピードにより、ML モデルのオンライン推論が迅速になるため、各ショップ向けに新しいライブツールやレスポンシブ ツールを提供できるようになります。こうした改良点は、当社と Google Cloud とのパートナーシップの証しであり、このような継続的な改良が将来的に、不公平と言えるほどの優位性を各ショップにどのようにもたらすのか楽しみにしています。」
- Shopify、シニア データ デベロッパー Marc-Antoine Bélanger 氏
次のステップ
新しい Feature Store は、今後さらに多くのお客様にアクセスを拡大し、お試しいただけるようになります。一般提供まで、皆様からのフィードバックをさらに反映してまいります。詳しくは、公開プレビュー版の公式ドキュメントをご覧ください。
その他のリソース
新しい Feature Store のビジョンについては、NEXT ‘23 のセッションをご覧ください。また、Google Cloud Next ‘23 での Vertex AI に関する発表の内容は、こちらでご確認いただけます。
ー Vertex AI、プロダクト マネージャー Raiyaan Serang
ー Vertex AI、プロダクト マネージャー Alex Martin



