AI Platform 上の TabNet: 高パフォーマンスで説明可能な表形式ラーニング
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
本日より、TabNet が Google Cloud AI Platform 上の組み込みアルゴリズムとして利用できるようになります。これにより、コードを記述せずにデータのトレーニング ジョブをより簡単に実行できる統合ツールチェーンが構築されます。
TabNet は、2 つの分野の最良の部分を組み合わせたものです。つまり、説明可能(単純なツリーベース モデルと同様)でありながら、高パフォーマンス(ディープ ニューラル ネットワークと同様)であるという利点を持ちます。したがって、クレジット スコアの予測、不正行為の検出と予測など、小売、金融、保険業界への応用に最適です。
TabNet は、シーケンシャル アテンションと呼ばれる機械学習手法を使用して、モデルの各ステップで推論の対象とするモデル特徴を選択します。このメカニズムにより、TabNet はモデルが予測に到達する方法を説明し、より正確なモデルの学習を支援できます。この設計のおかげで、TabNet は他のニューラル ネットワークとディシジョン ツリーより優れたパフォーマンスを実現するだけでなく、解釈可能な特徴アトリビューションも提供します。TabNet が組み込みアルゴリズムとしてリリースされたことで、TabNet のアーキテクチャと説明可能であるという特長を活用して、独自のデータでモデルをトレーニングできるようになります。
表形式データ向けのディープ ラーニング
表形式データは実際の AI で最も一般的なデータ型ですが、表形式データのディープ ラーニングはそれほど行われていません。ほとんどの応用例では、アンサンブル ディシジョン ツリーのバリアントが依然として主流を占めています。これはなぜでしょうか。ツリーベースのアプローチには、それらが普及する理由となったメリットがあります。このアプローチは一般に多くの表形式データセットで適切に機能し、詳細な解釈が可能です。このことは、多くの実際の応用例(たとえば、リスクの高い行為を裏付ける信頼が不可欠な金融サービス)で重要です。また、トレーニングを短時間で完了できます。ツリーベースのメソッドには、予測出力にとって最も重要な特徴を見つけるための単純な手法が存在します。さらに、これまでに提案されたディープ ラーニング アーキテクチャは、表形式データにはあまり適していません。スタックされた畳み込み層または多層パーセプトロンに基づく伝統的なニューラル ネットワークは、パラメータがあまりに多すぎ、適切なバイアス メカニズムを欠いているため、多くの場合、表形式データ向けの優れたソリューションを提示できません。
表形式データにディープ ラーニングを使用する理由は何でしょうか。明らかな理由の一つは、他の多くの領域(画像、音声、言語)と同様に、新しいディープ ラーニング アーキテクチャによって、大規模なデータセットで見られるようなパフォーマンスの大幅な向上が期待されることです。画像と言語におけるディープ ラーニングの最近の成果は、表形式データで適切に機能する新しいアーキテクチャの開発を促す契機となっています。さらに、ツリー学習では、ニューラル ネットワークと異なり、誤差逆伝播法と呼ばれる手法(誤差シグナルから直接学習する効率的な手法)を使用しません。これに対して、ディープ ニューラル ネットワークでは、表形式データに対する勾配降下法ベースのエンドツーエンド学習が可能です。これには、部分的にラベル付けされたデータからの学習(半教師あり学習とも言う)や 1 つのトレーニング済みモデルからの情報を使用した他の関連タスクの解決方法の学習(ドメイン適応)など、さまざまな利点があります。
TabNet の仕組み
TabNet は、ディープ ラーニング ベースのメソッドの主要なメリット(先に述べた高いパフォーマンスと新しい機能)を提供しつつ、ツリーベースのメソッドが持つ有用なメリット(説明可能性)を継承するために、「ディシジョン ツリーに似た」マッピングを学習するように設計されています。特に、TabNet の設計では 2 つの主要なニーズである高パフォーマンスと説明可能性が考慮されています。前述のように、多くの場合、高パフォーマンスだけでは不十分です。ニューラル ネットワーク ベースのアプローチがツリーベースのメソッドに取って代わるには、解釈可能である必要があります。Google は、TabNet の出力に基づいてローカルおよびグローバルな特徴を可視化するためのノートブックを提供します。
AI Platform 上での TabNet の使用
Google の TabNet は、Cloud AI Platform Training 上で組み込みアルゴリズムとして使用できるようになりました。Cloud AI Platform Training は、データ サイエンティストとエンジニアが機械学習モデルを簡単に構築できるようにするマネージド サービスです。TabNet 組み込みアルゴリズムを使用すると、TabNet アーキテクチャでモデルを簡単に構築してトレーニングできます。組み込みアルゴリズムを開始するには、Cloud Console で [AI Platform] -> [ジョブ] -> [+新規トレーニング ジョブ] -> [組み込みアルゴリズムによるトレーニング] を選択します。次に、トレーニング データをアップロードした後、[アルゴリズムを選択] プルダウンで [TabNet] を選択するだけで、TabNet を使用することができます。
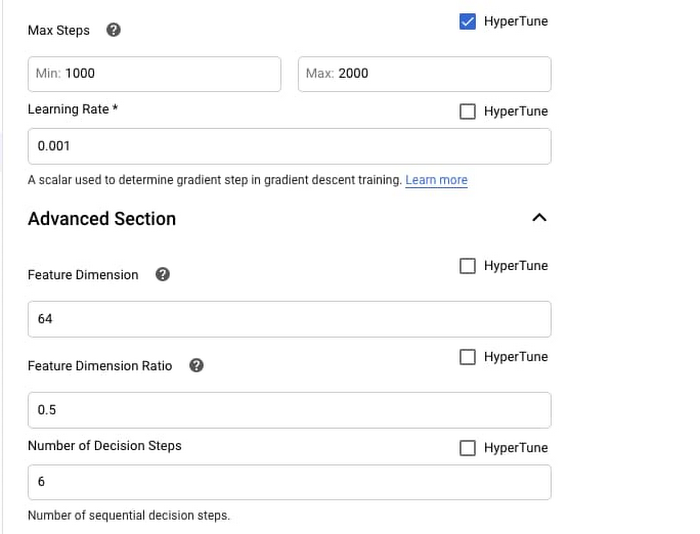
TabNet 組み込みアルゴリズムにはハイパーパラメータ調整も含まれているため、メソッドの背後にある複雑な技術を理解しなくても、簡単に高パフォーマンスを実現できます。ハイパーパラメータ調整は、1 つのトレーニング ジョブで複数のトライアルを実行することにより機能します。各トライアルでは、トレーニング アプリケーションが完全に実行されます。ハイパーパラメータ調整ではデフォルト値を使用するよりも優れたパフォーマンスが記録されますが、コンピューティング コストが増加します。
予測精度
Google は、TabNet の徹底的なベンチマーク評価を実施し、さまざまな領域で一般的に使用されている 8 つの表形式データセットで以前のメソッドのパフォーマンスを上回っているという測定結果を得ました。下記の表では、ディシジョン ツリーと代替ニューラル ネットワーク モデルの両方と比較して、より優れた(精度が高く誤差が少ない)パフォーマンスを示した比較値を強調表示しています。比較の詳細を確認するには、技術論文をご覧ください。
表 1: Sarcos Robotics Arm Inverse Dynamics データセットのパフォーマンス。サイズの異なる 3 つの TabNet モデル(-S、-M、-L で示されています)を評価しています。
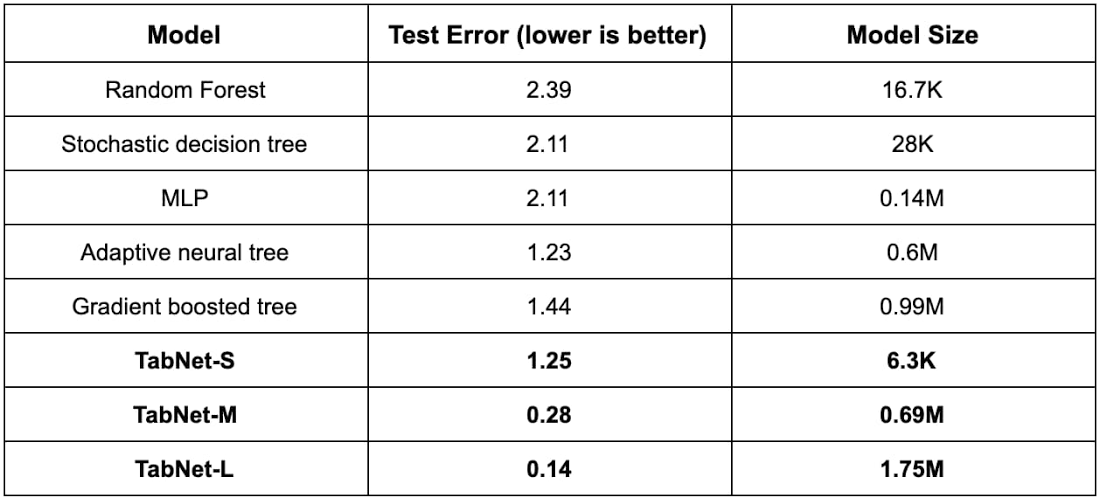
表 2: Higgs Boson データセットのパフォーマンス。サイズの異なる 2 つの TabNet モデル(-S、-M で示されています)を評価しています。
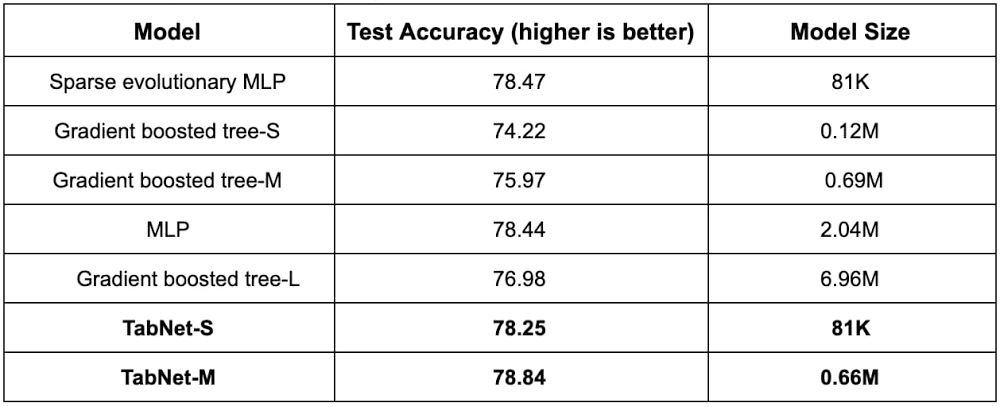
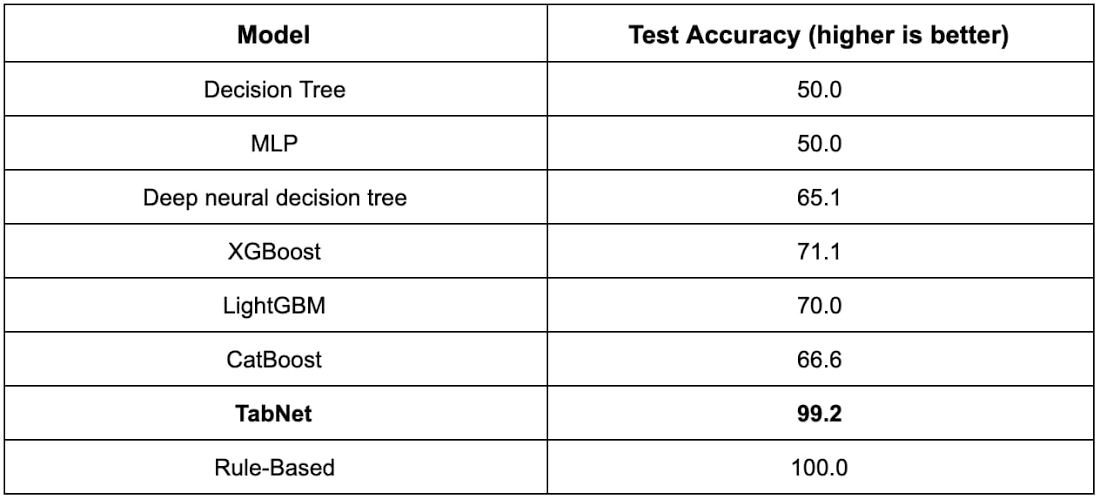
表 3: Poker Hand Induction データセットのパフォーマンス。入力と出力の関係は確定的で、数行のコードで実装した手作りのルールで 100% の精度が得られます。一方、他のモデルは、未加工の入力特徴を使用して必要な並べ替えとランク付けの操作を学習できません。
説明可能性
Syn2 という名前の合成データセットの特徴重要度を示す以下の図を使用して、説明可能性によって何が実現できるのかを説明します。この合成データセットは、特徴のサブセットのみで出力が決定されるように構成されています。具体的には、Syn2 では特徴 3~6 のみで出力が決定されます。下記の図は、特徴 3~6 以外の特徴に対応する Syn2 の大半の値が 0 に近いことを示しています。つまり、TabNet は出力に関連する顕著な特徴を正しく選択しています。
予測値に加えて、TabNet は特徴重要度の出力「マスク」も提供します。マスクは、モデル内の特定の決定ステップで特徴が選択されるかどうかと、マスクを使用して特徴重要度を取得できるかどうかを示します。予測出力は、モデルを説明するために非常に役立つ「aggregated_mask_values」を返します。Google が提供するノートブックは、「aggregated_mask_values」という名前のマスク値に基づいてローカルおよびグローバルな特徴の重要度を可視化します。特定のサンプルのマスクの値が高いほど、そのサンプルにおいて対応する特徴の重要度が高くなります。

図 1: グローバル インスタンス単位の特徴選択を示す Syn2 データの合計特徴重要度マスク(Magg)。色が明るいほど高い値を示します。各行は、各入力インスタンスのマスクを表します。この図には、30 個の入力インスタンスの出力マスクがあります。Syn2 には 11 の特徴(feat_1~feat_11)があり、出力が特徴 3、4、5、6 のみに基づいて決定されるように構成されています。図の各列は 1 つの特徴を表します。たとえば、最初の列は特徴 feat_1 を表します。この図は、列 3~6 の色が明るい(つまり重要度が最も高い)ことを示しています。
重要な点は、こうした説明可能性は合成データの例だけでなく、実際の応用でも適切に機能するということです。図 2 は、国勢調査データセットで同じ説明可能性メソッドを使用した例を示しています。この図は、ある人が年間 5 万ドルを超える収入を得られるかどうかを予測するうえで、教育、職業、1 週間あたりの労働時間が最も重要な特徴である(対応する列の色が明るい)ことを示しています。

図 2: グローバル インスタンス単位の特徴選択を示す国勢調査データの合計特徴重要度マスク。色が明るいほど高い値を示します。各行は、各入力インスタンスのマスクを表します。この図には、30 個の入力インスタンスの出力マスクがあります。各列は 1 つの特徴を表します。たとえば、最初の列は国勢調査データの年齢特徴を表し、2 番目の列は職業分類特徴を表します。この図は、教育、職業、1 週間あたりの労働時間が最も重要な特徴である(対応する列の色が明るい)ことを示しています。
まとめ
組み込みアルゴリズムである Google の TabNet を利用すれば、機械学習モデルを簡単に構築できます。このソリューションにはハイパーパラメータ調整が含まれているため、データ サイエンティストやソフトウェア エンジニアは最小限の調整を行うだけで堅牢なモデルを見つけることができます。他のニューラル ネットワーク モデルとは異なり、TabNet ニューラル ネットワークには説明可能性が元から備わっているため、モデルの説明を必要とする問題に適用することができます。重要な点は、TabNet は説明可能でありながら、さまざまな表形式データセットで高いパフォーマンスも実現するということです。
その他のリソース
TabNet についてさらに詳しく学び、AI Platform で使用するには、以下のリソースをご覧ください。
●TabNet に関する論文: Sercan O Arik および Tomas Pfister、「TabNet: Attentive interpretable tabular learning」arXiv プレプリント、arXiv:1908.07442、2019 年。URL: https://arxiv.org/abs/1908.07442
●クイックスタート: https://cloud.google.com/ai-platform/training/docs/algorithms/tab-net-start
●サンプルコード: https://github.com/google-research/google-research/tree/master/tabnet
謝辞
このブログ投稿に協力してくれた Tomas Pfister(Google Cloud AI エンジニア マネージャー)、Winston Chiang(Google Cloud AI プロダクト マネージャー)、Henry Tappen(Google Cloud AI プロダクト マネージャー)、Sara Robinson(Google Cloud AI デベロッパー アドボケイト)に感謝します。
-Sercan Ö. Arik(Google Cloud AI リサーチ サイエンティスト)
-Long T. Le(Google Cloud AI ソフトウェア エンジニア)



