TabNet on AI Platform: High-performance, Explainable Tabular Learning
Sercan Ö. Arik
Research Scientist, Google Cloud AI
Long T. Le
Software Engineer, Google Cloud AI
Today, we're making TabNet available as a built-in algorithm on Google Cloud AI Platform, creating an integrated tool chain that makes it easier to run training jobs on your data without writing any code.
TabNet combines the best of two worlds: it is explainable (similar to simpler tree-based models) while benefiting from high performance (similar to deep neural networks). This makes it great for retailers, finance and insurance industry applications such as predicting credit scores, fraud detection and forecasting.
TabNet uses a machine learning technique called sequential attention to select which model features to reason from at each step in the model. This mechanism makes it possible to explain how the model arrives at its predictions and helps it learn more accurate models. Thanks to this design, TabNet not only outperforms other neural networks and decision trees but also provides interpretable feature attributions. Releasing TabNet as a built-in algorithm means you'll be able to easily take advantage of TabNet's architecture and explainability and use it to train models on your own data.
Deep learning for tabular data
Although tabular data is the most common data type in real-world AI, deep learning for tabular data remains under-explored. Variants of ensemble decision trees still dominate most applications. Why is this? Tree-based approaches have certain benefits that make them popular: they generally work well on many tabular datasets, they are highly interpretable which is important in many real-world applications (e.g. in financial services where trust behind a high-risk action is crucial) and they are fast to train. Simple techniques in tree-based methods exist for finding which features matter most to the prediction output. In addition, previously proposed deep learning architectures are not well-suited for tabular data: conventional neural networks based on stacked convolutional layers or multi-layer perceptrons have too many parameters and lack appropriate bias mechanisms which often cause them to fail to obtain good solutions for tabular data.
Why use deep learning for tabular data? One obvious motivation is that, similarly to many other domains (image, speech, language), one would expect very significant performance improvements from new deep learning architectures, as we’ve seen for large datasets. Recent achievements of deep learning in image and language motivate us to develop new architecture that can work well with tabular data. In addition, unlike neural networks, tree learning does not use the technique known as back-propagation, which is an efficient way to directly learn from the error signal. In contrast, deep neural networks enable gradient descent-based end-to-end learning for tabular data which can have a multitude of benefits, including learning from partially labeled data (a.k.a. semi-supervised learning) and using information from one trained model to learn to solve other related tasks (domain adaptation).
How TabNet works
TabNet is designed to learn a ‘decision-tree-like’ mapping in order to inherit the valuable benefits of tree-based methods (explainability) while providing the key benefits of deep learning-based methods (high performance & new capabilities as described above). In particular, TabNet’s design considers two key needs: high performance and explainability. As mentioned, high performance alone is often not enough – a neural network-based approach does need to be interpretable in order to substitute tree-based methods. We provide a notebook to visualize the local and global features based on the TabNet's output.
Using TabNet on AI Platform
Google's TabNet is now available as a built-in algorithm on Cloud AI Platform Training. Cloud AI Platform Training is a managed service that enables data scientists and engineers to easily build machine learning models. The TabNet built-in algorithm makes it easy for you to build and train models with the TabNet architecture. You can start with the built-in algorithm by selecting "AI Platform -> Jobs -> +New Training Job -> Builtin algorithm Training" in the cloud console. Then, to use TabNet, simply select it from the built-in algorithm dropdown after uploading your training data:
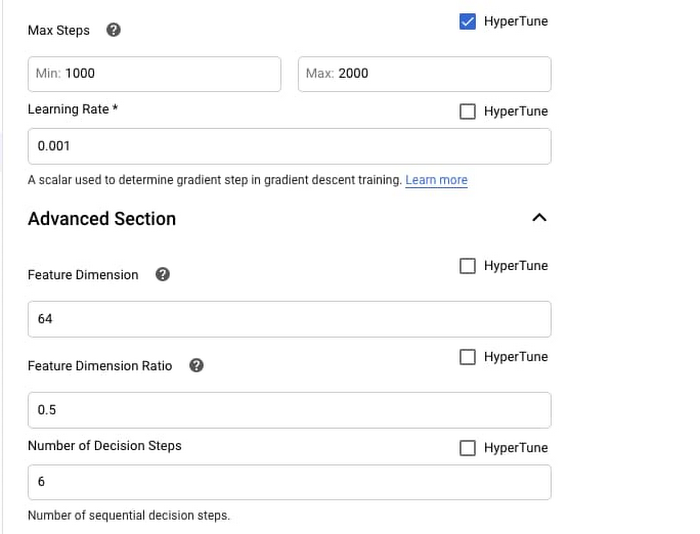
The TabNet built-in algorithm also includes hyperparameter tuning which makes it as easy to achieve high performance even without understanding the technical intricacies behind the method. Hyperparameter tuning works by running multiple trials in a single training job. Each trial is a complete execution of your training application. Hyperparameter tuning archives better performance than using the default values, but hyperparameter tuning also increases the computation cost.
Prediction Accuracy
We have done thorough benchmarking of TabNet and observe that it outperforms previous work across eight commonly used tabular datasets across different domains. The tables below highlight comparisons which, in summary, show better performance (higher accuracy / lower error) compared to both decision trees and alternative neural network models. We invite readers interested in more details about the comparisons to review the technical paper.
Table 1: Performance for Sarcos Robotics Arm Inverse Dynamics dataset. Three TabNet models of different sizes are considered (denoted with -S, -M and -L).
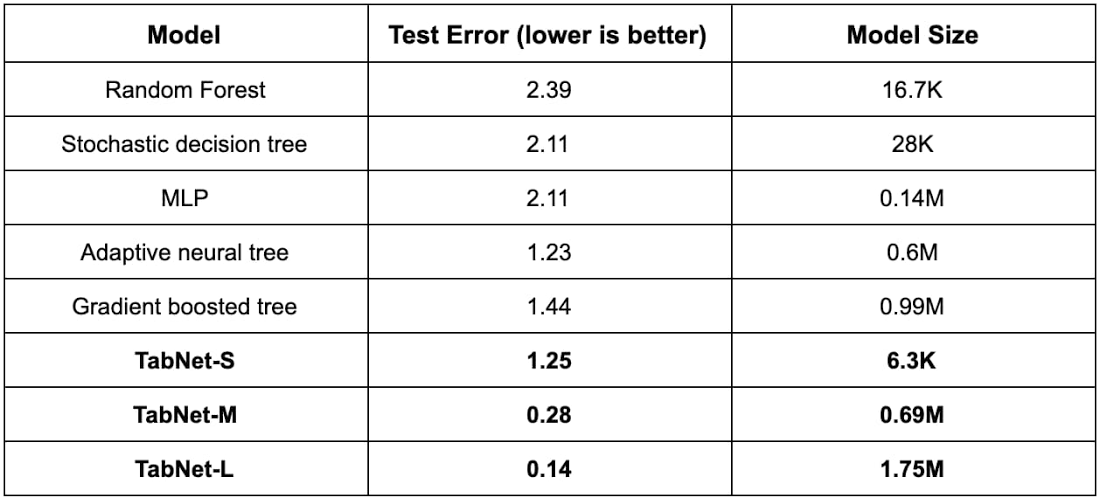
Table 2: Performance for Higgs Boson dataset. Three TabNet models of different sizes are considered (denoted with -S, -M).
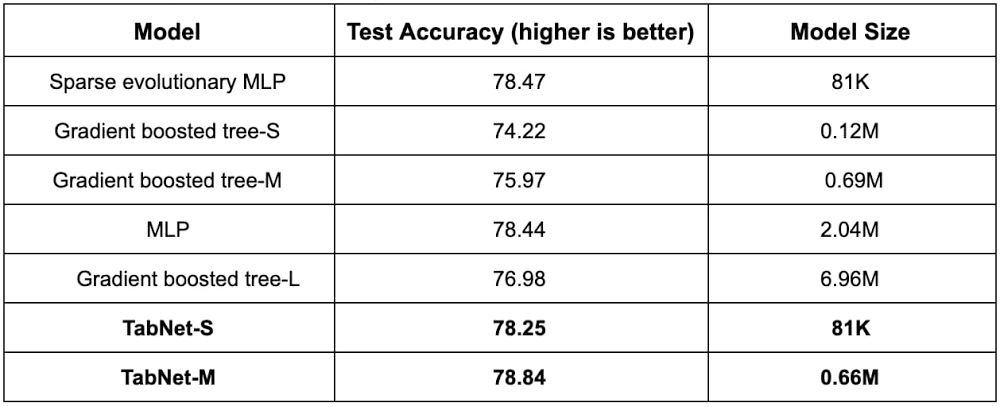
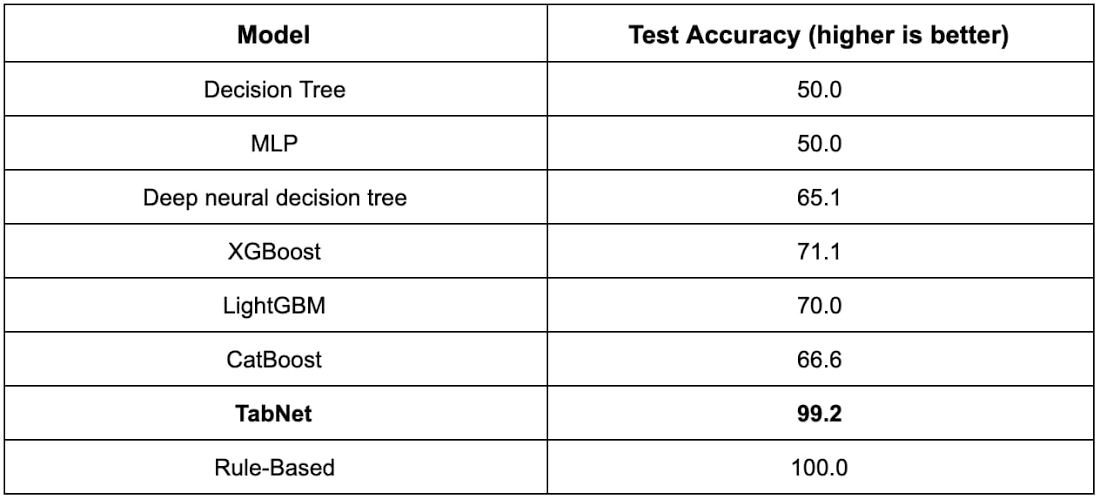
Table 3: Performance for Poker Hand Induction dataset. The input-output relationship is deterministic and handcrafted rules implemented with several lines of code can get 100% accuracy. Yet other models cannot learn the required sorting and ranking operations with the raw input features.
Explainability
To illustrate what is achievable with this kind of explainability, the figure below shows the feature importance for a synthetic dataset called Syn2. This synthetic dataset is constructed such that only a subset of the features determine the output - e.g. for Syn 2 the output only depends on features 3 to 6. The figure below shows that majority values corresponding to features other than features 3 to 6 are close to '0' for Syn 2, i.e. TabNet correctly chooses the salient features relevant for the output.In addition to prediction values, TabNet also provides a feature importance output “masks”, which indicates whether a feature is selected at a given decision step in the model and the masks can then be used to obtain feature importances. The prediction output returns the "aggregated_mask_values", which is most useful for explaining the model. We provide a notebook to visualize the local and global feature importance based on the mask values (named "aggregated_mask_values"). The higher the value of the mask for a particular sample, the more important the corresponding feature is for that sample.

Figure 1: The aggregate feature importance masks Magg in Syn2 data which shows the global instance-wise feature selection. Brighter colors show a higher value. Each row represents the masks for each input instance. The Figure includes the output masks of 30 input instances. The Syn2 includes 11 features (feat_1 to feat_11), and the output constructed such that the output only depends on features 3,4,5 and 6. Each column in the figure represents one feature such as the first column represents the feat_1 feature. The figure shows that columns 3-6 have "light" color, which are most important.
Importantly, this explainability capability is not limited to synthetic toy examples, but also works well for real-life applications. Figure 2 shows the same explainability method for the Census dataset. The figure shows that education, occupation, number of hours per week are the most important features to predict whether a person can earn more than $50K/year (the color of corresponding columns are lighter).

Figure 2: The aggregate feature importance masks in Census data which shows the global instance-wise feature selection. Brighter colors show a higher value. Each row represents the masks for each input instance. The Figure includes the output masks of 30 input instances. Each column represents a feature. For example, the first column represents the age feature, the second column represents the workclass feature in Census data, etc. The figure shows that education, occupation, number of hours per week are the most important features (these corresponding columns have "light" color).
Summary
Google's TabNet as a built-in algorithm makes it easy to build machine learning models. The solution also includes hyperparameter tuning which enables data scientists or software engineers to find robust models with minimal effort in tuning. In contrast to other neural network models, the TabNet neural network enables an inherent form of explainability that makes it possible to apply it to problems that require the model explanations. Importantly, while being explainable, TabNet also achieves high performance on a wide range of different tabular datasets.
Learn more
Want to learn more about TabNet and use it on AI Platform? Check out the resources here:
TabNet paper: Sercan O Arik and Tomas Pfister. TabNet: Attentive interpretable tabular learning. arXiv preprint arXiv:1908.07442, 2019. URL https://arxiv.org/abs/1908.07442
Quickstart: https://cloud.google.com/ai-platform/training/docs/algorithms/tab-net-start
Sample code: https://github.com/google-research/google-research/tree/master/tabnet
Acknowledgements
We'd like to thank Tomas Pfister (Engineer Manager, Google Cloud AI), Winston Chiang (Product Manager, Google Cloud AI), Henry Tappen (Product Manager, Google Cloud AI) and Sara Robinson (Developer Advocate, Google Cloud AI) for their contributions to this blog.



