GenOps: 生成 AI 向けに MLOps が進化
Sharmila Devi
AI Consultant, Google
Frederic Molina
ML Specialist, Google
※この投稿は米国時間 2024 年 9 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
組織が生成 AI ソリューションを大規模にデプロイしようとすると、多くの場合、運用上の課題に直面します。GenOps(生成 AI 向け MLOps)は、これらの課題に対処します。
GenOps は、DevOps の原則と ML ワークフローを組み合わせて、本番環境で生成 AI モデルのデプロイ、モニタリング、メンテナンスを行います。GenOps により、生成 AI システムがスケーラブルかつ高い信頼性のもと、継続的に改善されるようになります。
なぜ MLOps では生成 AI にとって難しいのか?生成 AI モデルには、従来の MLOps の手法では不十分な独自の課題があります。
-
スケーリング: 何十億ものパラメータには特殊なインフラストラクチャを要する。
-
コンピューティング: トレーニングと推論に必要なリソースが多い。
-
安全性: 有害なコンテンツに対する強力な保護対策の必要性。
-
急速な進化: 新たな開発に対応するために継続的な更新が必要。
-
予測不可能性: 出力が非決定的で、テストと検証が複雑化。
今回のブログでは、生成 AI 特有の要求に応えるために MLOps の原則をどのように適応させ、拡張するかについて説明します。
GenOps の主な機能生成 AI モデルは氷山の一角だとお考えください。生成 AI システムは複雑で、多数の隠れた相互関連要素を含んでいます。以下の画像は、元の論文「Hidden Technical Debt in Machine Learning Systems」(ML システムの隠れた技術的負債)から、それらの要素を拡張したものです。
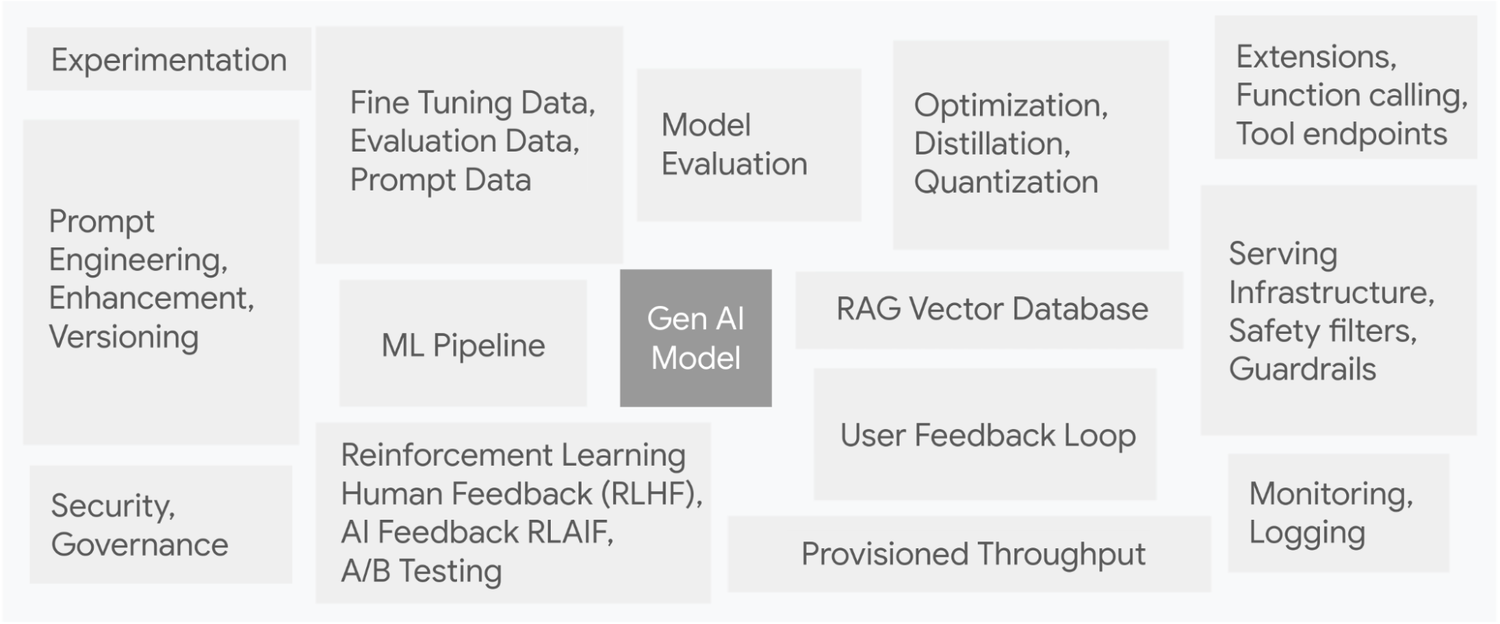
Hidden Technical Debt in Gen AI Systems
以下は、事前トレーニング済みモデルとファインチューニング済みモデルの GenOps におけるさまざまな要素を示したものです。
-
生成 AI のテストとプロトタイピング: Gemini、Imagen などのエンタープライズ モデルや、Gemma2、PaliGemma などのオープンウェイト モデルを使用してテストを行い、プロトタイプを構築します。
-
プロンプト: 以下はプロンプトに関連するさまざまなタスクです。
-
プロンプト エンジニアリング: 生成 AI モデルのプロンプトを設計・改良し、目的の出力を生成します。
-
プロンプトのバージョニング: プロンプトの変更を時間経過とともに管理、追跡、制御します。
-
プロンプトの機能強化: LLM を使用して、特定のタスクのパフォーマンスを最大化する改良版のプロンプトを生成します。
-
評価: 指標やフィードバックを使用して、特定のタスクに対する生成 AI モデルからの回答を評価します。
-
最適化: 量子化や蒸留などの最適化手法を適用して、モデルをより効率的にデプロイできるようにします。
-
安全性: ガードレールとフィルタを実装します。Gemini などのモデルには、モデルによる有害な回答を防ぐための安全フィルタが組み込まれています。
-
ファインチューニング: 特殊なデータセットに追加の調整を加えることで、事前トレーニング済みモデルを特定のドメイン / タスクに適応させます。
-
バージョン管理: 生成 AI モデル、プロンプト、データセットのさまざまなバージョンを管理します。
-
デプロイ: 生成 AI モデルをスケーリング、コンテナ化、統合して提供します。
-
モニタリング: モデルのパフォーマンス、出力品質、レイテンシ、リソース使用量をリアルタイムで追跡します。
-
セキュリティとガバナンス: モデルとデータを不正アクセスや攻撃から保護し、規制遵守を徹底します。
GenOps の主要コンポーネントを確認したところで、VertexAI の従来の MLOps パイプラインを確認し、それが GenOps にどのように拡張できるかを見てみましょう。この MLOps パイプラインは、継続的インテグレーション、継続的デプロイ、継続的トレーニング(CI / CD / CT)を組み込んで、ML モデルをデプロイするまでのプロセスを自動化します。
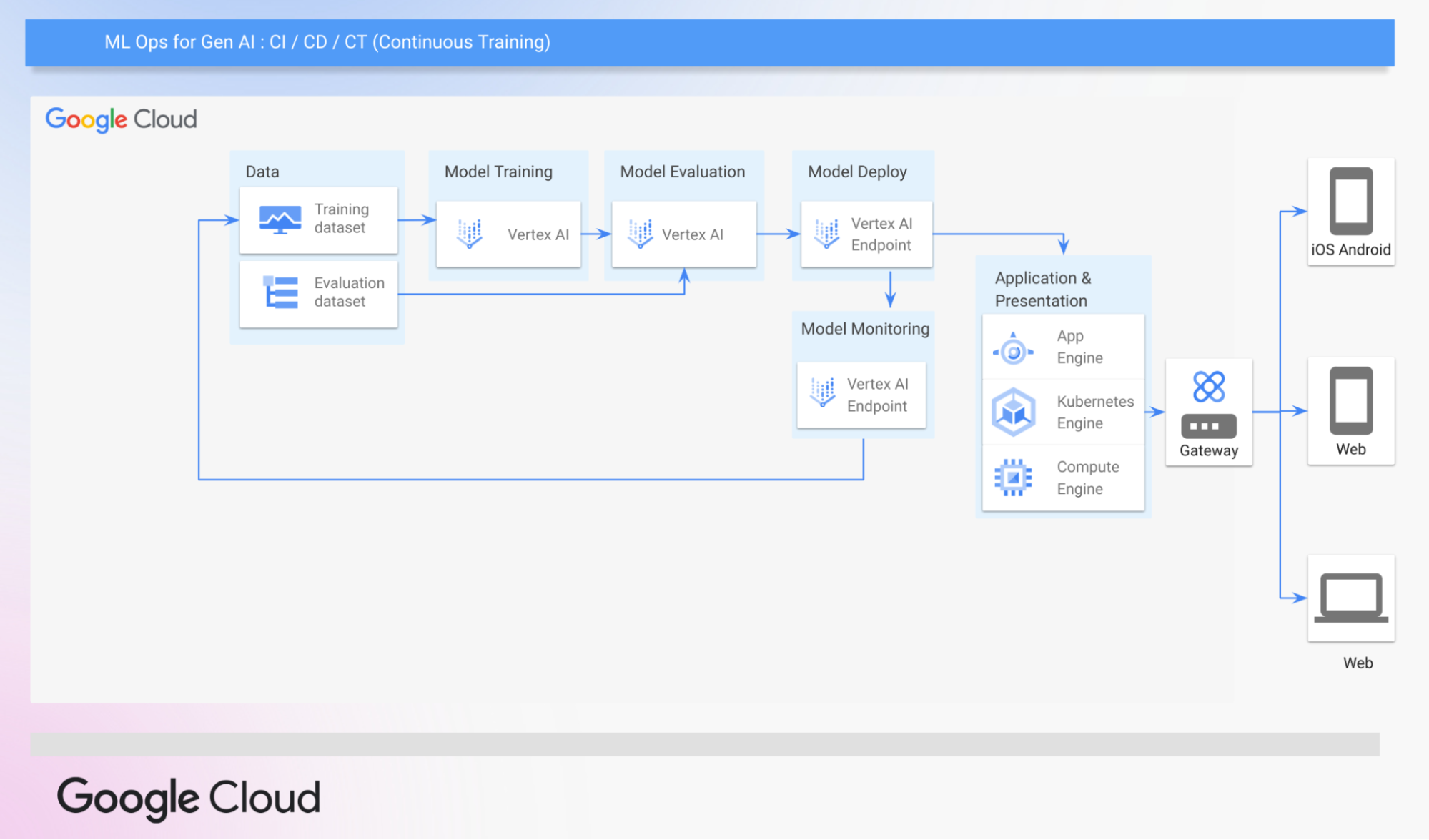
Google Cloud の一般的な MLOps パイプライン
MLOps を拡張して GenOps をサポートそれでは、複数のモダリティにわたる強力なモデルの初回テストから、ファインチューニング、安全性、デプロイの重要な考慮事項まで、Google Cloud 上の堅牢な GenOps パイプラインの主要コンポーネントを理解しましょう。このブログでは、ファインチューニング可能な事前トレーニング済みモデルの活用に焦点を当てています。
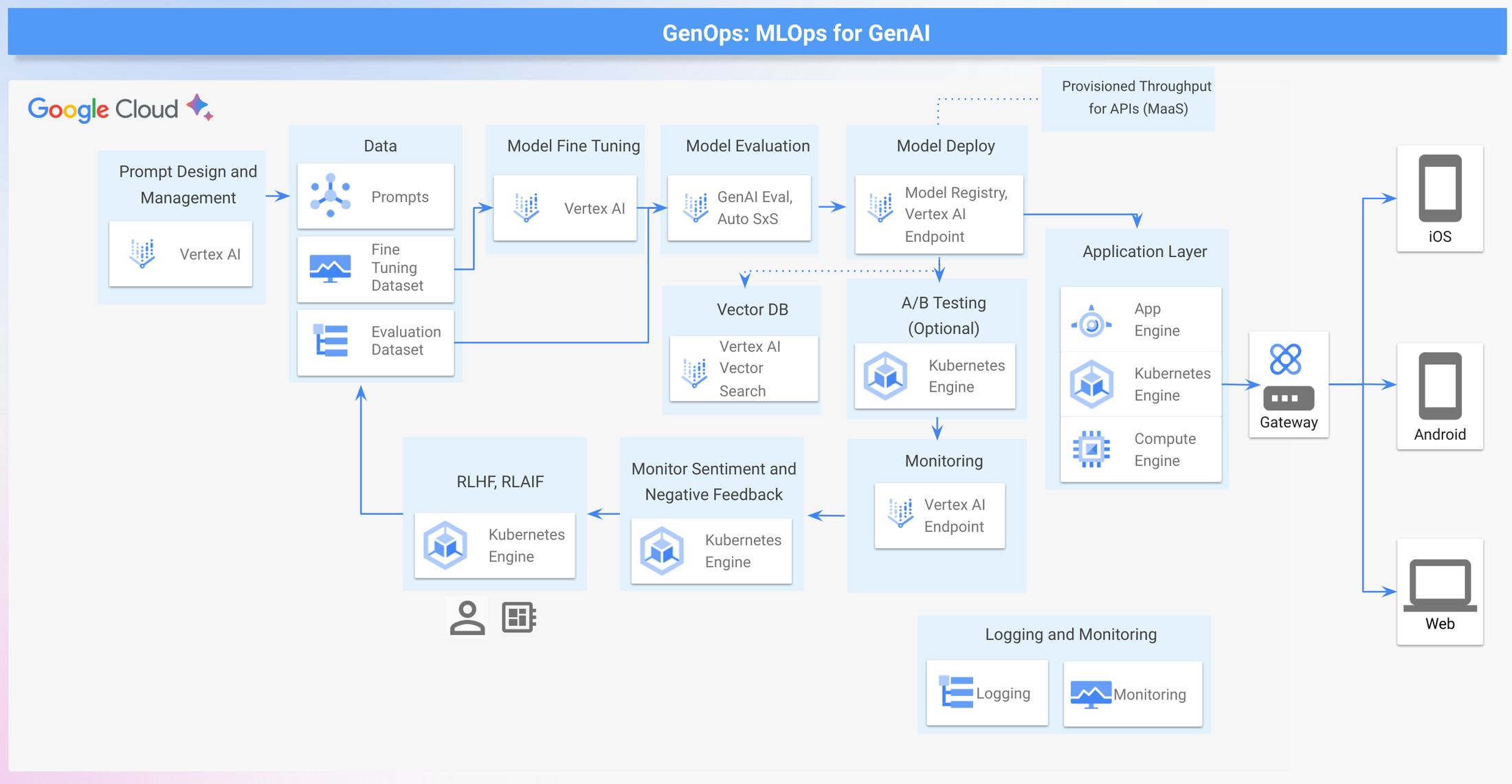
GenOps のサンプル アーキテクチャ
これらの GenOps の主要コンポーネントが Google Cloud でどのように構築できるのかを確認しましょう。
-
データ: 生成 AI への取り組みはデータから始まります。
-
少数ショットのサンプル: 少数ショット プロンプトは、モデルの出力形式、言い回し、範囲、パターンをガイドするサンプルを提供します。
-
教師ありファインチューニング データセット: このラベル付きデータセットは、事前トレーニング済みモデルを特定のタスクやドメインに合わせてファインチューニングするために使用されます。
-
ゴールデン評価データセット: 特定のタスクに対するモデルのパフォーマンスを評価するために使用されます。このラベル付きデータセットは、その特定のタスクに対する手動での評価と指標ベースの評価の両方に使用できます。
2. プロンプト管理: Vertex AI Studio では、プロンプトの作成、テスト、改良を共同で行えます。チームはテキストの入力、モデルの選択、パラメータの調整を行い、完成したプロンプトを共有プロジェクト内に保存できます。
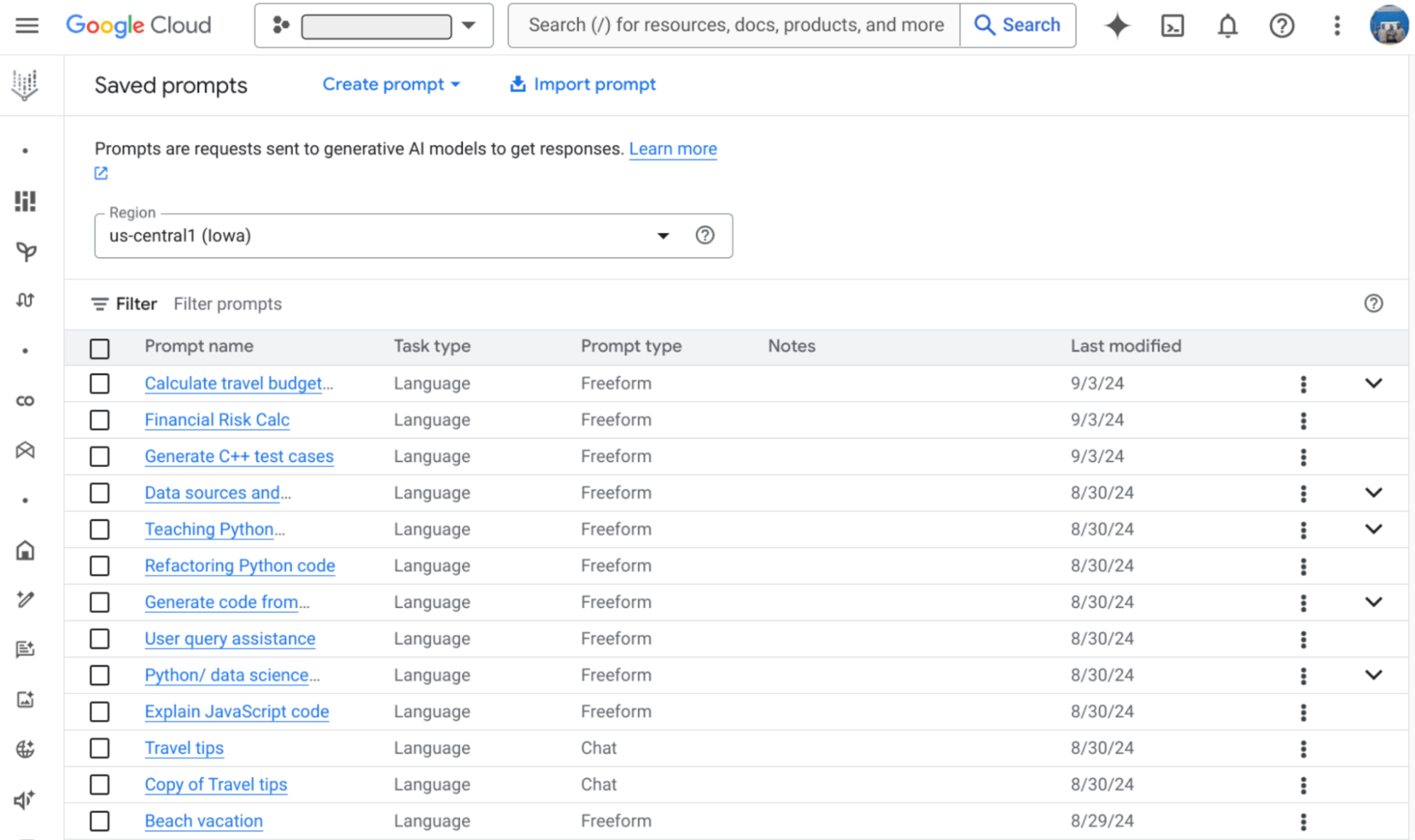
Vertex AI Studio に保存されたプロンプト
3. モデルのファインチューニング: このステップでは、ファインチューニング データを使用して、事前トレーニング済み生成 AI モデルを特定のタスクやドメインに合わせて調整します。以下では、Google Cloud でモデルをファインチューニングするために Vertex AI で利用可能な 2 つの方法をご紹介します。
-
教師ありファインチューニングは、ラベル付きデータが利用可能な、明確に定義されたタスクに適しています。これは、言語やコンテンツが、大規模モデルのトレーニングに使用されたデータと大きく異なるドメイン固有のアプリケーションに特に有効です。こちらは、Low-Rank Adaptation of Large Language Models(LoRA)と、そのメモリ効率の高いバージョンである QLoRA を使用して、VertexAI で LLM をチューニングするための推奨構成です。
-
人間からのフィードバックを用いた強化学習(RLHF)では、人間から収集されたフィードバックを使用してモデルをチューニングします。モデルの出力が複雑で説明が難しい場合は、RLHF をおすすめします。モデルからの出力が定義しにくいものでない場合は、教師ありファインチューニングを検討してください。
TensorBoard や Embedding Projector のような可視化ツールを使用すると、関連のないプロンプトを検出できます。以下に示すように、このプロンプトは RLHF や RLAIF の回答を準備するために後から使用できます。

TensorBoard を使用したプロンプトの可視化
UI は、以下に示すように、人間の評価者が LLM の回答を評価・更新するのに効果的な Google Mesop などのオープンソース ソリューションを使用して作成することもできます。
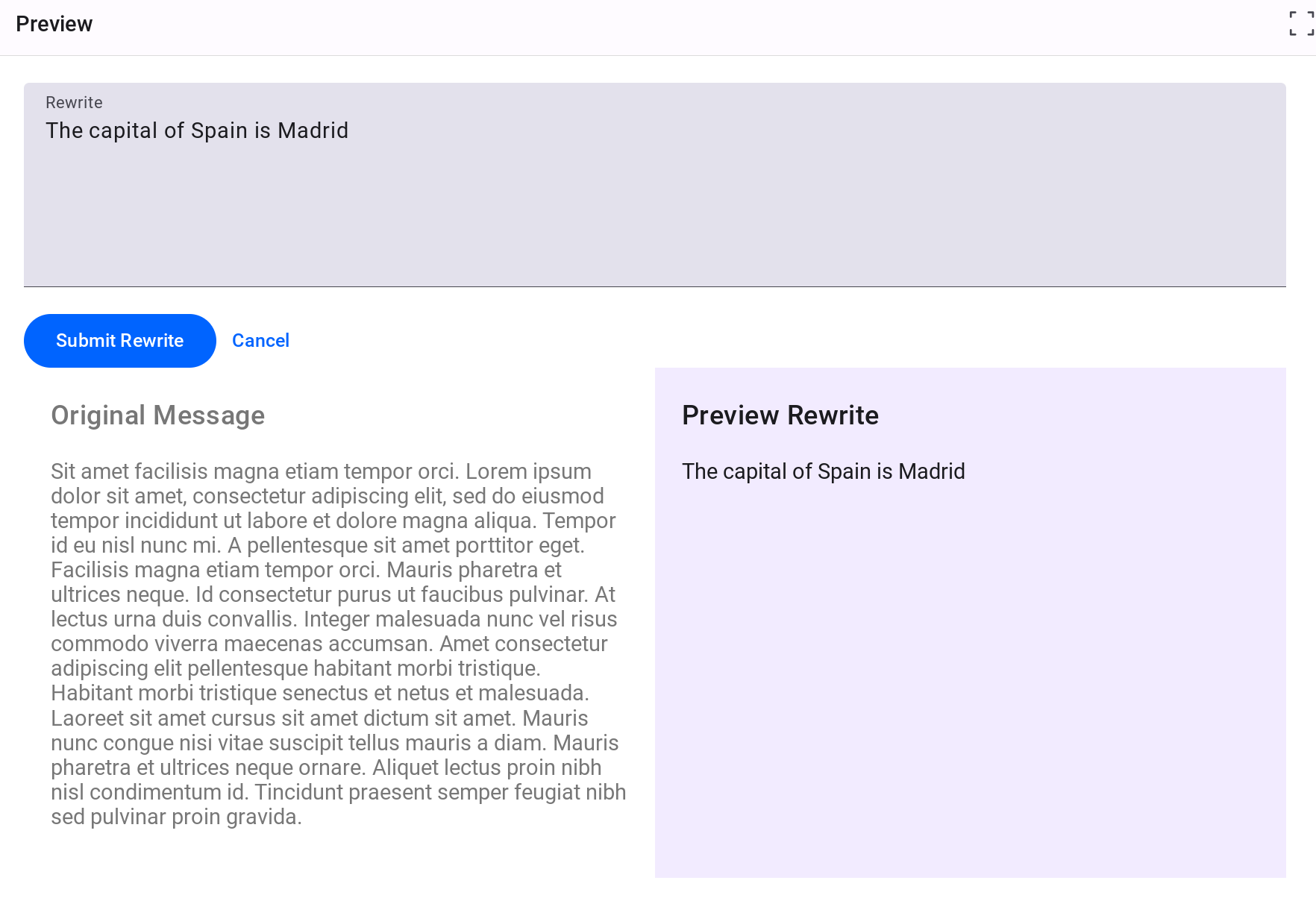
Google Mesop を使用して構築された RLHF 向け UI
4. モデルの評価: Vertex AI の Gen AI Evaluation Service は、説明可能な指標を使用して生成 AI モデルを評価するために使用されます。このサービスでは、主に 2 種類の指標が提供されます。
-
モデルベースの指標: モデルベースの指標では、Google 所有のモデルを判定の基準として使用しています。モデルベースの指標をペアワイズまたはポイントワイズで測定するために使用されます。
-
コンピューティング ベースの指標: これらの指標(ROUGE や BLEU など)は、モデルの出力をグラウンド トゥルースまたは基準値と対比する数式を使用して計算されます。
Automatic side-by-side(AutoSxS)は、VertexAI Model Registry 内の生成 AI モデルや事前生成された予測のパフォーマンスを評価するために使用されるペアワイズ モデル ベースの評価ツールです。自動評価を使用して、プロンプトに対して優れた回答をしたモデルを決定します。
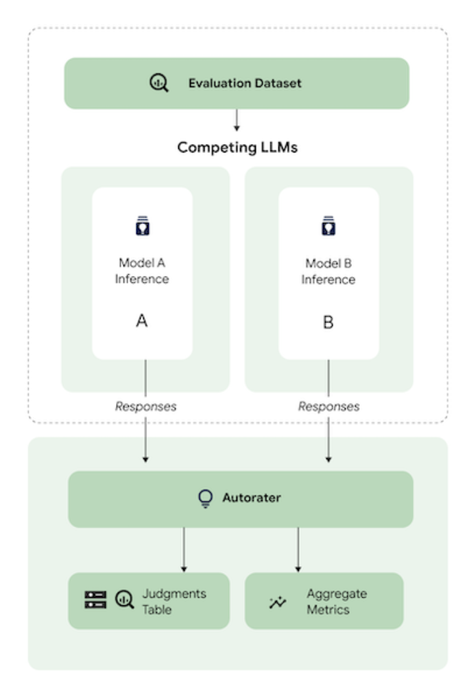
VertexAI AutoSxS 評価
5. モデルのデプロイ:
-
マネージド API があり、デプロイが必要ないモデル: Gemini のような Google の基本的な生成 AI モデルにはマネージド API があり、デプロイなしでプロンプトを受け付けることが可能です。
-
デプロイが必要なモデル: 他の生成 AI モデルは、プロンプトを受け付ける前に VertexAI エンドポイントにデプロイする必要があります。デプロイを可能にするには、モデルが Vertex AI Model Registry に表示されている必要があります。デプロイされる生成 AI モデルには 2 つのタイプがあります。
-
ファインチューニングされたモデル: サポートされている基盤モデルをカスタムデータでチューニングすることによって作成されます。
-
マネージド API のない生成 AI モデル: Gemma2、Mistral、Nemo など、VertexAI Model Garden にある多くのモデルは、[デプロイ] ボタンまたは [ノートブックを開く] からアクセスできます。
一部のモデルは、より詳細に制御できるよう Google Kubernetes Engine へのデプロイをサポートしています。GKE で単一の GPU を使用してモデルを提供するには、NVIDIA Triton Inference Server や vLLM のようなオンライン サービング フレームワークを使用します。これらは LLM 用に高いスループットとメモリ効率を備えた推論エンジンです。
6. モニタリング: 継続的なモニタリングでは、主要な指標、データパターン、傾向を分析して、デプロイされたモデルの実際のパフォーマンスを評価します。Cloud Monitoring は、Google Cloud サービスのモニタリングに使用されます。
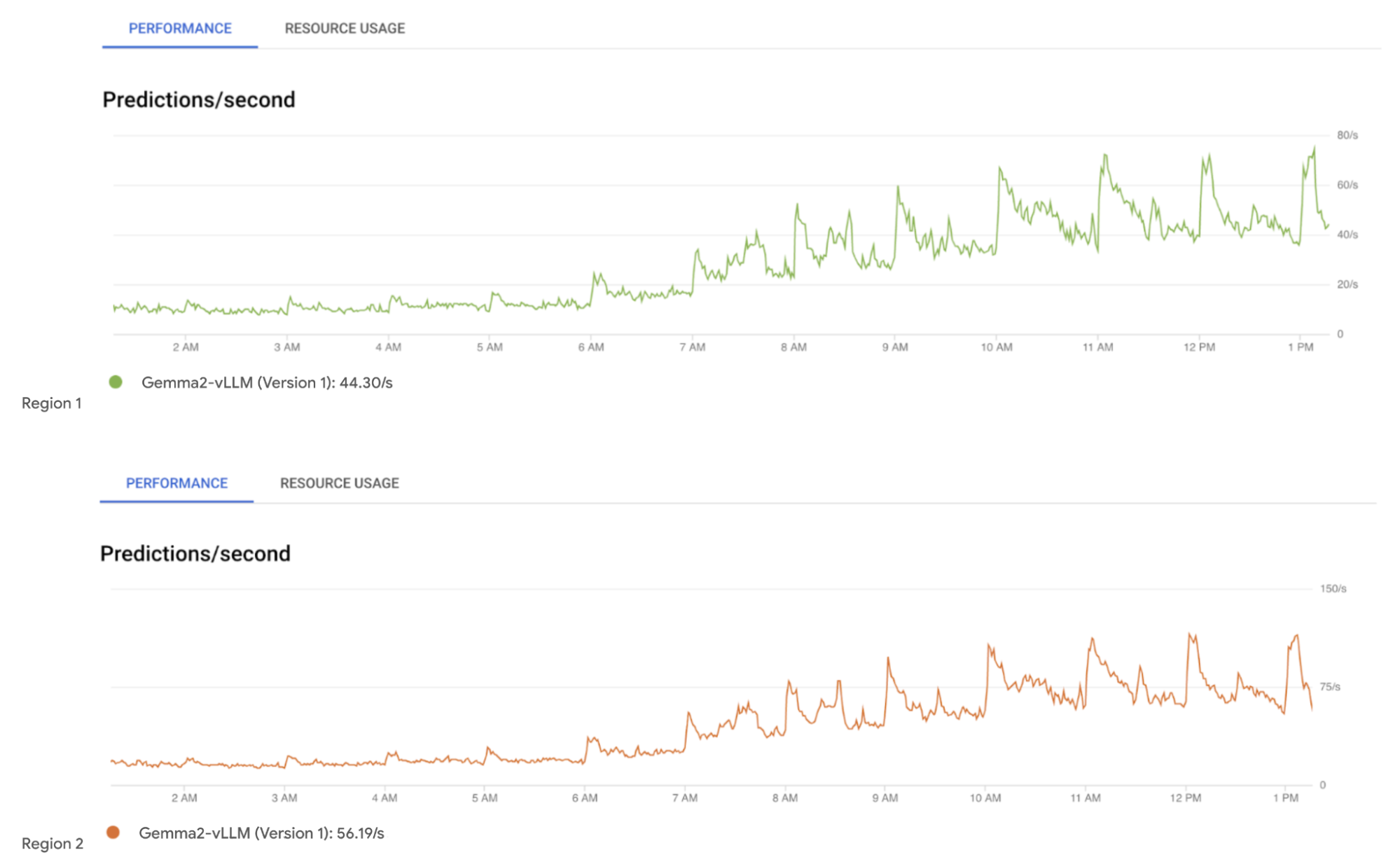
VertexAI エンドポイントにデプロイされた Gemma2 モデルのモニタリング
GenOps の手法を採用すると、組織は効率的でビジネス目標に沿ったシステムを構築でき、生成 AI の可能性を最大限に活用できるようになります。
ー Google、AI コンサルタント Sharmila Devi
ー Google、ML スペシャリスト Frederic Molina



