Let’s Enhance が NVIDIA AI と GKE を使用して AI ベースの写真編集を強化した仕組み
Google Cloud Japan Team
※この投稿は米国時間 2022 年 9 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
個人的なニーズやビジネスニーズに応じて生成され、使用されるデジタル画像の数は急増しています。たとえば e コマース プラットフォームとオンライン マーケットプレイスでは、商品の画像と映像が消費者の認識、意思決定、最終的にはコンバージョン率に大きく影響しています。さらに、販売者が生成する商品画像、貸主が生成する賃貸物件の写真、インフルエンサーが生成するソーシャル メディア コンテンツなど、e コマース向けビジュアル コンテンツをユーザーが生成する傾向が急速に進んでいます。そこにはどのような課題があるでしょうか。ユーザーが生成する画像は多くの場合、スマートフォンのカメラで撮影され、サイズ、品質、圧縮率、解像度という点でかなりばらつきがあります。そのため、企業が一貫して高品質の商品画像をプラットフォームで提供するのは簡単なことではありません。
コンピュータ ビジョンを専門とするスタートアップ企業の Let’s Enhance では、米国とウクライナのチームが AI を使用してこの問題を対処しようと乗り出しました。Let’s Enhance のプラットフォームでは AI を活用した機能によって、ユーザーが生成した写真を自動的に修正して品質を向上させます。自動アップスケール、モザイク化とピンボケの補正、色と光量不足の修正、圧縮アーティファクト除去などの機能のすべてをワンクリックで使用できるため、プロ仕様の機器や写真編集技術は必要ありません。
「Let’s Enhance.io は AI を活用したビジュアル テクノロジーを、マーケティング担当者から起業家、写真家、デザイナーに至るまでの誰もが簡単に使用できるシンプルなプラットフォームとして設計されています。」Let’s Enhance の CEO 兼共同創設者である Sofi Shvets 氏はこのように説明してくれました。

これまで Let’s Enhance は、世界中の数百万人のユーザーが生成した 1 億点を超える写真を処理し、デジタルアート ギャラリー、不動産業者、デジタル印刷、e コマース、オンライン マーケットプレイスなど多岐にわたるユースケースに対応してきました。さらにデジタル マーケットプレイス用に Claid.ai という新しい API を導入し、ユーザーが生成したコンテンツを自動的かつ大規模に補正して最適化できるようにした結果、同社は毎月数百万点の画像を処理し、ユーザー デマンドの急増に対応する必要に迫られました。
ですが、世界中で大規模に使用できる AI 対応のサービスを構築してデプロイするとなると、モデルの構築、トレーニング、推論のサービング、リソースのスケーリングにまで及ぶ大々的な技術的課題に対処しなければなりません。また、こうしたサービスに必要となるインフラストラクチャは、管理しやすく簡単にモニタリングできて、エンドユーザーがどこにいようとリアルタイムのパフォーマンスを実現できなければなりません。さらに、ユーザーデマンドの急増に応じてスケーリングできると同時に、費用を最適化できるインフラストラクチャであることも要件となります。
拡大し続けるユーザーベースに対応するために Let’s Enhance が選んだ方法は、同社の AI を活用したプラットフォームを Google Cloud と NVIDIA 上の本番環境にデプロイすることでした。Let’s Enhance のソリューションを解説する前に、同社がビジネス目標を達成する際に直面した技術的課題を詳しく見ていきましょう。
新たな成長とイノベーションに拍車をかけるソリューションの設計
補正された高品質の画像をエンドユーザーに表示するために、Let’s Enhance の製品では最先端のディープ ニューラル ネットワーク(DNN)が利用されています。けれども、DNN はコンピューティング負荷が高く、メモリ使用量も多いワークロードです。DNN モデルを構築してトレーニングすること自体が複雑な反復プロセスであり、さらに、たとえば新しいユーザー リクエストを処理する際に高品質のエンドユーザー エクスペリエンスを実現すると同時にデプロイの総費用を削減するためには、アプリケーションのパフォーマンスが極めて重要です。
入力された 1 つの推論または処理リクエスト、つまりサイズに大幅なばらつきがあるユーザー生成の画像を AI で補正した出力画像にする作業だけでも、エンドツーエンドのパイプライン内で複数の DNN モデルを統合しなければなりません。最適化の対象とする推論パフォーマンスの主な指標には、レイテンシ(入力された画像を補正された画像として利用可能にするまでの時間)とスループット(1 秒あたりに処理できる画像の数)がありました。
Google Cloud と NVIDIA のテクノロジーを合わせることで、Let’s Enhance チームの成長と拡大に向けて必要なすべての要素が揃いました。このソリューション スタックの主な 3 つのコンポーネントは次のとおりです。
コンピューティング リソース: NVIDIA A100 Tensor Core GPU 搭載の A2 VM
インフラストラクチャの管理: Google Kubernetes Engine(GKE)
- 推論のサービング: NVIDIA Triton Inference Server
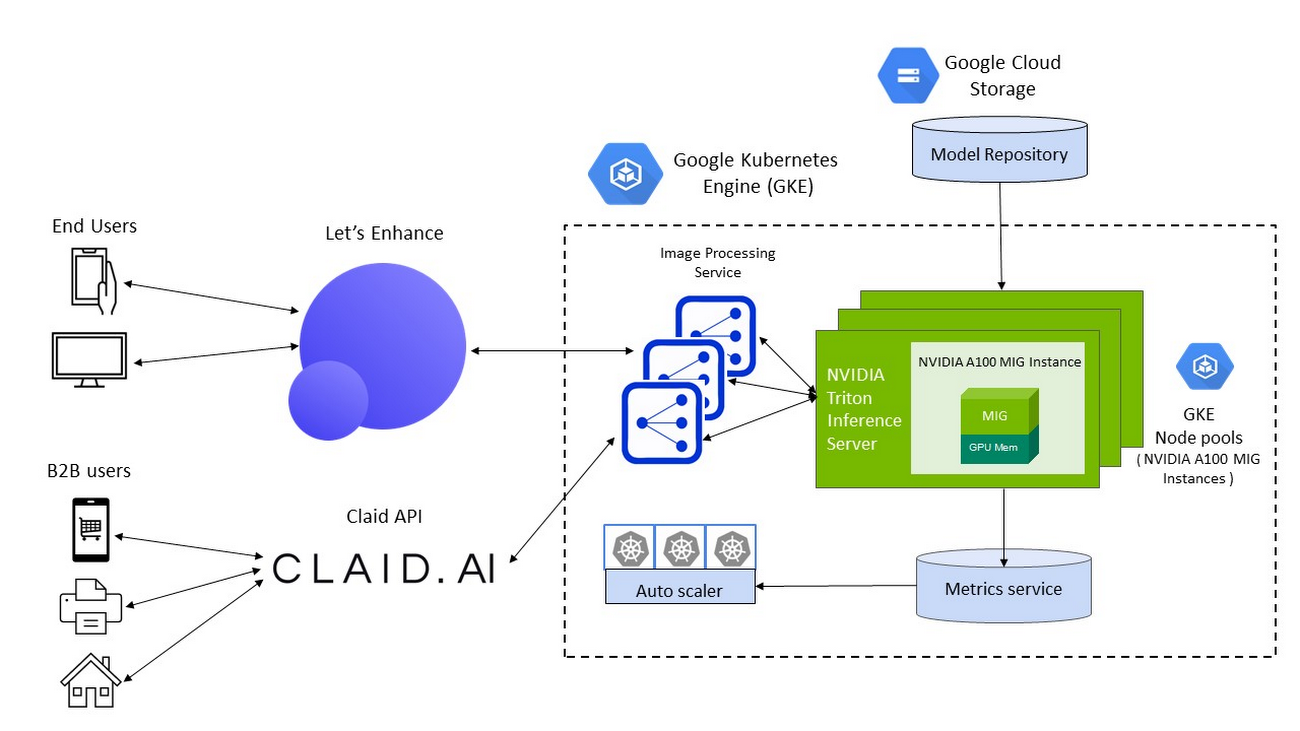
Google Cloud 上の NVIDIA A100 マルチインスタンス GPU(MIG)によるスループットの向上と費用の削減
DNN モデルのコンピューティング要件を満たし、リアルタイムの推論パフォーマンスをエンドユーザーに提供するために、Let’s Enhance がコンピューティング インフラストラクチャとして選んだのは、NVIDIA A100 Tensor Core GPU を搭載した Google Cloud A2 VM です。A100 GPU 固有のマルチインスタンス GPU(MIG)機能を使用すれば、1 つの GPU を 2 つの独立したインスタンスにパーティション分割して、2 つのユーザー リクエストを同時に処理できます。したがって、対応できるユーザー リクエストの数を増やせると同時に、デプロイの総費用を削減できます。
NVIDIA V100 GPU に比べ、A100 MIG インスタンスは平均スループットの 40% 向上を実現しました。特定の画像補正パイプラインでは、同じ数のノードがデプロイされている場合の向上率が最大 80% に至りました。MIG 対応の A100 GPU を使用すると、同じサイズのノードプールでもパフォーマンスが向上することから、Let’s Enhance は費用を 34% 削減できました。
GKE によるインフラストラクチャ管理の単純化
顧客にサービス品質(QoS)を保証し、ユーザー デマンドに対応するために、Let’s Enhance は高い使用率を維持して費用を低く抑えながら、基礎となるコンピューティング リソースをプロビジョニング、管理、スケーリングする必要がありました。
業界トップクラスのトレーニング機能と推論機能を提供する GKE は、1 クラスタあたり 15,000 ノードを使用でき、自動プロビジョニングと自動スケーリング、そして各種のマシンタイプ(CPU と GPU、オンデマンドとスポットなど)に対応できるため、Let’s Enhance にとって理想的な選択肢でした。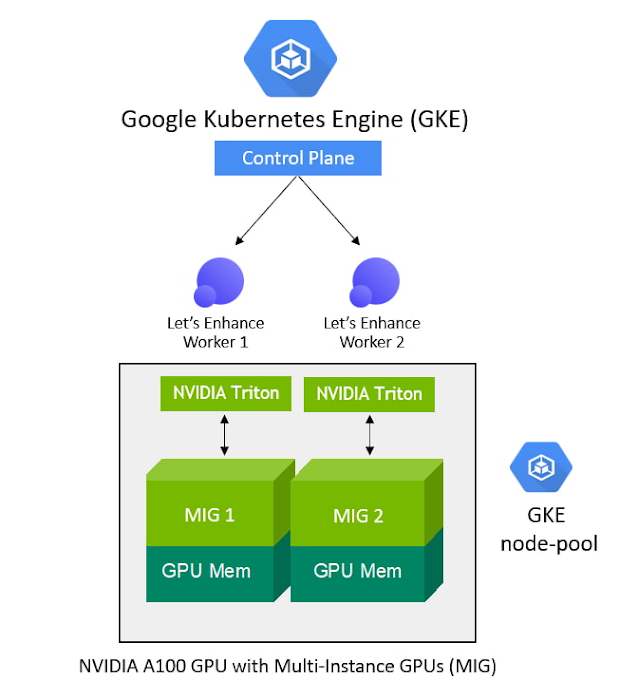
NVIDIA GPU と NVIDIA GPU の共有機能をサポートしている GKE では、複数の A100 MIG インスタンスをプロビジョニングしてユーザー リクエストを並列処理し、使用率を最大化できます。デプロイされた ML パイプラインにさらにコンピューティング能力が必要になると(対応する推論リクエストの数が急増するなど)、GKE は MIG パーティションを使用するノードプールを自動的に追加しスケーリングします。しかも、あらゆる規模のワークロードに適切なサイズの GPU アクセラレーションをきめ細かくプロビジョニングすることもできます。
「以前の合計スループットの平均は 1 秒あたり 10~80 点の画像処理とばらつきがありました。GKE でサポートされている NVIDIA A100 MIG と自動スケーリング メカニズムのおかげで、今ではユーザー デマンドと GPU の可用性に応じて 1 秒あたり 150 点を超えるまでにスケールアップできるようになっています。」Let’s Enhance の共同創設者兼 CTO の Vlad Pranskevičius 氏はこのように述べています。
さらに、GKE は動的なスケジュール設定、自動的なメンテナンスとアップグレード、高可用性、ジョブ API、カスタマイズ性、フォールト トレランスをサポートしていることから、本番のデプロイ環境の管理が単純になります。そのため、Let’s Enhance チームは高度な ML パイプラインの構築に注力できます。
NVIDIA Triton Inference Server による高パフォーマンスの推論のサービング
DNN モデルのパフォーマンスを最適化するとともに、GKE が管理する NVIDIA A100 MIG インスタンスのノードプールへの DNN モデルのデプロイを単純化するために Let’s Enhance が選んだのはオープンソースの NVIDIA Triton Inference Server です。この推論サーバーは任意のフレームワークで構築された AI モデルを任意の GPU または CPU ベースのインフラストラクチャにデプロイして実行し、スケーリングできます。
NVIDIA Triton は複数のフレームワークをサポートするため、Let’s Enhance チームは TensorFlow と PyTorch の両方でトレーニングされたモデルでサービスを提供できます。つまり、異なるフレームワーク バックエンドごとにサービス提供ソリューションを設定して保守する必要がなくなりました。さらに、Triton のアンサンブル モデルと共有メモリの機能を利用して、複数のモデル間で大量の元画像が転送され処理されるエンドツーエンドのパイプラインのパフォーマンスを最大化し、データ転送のオーバーヘッドを最小化できるようになりました。
「カスタムの推論サービスコードを使用する場合と比べ、Triton ではパフォーマンスが 20% 以上向上しました。しかも、Triton の自己修復機能により、デプロイの際に複数のエラーを修復できました。Triton には優れた機能が詰め込まれています。当初から進捗状況を観察していましたが、製品開発の速さは圧倒的です」と Vlad 氏は述べています。
エンドツーエンドの推論パフォーマンスをさらに向上させるために、チームは現在 NVIDIA TensorRT を導入しています。これは、予測の精度を維持しつつ、トレーニング済みモデルを最大限のスループットと最小限のレイテンシでデプロイできるように最適化するための SDK です。
「TensorFlow から NVIDIA TensorRT に変換したモデルのサブセットで、処理速度がモデルによって 10~42% 加速されました。これは素晴らしい成果です。弊社で使用しているようなメモリ使用量の多いモデルの場合、メモリ使用量を予測できるようになったことも、TensorRT を使用する大きなメリットの一つです。これにより、本番環境でのデプロイ中に予期しないメモリ関係の問題を防ぐことができるからです」と Vlad は説明します。
チームワークで夢を現実に
Let’s Enhance は Google Cloud と NVIDIA を使用してリアルタイムの推論のサービングとインフラストラクチャの管理に伴う課題に対処し、AI 対応のサービスを安全な Google Cloud インフラストラクチャの本番環境に大規模に移行することに成功しました。
GKE、NVIDIA AI ソフトウェア、そして NVIDIA A100 GPU を搭載した A2 VM により、同社が目的とするユーザー エクスペリエンスが実現するとともに、エンドツーエンドのパイプラインをユーザー デマンドに応じて動的にスケーリングできるソリューションを構築するために必要なすべての要素が揃いました。
あらゆるステップでの Google Cloud と NVIDIA チームの緊密な連携も、ソリューションを迅速に市場に投入できた要因です。「Google Cloud と NVIDIA チームとの連携は目を見張るほど素晴らしいものでした。極めてプロフェッショナルで、常にすばやく対応し、弊社の成功に向けて誠意を尽くしてくれました。Google Cloud のプロダクト チームとエンジニアリング チームから直接、技術的なアドバイスや最適化案を聞くことができましたし、Google Cloud プロダクトに関するフィードバックを共有するチャネルもありました。これは私たちにとって非常に重要なことでした」と Vlad 氏は語っています。
増大するビジネスニーズに対応できる強固な基盤とソリューション アーキテクチャを確立した Let’s Enhance は、AI で補正されたデジタル画像を誰もが利用できるようにするという目標に向かって突き進んでいます。「私たちのビジョンは、次世代の AI ツールによって企業がユーザー生成のコンテンツを効率的に管理できるようにして、コンバージョン率を伸ばすことです。このビジョンを実現するための次のステップとして、手作業による写真の準備を完全に置き換えるべく、弊社のサービスを拡大しているところです。これには、準備段階での画像品質評価とモデレーションも含まれます」と Sofi 氏は語ります。
Let’s Enhance の製品とサービスについて詳しくは、同社のブログをご覧ください。
- NVIDIA データセンター シニア プロダクト マーケティング マネージャー、Uttara Kumar 氏
- Google Kubernetes Engine グループ プロダクト マネージャー、Maulin Patel


