クラウド ML アプリケーションの NCCL パフォーマンスの向上
Google Cloud Japan Team
※この投稿は米国時間 2021 年 5 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウドは、機械学習(ML)に特化したハードウェアをオンデマンドでスケールし、アジリティを高めることができるため、ディープ ニューラル ネットワークのトレーニングには最適なオプションです。さらに、クラウドでは簡単に始められ、従量課金制の利用モデルが用意されています。またクラウドでは、最新の GPU 技術が開発されると同時に、お客様にも提供されます。
大規模なデータセットにディープ ニューラル ネットワークを採用する際の大きなハードルは、トレーニングに必要な時間とリソースです。ディープ ラーニング モデルを本番環境で使用するには、頻繁に再トレーニングを行う必要があるため、トレーニング時間を最小限に抑えることが重要になります。また、より高い予測精度を実現するために、モデルはさらに大きく複雑になり、大量のコンピューティングとストレージ リソースが必要になります。お客様の最大の関心はやはり費用対効果です。ディープ ラーニングのワークロードにクラウドを効果的に利用するには、ノード間レイテンシの最適化が不可欠です。
TensorFlow や PyTorch といったような ML フレームワークは、分散ノード間 GPU 通信に NCCL ライブラリを使用します。NVIDIA Collective Communication Library(NCCL)は、広く使用されている通信ライブラリであり、ニューラル ネットワークの素早い収束のために不可欠なマルチ GPU およびマルチノード通信を提供します。また、NCCL は、all-gather、all-reduce、broadcast、reduce、reduce-scatter、point-to-point send、point-to-point receive などのルーティンを提供します。ルーティンは、ノード内およびノード間のネットワークで高帯域幅と低レイテンシを実現するように最適化されています。
NCCL のメッセージ レイテンシの低減は、アプリケーションの高いパフォーマンスとスケーラビリティを実現するための重要な要素です。Google は最近、Google Cloud 上で NCCL のワークロードを簡単に実行し、最適なパフォーマンスを得るための機能や調整をいくつか紹介しました。「ベスト プラクティス」と呼ばれるこれらのアップデートにより、小規模メッセージやグループ演算を多用するアプリケーションにおいて、NCCL レイテンシの低減が期待できます。
このブログ投稿では、GCP インフラストラクチャを最適化し、ディープ ラーニング トレーニングの時間を最小化する方法についてご説明します。まずは、NCCL を使った分散 / マルチノードの同期トレーニングを見てみましょう。
Google Cloud で NCCL の最適なパフォーマンスを実現
1. NCCL Fast Socket で最新の DLVM を使用する
分散型 ML のトレーニングにおいて、NCCL のグループ通信性能を最大限に引き出すために、NCCL Fast Socket という通信ライブラリを設計しました。NCCL Fast Socket は、NCCL のトランスポート プラグインとして開発され、Google Cloud 上での NCCL のパフォーマンスを大幅に向上させる最適化機能を備えています。最適化機能には以下のようなものがあります。
最大スループットを達成するための複数のネットワーク フローの利用。NCCL Fast Socket では、複数の通信要求のオーバーラップの改善など、NCCL の組み込みマルチストリームのサポートが最適化されています。
複数のネットワーク フローの動的負荷分散。NCCL は、変化するネットワークやホストの状況にも対応します。この最適化によって、ストラグラー ネットワーク フローが NCCL 全体のオペレーションを大幅に遅らせることはありません。
Google Cloud の Andromeda 仮想ネットワーク スタックとの統合。これにより、Andromeda とゲスト仮想マシン(VM)の両方で競合を回避し、ネットワーク全体のスループットが向上します。
最も重要な点は、NCCL のコアライブラリが実行時に NCCL Fast Socket を動的に読み込めることです。そのため、Google Cloud のユーザーは、アプリケーションや TensorFlow や PyTorch などの ML フレームワーク、さらには NCCL ライブラリ自体を変更または再コンパイルすることなく、NCCL Fast Socket を利用できます。
現在、最新の Deep Learning VM(DLVM)イメージ リリースには、NCCL Fast Socket が含まれています。DLVM に含まれる NCCL ライブラリを使用すると、自動的にアクティブになります。また、こちらの手順に沿って、手動で NCCL Fast Socket をインストールすることもできます。
2. gVNIC を使う
NCCL でさらに高いネットワーク スループットを実現するには、VM インスタンスの作成時に Google Virtual NIC(gVNIC)を有効にする必要があります。GPU を搭載したものや分散型 ML トレーニングに使用するものなど、高いパフォーマンスと高いネットワーク スループットを必要とする VM には、デフォルトのネットワーク インターフェースとして gVNIC を使用することをおすすめします。現在、gVNIC は最大 100 Gbps のネットワーク スループットのサポートが可能であり、NCCL のパフォーマンスの大幅な向上につながっています。gVNIC の使用方法について詳しくは、gVNIC ガイドをご覧ください。DLVM は、すぐに使用できる gVNIC をサポートするイメージも提供します。
3. 利用可能な帯域幅の最大化
VM 内の GPU 通信は、NVIDIA NVLink を利用でき、VM 間のネットワークよりも高いスループットを実現することが可能です。そのため、NVLink の帯域幅を最大限に利用するために、できるだけ多くの GPU を 1 つの VM に搭載することをおすすめします。複数の VM で作業する場合は、利用可能なネットワーク帯域幅を最大限にするために、高い vCPU 数(96)を使用することを推奨します。詳しくは、ネットワーク帯域幅と GPU のドキュメント ページをご覧ください。
4. コンパクト プレースメント ポリシーを使用する
N1 などの特定の GPU VM タイプは、コンパクト プレースメント ポリシーに対応しています。VM を近接して割り振ることで、ネットワーク性能が向上し、干渉も少なくなります。分散型トレーニングはレイテンシの影響を受けやすいため、コンパクト プレースメントをサポートする VM タイプを使用するようにしてください。詳しくは、プレースメント ポリシーのドキュメント ページをご覧ください。
パフォーマンス データの改善例
NCCL Fast Socket は NCCL のグループ演算と ML モデルの分配トレーニングの両方のパフォーマンスを向上させます。以下に、NCCL Fast Socket とストック NCCL を比較した例を示します(テストでは、NCCL Fast Socket は同じ数のネットワーク フローとヘルパー スレッドを使用しました)。gVNIC ドライバのバージョンは 1.0.0 を使用しています。
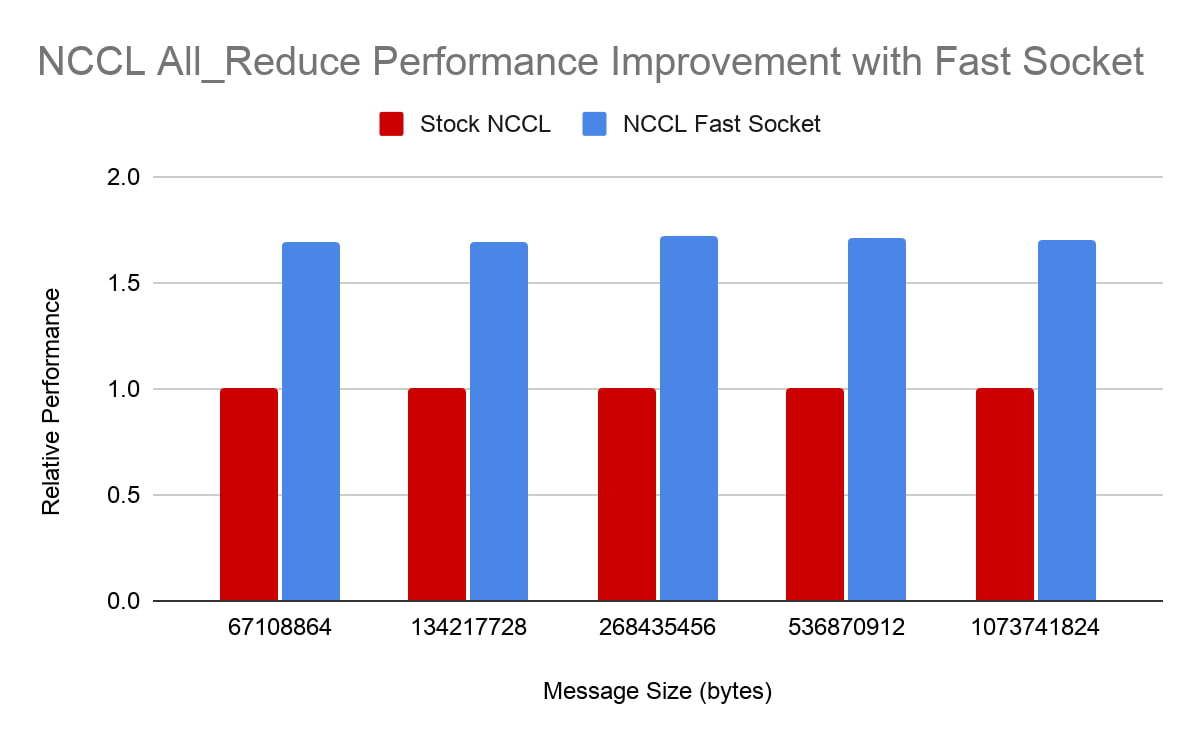
NCCL All_Reduce
All_Reduce は、NCCL の最も重要なグループ演算の一つです。ML モデルの分散トレーニングにおける勾配集約に頻繁に使用されます。図では、2 つの VM に 16 個の NVIDIA V100 GPU を搭載した NCCL All_Reduce テストのパフォーマンスを示しています。この図からは、NCCL Fast socket がさまざまなメッセージ サイズ全体で All_Reduce のパフォーマンスを大幅かつ一貫して改善していることがわかります(図中の棒グラフが高いほど性能が良いことを示しています)。
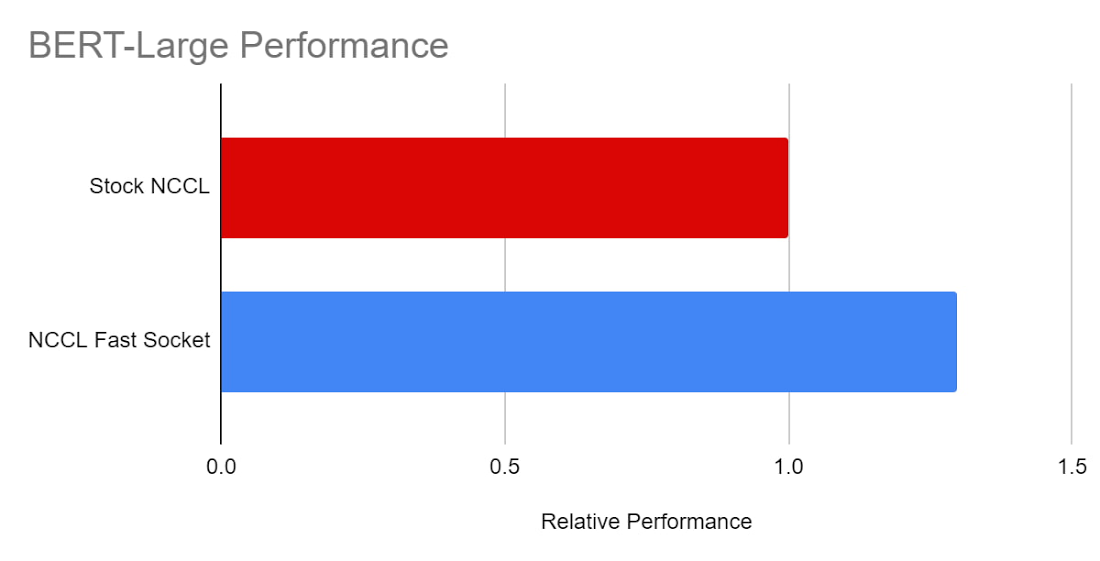
BERT-Large
また、TensorFlow モデル、BERT-Large においても NCCL Fast Socket のパフォーマンスの向上をテストしました。テストには、8 つの VM に 64 個の NVIDIA V100 GPU を使用しました。NCCL Fast Socket を使用することで、BERT-Large のトレーニング速度が大幅に向上していることがわかります(約 30%)。
Google Cloud で NCCL アプリケーションを素早く簡単に実行
Google Cloud での NCCL アプリケーションの実行は、これまでになく簡単になりました。これらのベスト プラクティス(NCCL Fast Socket の使用を含む)を適用することで、アプリケーションのパフォーマンスを向上させることができます。NCCL Fast Socket のデプロイを容易にするために、DLVM イメージに含め、Google Cloud 上の NCCL ワークロードですぐに最高水準のパフォーマンスを得ることができるようにしました。
詳しくは、Fast Socket でのより高速なネットワーク帯域幅の使用に関するドキュメントをご覧ください。
Chang Lan と Soroush Radpour の協力に感謝します。
-ネットワーク インフラストラクチャ担当エンジニア Jiuxing Liu
-ネットワーキング担当グループ プロダクト マネージャー Manoj Jayadevan



