Improving NCCL performance for cloud ML applications
Jiuxing Liu
Engineer, Network Infrastructure
Manoj Jayadevan
Group Product Manager, Networking
The cloud is a great option for training deep neural networks because it offers the ability to scale on demand for specialized machine learning (ML) hardware, which provides increased agility. In addition, the cloud makes it easy to get started, and it provides pay-as-you-go usage models. Cloud also brings the latest GPU technologies to customers as and when it’s developed.
A key barrier to adopting deep neural networks on large datasets is the time and resources required to train them. Since using deep learning models in production requires frequent retraining, minimizing training time becomes critical. Also, to drive higher prediction accuracy, models are getting larger and more complex, thus needing a high volume of compute and storage resources. Price to performance still remains a concern for customers, and optimizing inter-node latency is crucial for effective use of cloud for deep learning workloads.
ML frameworks (such as TensorFlow or PyTorch) use NCCL libraries for distributed inter-node GPU communications. The NVIDIA Collective Communication Library (NCCL) is a commonly-used communication library that provides multi-GPU and multi-node communication integral for neural networks to converge quickly. NCCL also provides routines such as all-gather, all-reduce, broadcast, reduce, reduce-scatter, and point-to-point send and receive. Routines are optimized to achieve high bandwidth and low latency within a node and over the network across nodes.
Reducing NCCL message latency is one vital element of delivering high application performance and scalability. We recently introduced several features and tunings that make it easy to run NCCL workloads and achieve optimal performance on Google Cloud. Collectively referred to as ‘best practices,’ these updates reduce NCCL latency and benefit applications that depend on small messages and collective operations.
This blog post demonstrates how to optimize GCP infrastructure to minimize deep learning training times. To achieve this, we’ll look at distributed/multi-node synchronous training using NCCL.
Achieve optimal NCCL performance in Google Cloud
1. Use latest DLVM with NCCL Fast Socket
To maximize NCCL collective communication performance for distributed ML training, we have designed a communication library called NCCL Fast Socket. Developed as an NCCL transport plugin, NCCL Fast Socket introduces optimizations that significantly improve NCCL performance on Google Cloud. The optimizations include:
Use of multiple network flows to achieve maximum throughput. NCCL Fast Socket introduces additional optimizations over NCCL’s built-in multi-stream support, including better overlapping of multiple communication requests.
Dynamic load balancing of multiple network flows. NCCL can adapt to changing network and host conditions. With this optimization, straggler network flows will not significantly slow down the entire NCCL collective operation.
Integration with Google Cloud’s Andromeda virtual network stack. This increases overall network throughput by avoiding contentions in both Andromeda and guest virtual machines (VMs).
Most importantly, the core NCCL library can dynamically load NCCL Fast Socket at run time. Hence, Google Cloud users can take advantage of NCCL Fast Socket without changing or recompiling their applications, ML frameworks (such as TensorFlow or PyTorch), or even the NCCL library itself.
Currently, the latest Deep Learning VM (DLVM) image release includes NCCL Fast Socket. It’s activated automatically when you use the NCCL library included in DLVM. You can also manually install NCCL Fast Socket by following the instructions here.
2. Use gVNIC
To achieve better network throughput in NCCL, be sure to enable Google Virtual NICs (gVNICs) when creating VM instances. For VMs with high performance and high network throughput requirements—such as those with GPUs and used for distributed ML training—we recommend using gVNIC as the default network interface. Currently, gVNIC can support network throughput up to 100 Gbps which provides a significant performance boost to NCCL. For detailed instructions on how to use gVNICs, please refer to the gVNIC guide. DLVM also provides images that support gVNIC out of the box.
3. Maximize available bandwidth
Within a VM, GPU communication can take advantage of NVIDIA NVLink, which can achieve higher throughput than networking between VMs. Therefore, we recommend packing as many GPUs as possible in a single VM to maximize the usage of NVLink bandwidth. When working with multiple VMs, we recommend using high vCPU count (96) to maximize available networking bandwidth. Find more information on the network bandwidth and GPUs documentation page.
4. Use compact placement policies
Certain GPU VM types (such as N1) can support compact placement policies. AllocatingVMs close to each other results in improved network performance and less interference. Because distributed training can be latency sensitive, be sure to use a VM type that supports compact placements. You can find more information on the placement policy documentation page.
Examples of improved performance data:
NCCL Fast Socket improves performance for both NCCL collective operations and distributed training of ML models. We show some examples below which compare NCCL Fast Socket with stock NCCL. (In our tests, NCCL Fast Socket used the same number of network flows and helper threads.) We used the gVNIC driver version v1.0.0.
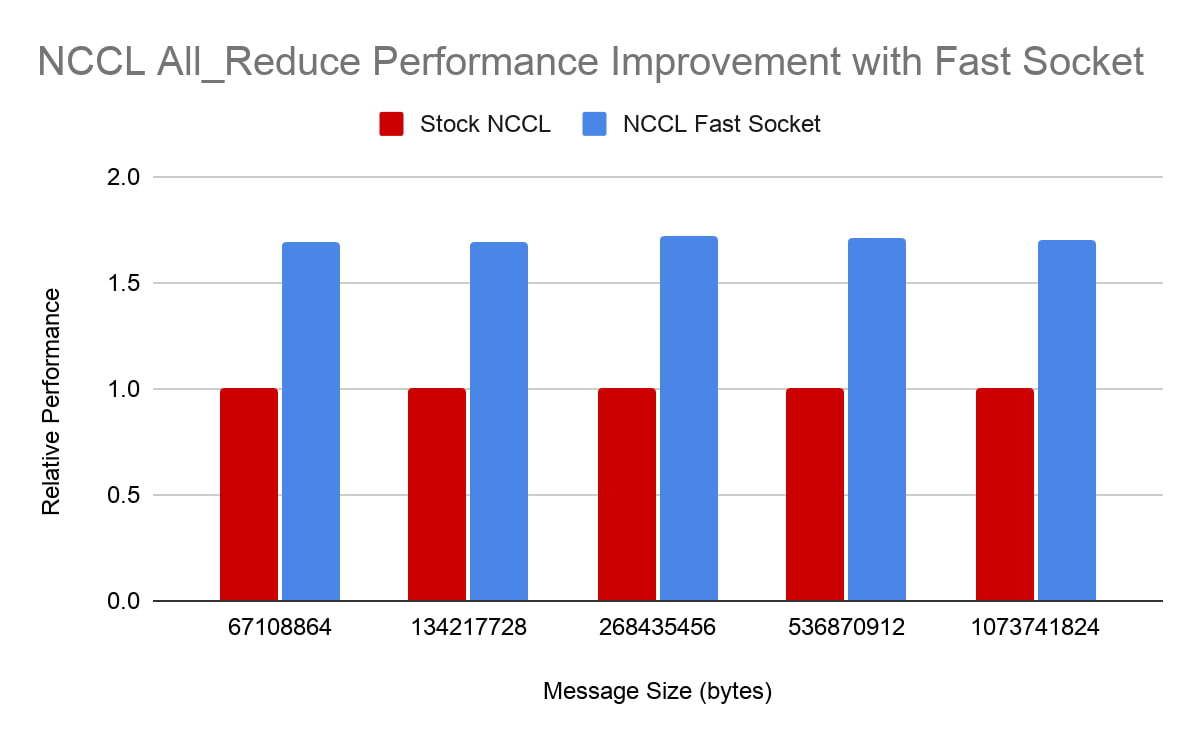
NCCL All_Reduce
All_Reduce is one of the most important collective operations in NCCL. It’sused frequently for gradient aggregation in distributed training of ML models. In the figure, we show the performance of NCCL All_Reduce tests with 16 NVIDIA V100 GPUs on two VMs. From the figure, we can see that NCCL Fast socket improves All_Reduce performance significantly and consistently across a range of message sizes. (Higher bars indicate better performance in the figure.)
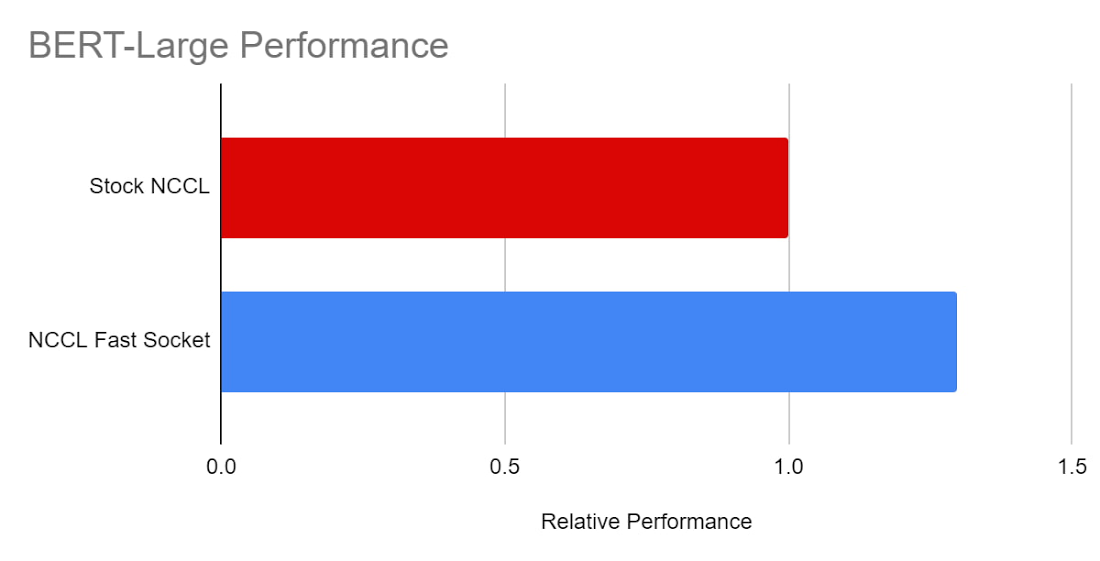
BERT-Large
We also tested performance improvement of NCCL Fast Socket on a TensorFlow model: BERT-Large. We conducted the test using 64 NVIDIA V100 GPUs on eight VMs. We can see that the use of NCCL Fast Socket increases the training speed of BERT-Large significantly (by around 30%).
NCCL applications on Google Cloud is now faster and easier to run
Running NCCL applications on Google Cloud has never been easier. Applying these best practices (including using NCCL Fast Socket) can improve application performance. To simplify deployment of NCCL Fast Socket, we included it in the DLVM images to get the best out-of-the-box performance for your NCCL workloads on Google Cloud.
To learn more, visit our documentation on using higher network bandwidth speeds with Fast Socket.
Special thanks to Chang Lan and Soroush Radpour for their contributions.



