Hex-LLM: Vertex AI Model Garden の高効率な大規模言語モデルのサービングを TPU で利用可能に
Xiang Xu
Software Engineer, Google
Pengchong Jin
Software Engineer, Google
※この投稿は米国時間 2024 年 7 月 27 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud が Vertex AI Model Garden で目指しているのは、費用が最適化された高効率な ML ワークフロー レシピを提供することです。現在 Vertex AI Model Garden では、150 種類以上の厳選された自社製、オープンソース、サードパーティの基盤モデルを提供しています。昨年は、GPU でよく使われるオープンソース LLM サービング スタックの vLLM を Vertex Model Garden に導入しました。それ以降、サービング デプロイは迅速な成長を遂げてきました。このたび、TPU へのデプロイを可能にする Hex-LLM(High-Efficiency LLM Serving with XLA)を Vertex AI Model Garden に導入することになりました。
Hex-LLM は Vertex AI の社内 LLM サービング フレームワークであり、AI ハイパーコンピュータに含まれる Google の Cloud TPU ハードウェア向けに設計、最適化されています。Hex-LLM は、連続的なバッチ処理やアテンションの分割などの最新の LLM サービング テクノロジーと、XLA / TPU 向けにカスタマイズされた社内最適化を組み合わせた、高効率かつ低費用の最新 LLM サービング ソリューションであり、TPU へのオープンソース モデルのデプロイを可能にします。現在 Hex-LLM は、プレイグラウンド、ノートブック、ワンクリック デプロイを介して Vertex AI Model Garden でご利用いただけます。皆様が Hex-LLM と Cloud TPU を LLM サービング ワークフローでどのように活用されるのか、楽しみにしています。
設計とベンチマーク
Hex-LLM は、vLLM や FlashAttention などの成功を収めた多数のオープンソース プロジェクトから着想を得て、最新の LLM サービング テクノロジーと、XLA / TPU 向けにカスタマイズされた社内最適化を取り入れたソリューションです。
Hex-LLM では主に以下の点が最適化されています。
-
トークンベースの連続的なバッチ処理アルゴリズムによる、KV キャッシングのメモリ使用率の最大化。
-
XLA / TPU 向けに最適化された、PagedAttention カーネルの完全な書き換え。
-
特殊な重みシャーディング最適化を適用した、柔軟でコンポーズ可能なデータ並列処理戦略とテンソル並列処理戦略による、複数の TPU チップでの大規模モデルの効率的な実行。
さらに、Hex-LLM は、次のようなよく使われる高密度およびスパースの LLM モデルを幅広くサポートしています。
-
Gemma 2B、7B
-
Gemma 2 9B、27B
-
Llama 2 7B、13B、70B
-
Llama 3 8B、70B
-
Mistral 7B、Mixtral 8x7B
LLM 分野は進化し続けているため、Google Cloud は、さらに高度なテクノロジーと最新の優れた基盤モデルを Hex-LLM に取り入れようと尽力しています。
高スループットと低レイテンシを実現する Hex-LLM は、競争力に優れたパフォーマンスを提供します。Google Cloud が実施したベンチマーク テストで測定された指標の詳細は次のとおりです。
-
TPS(1 秒あたりのトークン数)は、LLM サーバーが 1 秒ごとに受け取るトークンの平均数です。一般的なサーバーのトラフィックを測定するために使用される QPS(秒間クエリ数)と似ていますが、TPS は LLM サーバーのトラフィックをよりきめ細かく測定するためのものです。
-
スループットは、特定の TPS で一定期間にサーバーが生成できるトークンの数を測定します。多数の同時リクエストを処理する能力を推定するための主要な指標です。
-
レイテンシは、特定の TPS で 1 つの出力トークンを生成するための平均時間を測定します。これにより、キューにかかった時間と処理時間すべてを含め、リクエストごとにサーバーサイドで費やされる時間全体を推定できます。
通常は、高スループットと低レイテンシの間にはトレードオフの関係があります。TPS が増加すると、スループットとレイテンシの両方が増加するはずです。スループットは特定の TPS で飽和状態になる一方、レイテンシは TPS の上昇に応じて増加し続けます。そのため、特定の TPS をもとに、サーバーのスループットとレイテンシの指標のペアを測定できます。結果として得られる、さまざまな TPS でのスループットとレイテンシを示したプロットにより、LLM サーバーのパフォーマンスを正確に測定できます。
Hex-LLM のベンチマークのために使用されたデータは、さまざまな長さのプロンプトと出力を含む、幅広い領域で採用されている ShareGPT データセットからサンプリングされたものです。
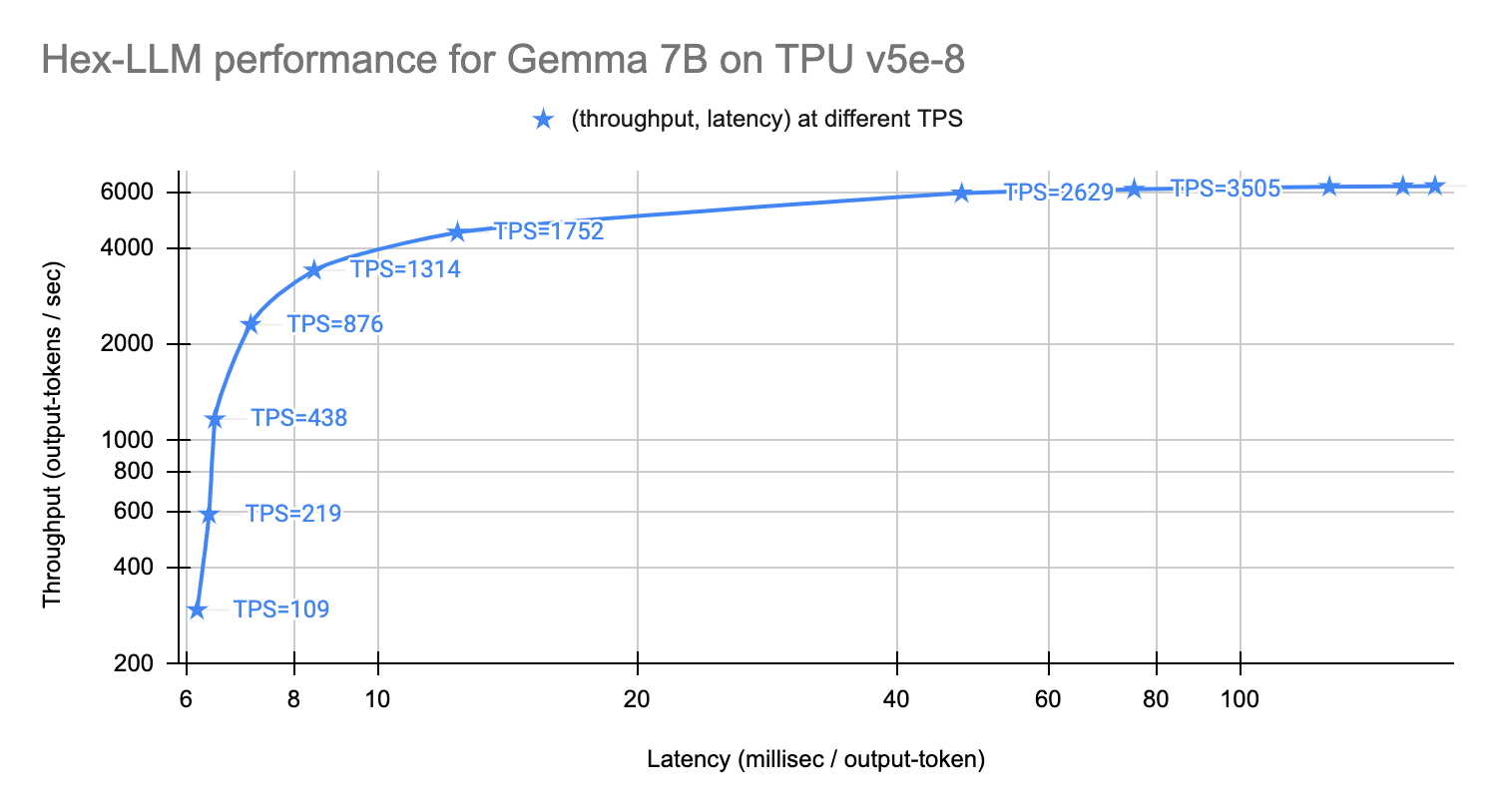
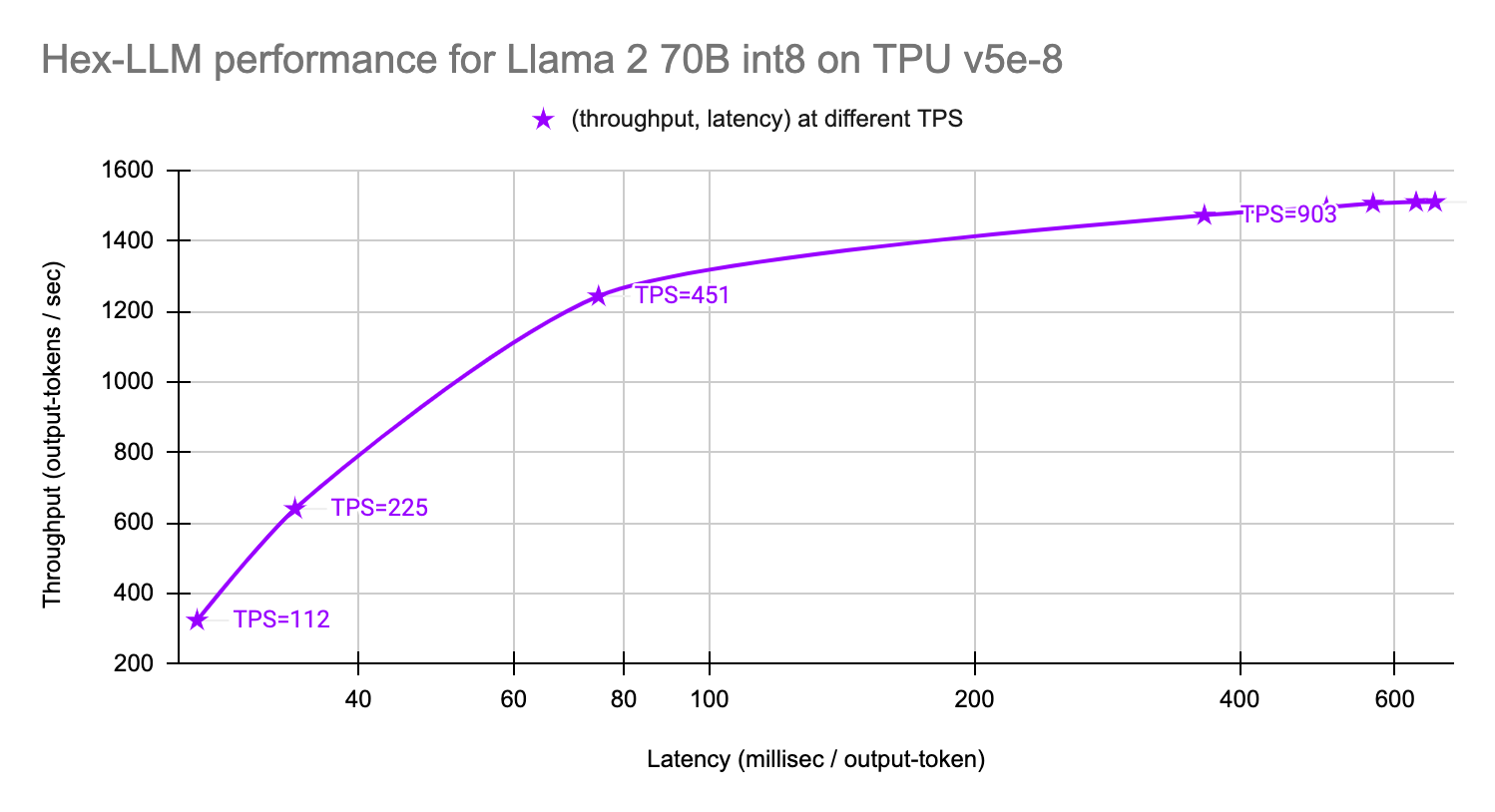
以下のグラフは、8 個の TPU v5e チップでの Gemma 7B モデルと Llama 2 70B(int8 重み量子化済み)モデルのパフォーマンスを示しています。
-
Gemma 7B モデル: 最低 TPS では出力トークンあたり 6 ミリ秒、最高 TPS では 1 秒あたり 6,250 個の出力トークン。
- Llama 2 70B int8 モデル: 最低 TPS では出力トークンあたり 26 ミリ秒、最高 TPS では 1 秒あたり 1,510 個の出力トークン。
Vertex AI Model Garden で使ってみる
Google Cloud は Hex-LLM TPU サービング コンテナを Vertex AI Model Garden に統合しました。このサービング テクノロジーは、プレイグラウンド、ワンクリック デプロイ、Colab Enterprise ノートブックの例を介してさまざまなモデルで利用できます。
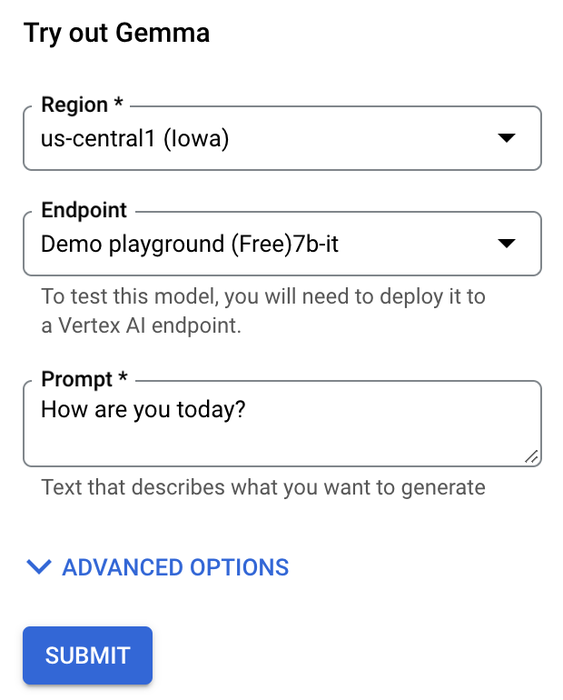
Vertex AI Model Garden のプレイグラウンドは、あらかじめデプロイされた Vertex AI Prediction エンドポイントであり、UI に統合されています。ユーザーがプロンプトのテキストとリクエストのオプションの引数を入力し、[送信] ボタンをクリックすると、モデルから即座に応答が返されます。Gemma で試してみましょう。
Hex-LLM を使用してカスタムの Vertex Prediction エンドポイントをデプロイする場合、モデルカードの UI からワンクリックでデプロイする方法が最も簡単です。
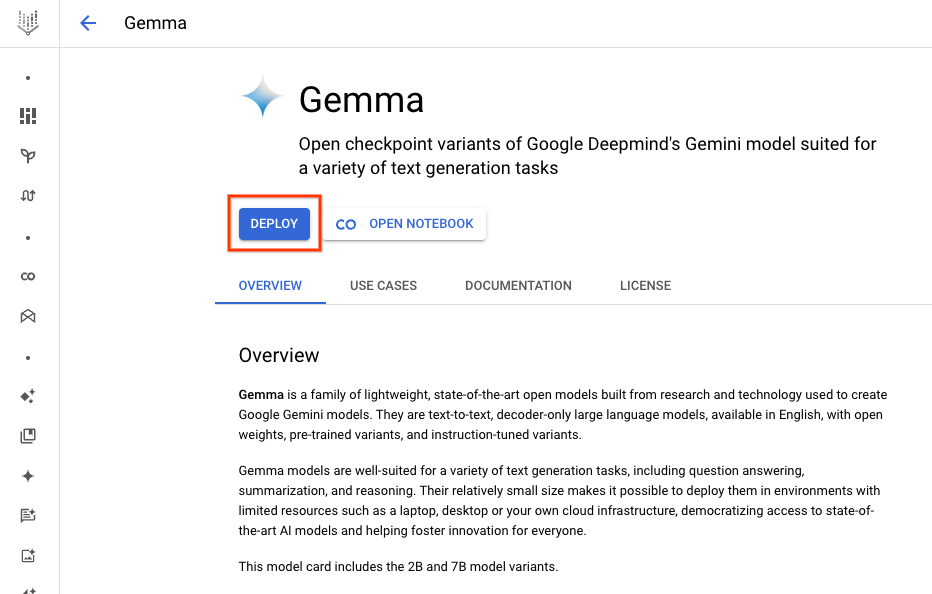
1. モデルカードのページに移動し、[デプロイ] ボタンをクリックします。
2. 対象となるモデルのバリエーションについて、デプロイ用に TPU v5e マシンタイプの ct5lp-hightpu-*t を選択します。下部にある [デプロイ] をクリックして、デプロイ プロセスを開始します。モデルがアップロードされたときとエンドポイントの準備ができたときに、それぞれ 1 通ずつ通知メールが届きます。
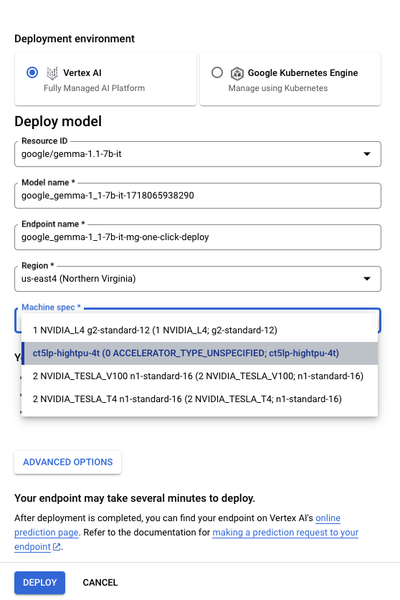
柔軟性を最大限に高めるには、Colab Enterprise ノートブックの例を参考に、Vertex Python SDK を使用して Hex-LLM で Vertex Prediction エンドポイントをデプロイできます。
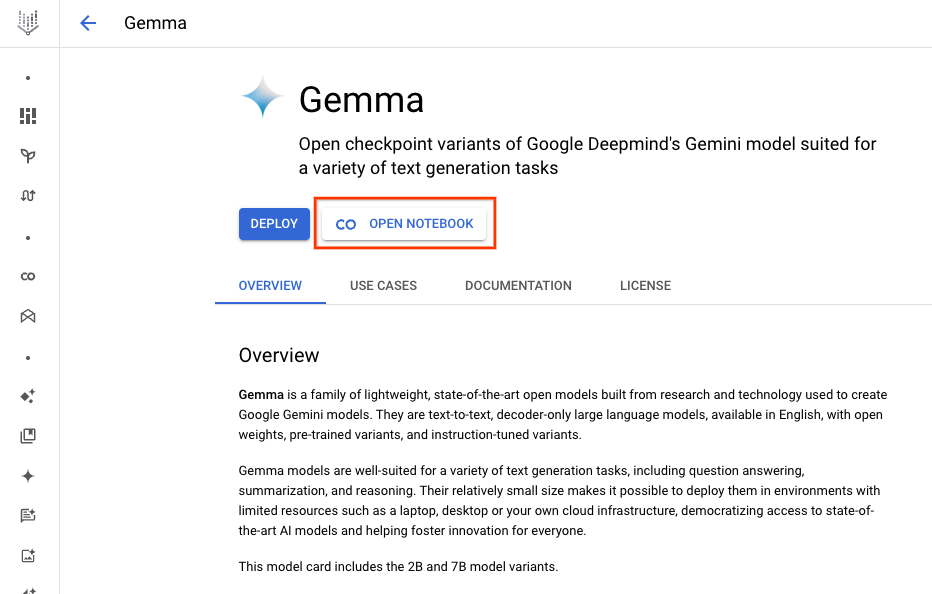
1. モデルカードのページに移動し、[ノートブックを開く] ボタンをクリックします。
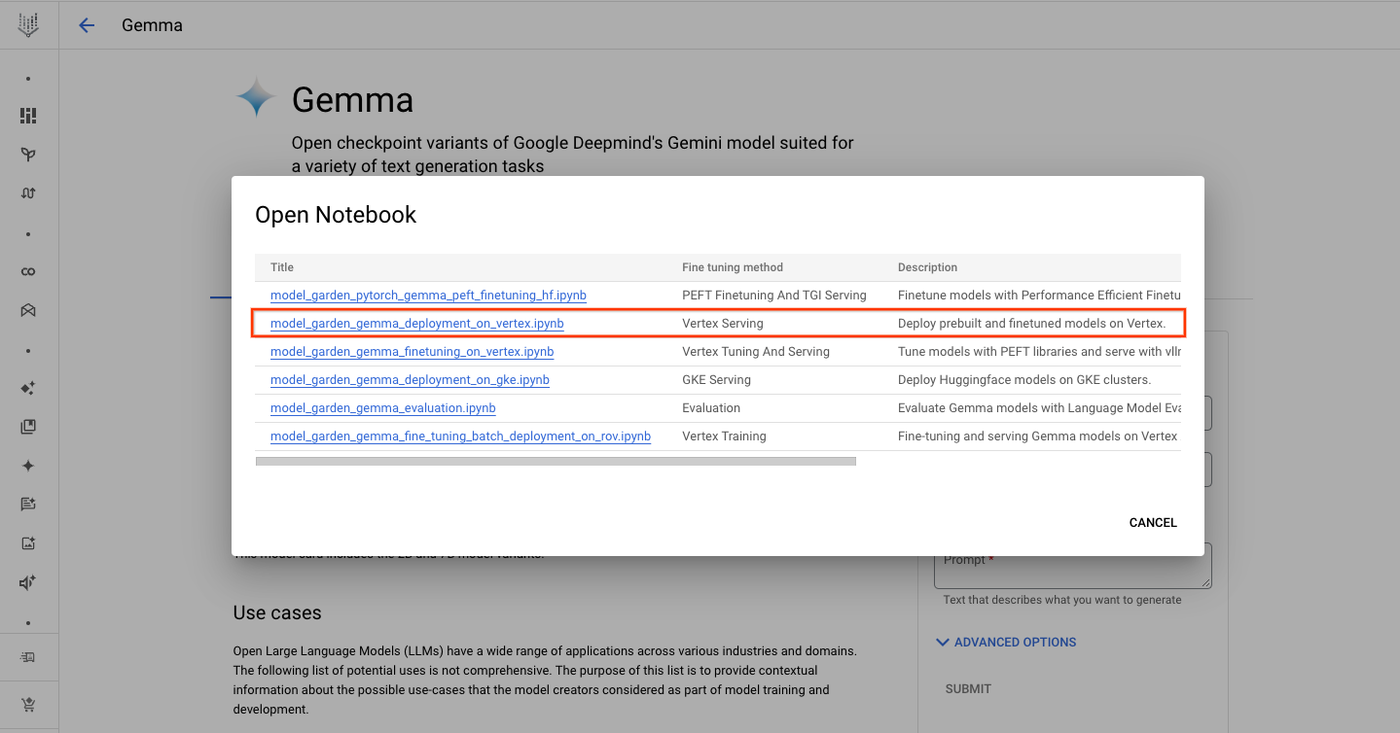
2. Vertex Serving ノートブックを選択します。Colab Enterprise でノートブックが開きます。
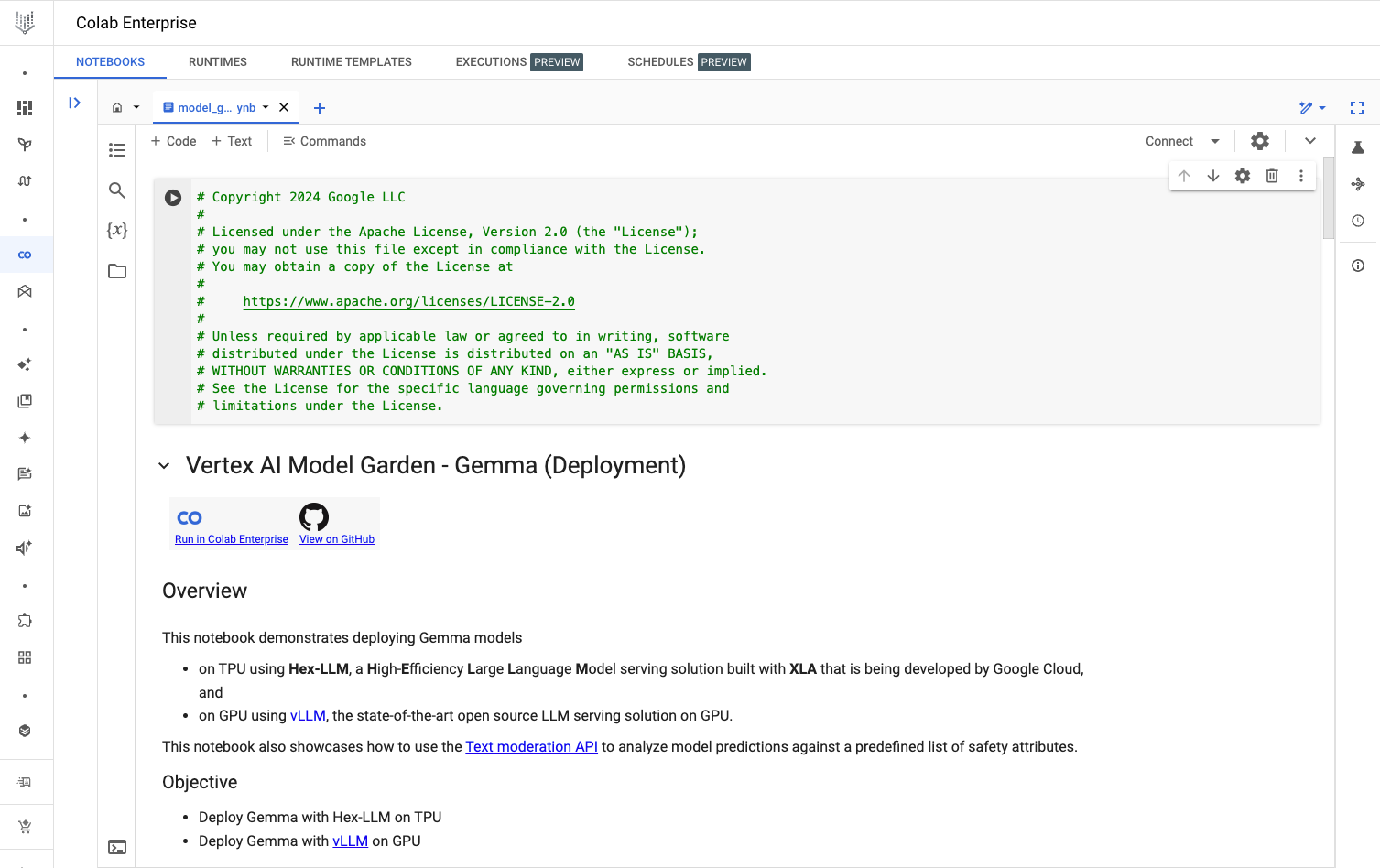
3. ノートブックを実行し、Hex-LLM を使用してデプロイを行い、予測リクエストをエンドポイントに送信します。
デプロイ機能のコード スニペットは次のとおりです。
ここで、ユーザーは必要に応じて最適な形にデプロイをカスタマイズできます。たとえば、予測される大量のトラフィックに対処するために、複数のレプリカを使用してデプロイできます。
次のステップ
Vertex AI が組織にもたらすメリットについて詳しくは、こちらをご覧ください。また、生成 AI を利用してイノベーションを実現している Google Cloud のお客様の手法については、How 7 businesses are putting Google Cloud’s AI innovations to work(Google Cloud の AI イノベーションを活用している 7 社の手法)をご覧ください。
ー Google ソフトウェア エンジニア Xiang Xu
ー Google ソフトウェア エンジニア Pengchong Jin


