Google Cloud、より高精度な音声認識 AI のための新モデルを発表
Google Cloud Japan Team
※この投稿は米国時間 2022 年 4 月 21 日に、Google Cloud blog に投稿されたものの抄訳です。
人間とコンピュータの対話における最先端の手段として音声が注目を集め続ける中、多くの企業は技術のレベルアップを図り、より確実で、正確にユーザーの言葉を認識する音声認識システムを消費者に提供しようとしています。考えてみてください。音声認識の品質が高まれば、友人や医師などと話すのと同じように、アプリケーションやデバイスに話しかけることができるようになるのです。
音声認識の向上により、運転者用のハンズフリー アプリケーション、スマート デバイスをまたいだ音声アシスタントなど、さまざまなユースケースが生まれます。さらに、正確な音声認識により、機械に指示を与えるだけでなく、ビデオ会議での自動字幕起こし、生の会話や録音された会話からのインサイト獲得など、さまざまなことが可能になります。5 年前に Google が Speech-to-Text(STT)API をリリースして以降、この技術に対するお客様の熱意は高まり、現在では API が処理する音声の量は毎月 10 億分以上にのぼります。10 億分といえば、ワーグナーの「ニーベルングの指環」(15 時間)を 110 万回以上聴ける時間です。1 分間に 140 語程度話すと仮定すると、シェイクスピアの最長の戯曲『ハムレット』を毎月 460 万回近く書き起こせます。
こうした状況を受け、本日 Google は STT API における最新モデルの提供を発表するとともに、それらのモデルにアクセスするための新しいモデルタグ「latest」もあわせてご案内します。技術の大幅な改善により、新しいモデルは STT がサポートする 23 の言語と 61 の地域において音声認識精度を向上させ、音声を通じてより効果的に顧客と大規模なつながりを持つことができるよう支援します。
精度と理解の向上を目指した新モデル
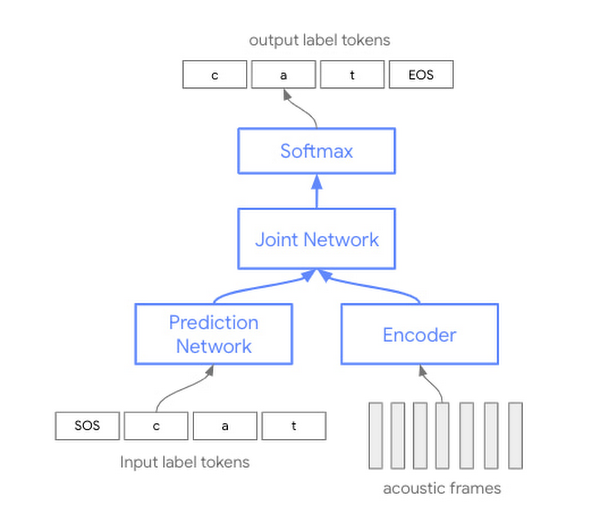
この新しい音声認識用ニューラル sequence-to-sequence モデルに向けた取り組みは、さまざまなユースケース、ノイズ環境、音響条件、ボキャブラリーにおいて最高の品質特性を実現するために膨大な研究、実装、最適化に尽力した約 8 年にわたる歩みにおいて、新たな一歩となるものです。新しいモデルの基盤となるアーキテクチャは、最先端の ML 手法に基づいたもので、音声学習データをより効率的に活用して最適な結果を得ることが可能になります。
このモデルと現在使用されているモデルとの違いは何でしょうか。
過去数年間における自動音声認識(ASR)技術は、音響、発音、言語それぞれに別のモデルを用意する手法に基づいたもので、この 3 つの要素をそれぞれ個別に学習させ、後から組み立てて音声認識を行っていました。
このたび発表するコンフォーマー モデルは、ただ 1 つのニューラル ネットワークをベースにしており、3 つのモデルを別々に学習させてからまとめる必要があった従来の方法に比べ、モデルのパラメータをより効率的に使用できます。具体的には、Transformer モデルを畳み込みレイヤ(コンフォーマーという名称の由来)で補強することで、音声シグナルのローカル情報とグローバル情報の両方を取得できるようになりました。
STT API をお使いいただくと、すぐに品質の向上を実感されることでしょう。この新しいアーキテクチャの利点は、最初のチューニングをしなくても感じ取っていただけます(もちろん、パフォーマンス向上のためにモデルのチューニングはいつでも可能です)。より幅広い声の種類、ノイズ環境、音響条件をサポートすることで、より多くの状況下でより正確な出力が可能となり、さらに迅速、簡単、かつ効果的に、音声技術をアプリケーションに組み込むことができます。
スマート デバイスやアプリケーションにユーザーが話しかける音声操作インターフェースの構築に関しては、このたびの改善により、より自然な、より長いフレーズを扱うことが可能になります。ユーザーにとっては話したことが正確にキャプチャされるかどうかの心配がなくなり、対話する機械やアプリケーションと、さらにはその体験の背後にあるブランドである貴社と、より良い関係が確立されます。
新しいモデルを先行してお使いになっているお客様は、すでにその効果を実感していらっしゃいます。Spotify のテクノロジー ハードウェア製品責任者 Daniel Bromand 氏は次のように述べています。「Spotify は Google と緊密に連携し、当社のモバイルアプリと Car Thing において、まったく新しい音声インターフェースである『Hey Spotify』をお客様に公開しました。Spotify の NLU と AI に関する取り組みに加え、最新モデルによる品質向上とノイズ耐性によって、非常に多くのお客様にこれらのサービスをとても快適にお使いいただいています。」
前述したように、既存のモデルを維持しつつ、新たなモデルをサポートするために、STT API では新しい識別子である「latest」を同時に導入しています。「latest long」または 「latest short」を指定すると、継続的に更新される最新のコンフォーマー モデルにアクセスできるしくみです。「latest long」は、既存の「video」モデルと同様に、長い文章の自然発話に特化したモデルです。一方、「latest short」は、コマンドやフレーズのような短い発話の処理において、高い品質と優れたレイテンシを実現します。
Google の最新の音声認識研究を皆様にお届けするため、これらのモデルを継続的に更新していくことをお約束します。これらのモデルの機能は「default」や「command_and_search」などの既存のものと若干異なる場合がありますが、いずれも一般提供されている他の STT API サービスと同様の安定性とサポートが保証されます。機能の正確な提供状況については、こちらのドキュメントをご確認ください。
より良い対話に向けた準備
この技術向上は、Google および Alphabet のさまざまなチームによる広範囲に及ぶコラボレーションが結実したものです。その研究成果を、このたびデベロッパーや企業の皆様にご提供できることを誇らしく思います。現在 STT をご利用のお客様には、本日より「latest」をお試しいただけます。新規のお客様には、「latest」モデルを料金なしでお試しいただけます。ぜひトライアルを開始してください。
- スピーチチーム、特別研究員、Françoise Beaufays




