Document AI に ML Workbench を使用したワンクリック モデル トレーニングを追加
Google Cloud Japan Team
※この投稿は米国時間 2022 年 10 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
毎日、数えきれないほどのドキュメントが作成され、改訂され、組織全体で共有されています。その結果、情報の宝の山が築かれますが、データは基本的に構造化されておらず、行や列などの事前に定義された組織的スキーマが含まれていないため、解釈や分析が困難でビジネス プロセスに応用できません。これが、Google が Document AI を導入した理由です。これにより、ユーザーは、機械学習(ML)モデルを通してドキュメントから構造化データを抽出し、ビジネス プロセスを自動化して、意志決定を改善できます。
過去 2 年にわたって、Google のお客様は、Document AI を使用して、調達、融資、身元保証、契約などの分野でドキュメントベースのワークフローを高速化および強化してきました。これらの機能は、Google Cloud Next ’22 での Document AI Workbench のリリースを通して大幅に拡張されました。このワークベンチは、事実上すべてのドキュメントベースのワークフローに ML をすばやく簡単に適用できるようにする新しい機能です。
Document AI Workbench を使用すれば、アナリスト、開発者、およびビジネス ユーザーは、独自のデータを取り込んで 1 つのボタンのクリックだけでモデルをトレーニングしてから、ビジネスに必要なドキュメントからフィールドを抽出できます。従来の開発アプローチと比較すると、Document AI Workbench では、組織はより少ないデータで迅速にモデルを構築できるため、ドキュメント内の非構造化データの処理と分析にかかる価値創出までの時間が短縮されます。
この Document AI Workbench は、ドキュメント処理に大きな変革をもたらす可能性を秘めています。効果的な Google 機械学習モデルを活用してさまざまなテキスト ドキュメントやテキスト フォームをアップトレーニングし、より望ましい精度を実現することで、クライアントの時間とリソースの利用効率を高められるようになったからです。
Deloitte Consulting LLP マネージング ディレクター Daan De Groodt 氏
このブログ投稿では、Document AI Workbench の機能と、この新しい機能を業務に活用しているお客様の事例をご紹介します。
Document AI Workbench を使用したカスタム モデリングのメリット
Google のお客様は、Document AI Workbench を活用することで、時間と資金の節約を実現しています。「Document AI Workbench は、ドキュメントの自動化を迅速かつ効率的に拡張するのに役立っています。Document AI Workbench のお陰で、わずかな時間と少ないリソースで独自のドキュメント パーサー モデルをトレーニングできました。これを活用して、重要な業務改善を実現したり、顧客向けのサービスを大幅に向上させたりすることができそうです」と、金融サービス会社 BBVA でグローバル ヘッド ビジネス プロセス & オペレーションを務める Daniel Ordaz Palacios 氏は述べています。
こうしたメリットが実現する仕組みを掘り下げてみましょう。
誰もが使えるようになった ML
データ サイエンティストの時間は足りていません。Document AI Workbench を使用すると、ML の経験が少ない開発者やアナリスト、あるいはその他のユーザーでも、シンプルなインターフェースでデータにラベルを付けてから 1 つのボタンをクリックするだけで、トレーニングを始め、ML モデルを作成できます。Document AI Workbench がトレーニング データを活用してバックグラウンドでモデルを作成することにより、ML モデルに貢献可能なユーザーの範囲が広がると同時に、データ サイエンティストの労力をきわめて高度なプロジェクトのために温存しておけるようになります。
さまざまなドキュメント タイプ
Document AI Workbench を使用すると、組織は、独自のデータを持ち込んでさまざまなドキュメント タイプや属性向けの ML モデルを作成できます。これには、印刷または手書き入力されたテキストや、テーブルなどのネストされたエンティティ、あるいはチェックボックスなどが含まれます。お客様は、専門業者がスキャンしたものから、手早く撮影した写真のものまで、幅広いドキュメント画像を処理し、PDF、一般的な画像形式、JSON document.proto などの複数の形式でデータをインポートできます。
製品化までの時間
Document AI Workbench を使用すると、カスタム ML モデルを構築する場合に比べて、お客様の製品化までの時間を大幅に短縮できます。データのトレーニングを提供しさえすれば、後は Document AI が処理してくれるからです。また、モデルの重み、パラメータ、アンカーなどを気にする必要もありません。
より少ないトレーニング データ
Document AI Workbench を使用すると、少ないトレーニング データで、正確な結果を得られる ML モデルを構築できます。このことは、特に、Document AI Workbench がより正確な結果を生成するために事前にトレーニングされたモデルから学習を転送する「アップトレーニング」時に当てはまります。Google は、請求書、注文書、契約書、W2、1099-R、および給与明細書のアップトレーニングをサポートしています。
将来的には、さらに多くのドキュメント タイプをサポートすることを計画しています。また、正確な出力に必要なトレーニング データの量を減らし続けることによって ML モデルのトレーニングをさらに簡素化していきたいと考えています。たとえば、Google の DeepMind チームは最近、公共料金請求書や注文書用のドキュメント解析 ML モデルを、Document AI で従来必要とされていたよりも 50~70% 少ないトレーニング データで作成できる新しい方法を開発しました。今後数か月以内に、この方法を Document AI Workbench に統合する予定です。1
無料のトレーニング
サーバーのスピンアップの料金を支払い、モデルのトレーニングが終わるまで待たなくても、Document AI Workbench を使用すれば、ユーザーは無料で ML モデルを作成して評価できます。お客様は、モデルのデプロイ後に使った分だけ支払えば済みます。
Document AI Workbench があれば、組織は、こうした機能をはじめとするさまざまな機能を使用できます。しかも、独自のデータを使用してモデルをトレーニングできるのです。
このようなメリットのお陰で、多くのお客様がすでに目覚ましい成果を上げています。テクノロジー企業の Searce でデータ サイエンス担当副社長を務める Muthukumaraswamy B 氏は次のように述べています。「Document AI Workbench を使用すれば、カスタムモデルの構築に比べて、製品化までの時間が最大 80% 程度削減されると見積もっています。」
同様に、ソフトウェア会社の Libeo で CPO & CTO を務める Pierre-Antoine Glandier 氏は次のように述べています。「1,600 件のドキュメントで請求書プロセッサをアップトレーニングし、Document AI Workbench 上のアップトレーニングでテストの精度が 75.6%(事前にトレーニングされたモデルを使用)から 83.9% に上がりました。アップトレーニングのお陰で、Document AI の結果は競合他社の結果を上回り、長期的に見れば Libeo の全体コストが最大約 20% 削減されると見ています。」
テクノロジー企業の Zencore も大きな進歩を遂げつつあります。「Document AI Workbench を使用すれば、非常に正確なドキュメント解析モデルを数日で開発できます。当社の顧客は、以前は人手が相当必要だったタスクを完全に自動化できました」とデリバリー サービス担当副社長の Sean Earley 氏は述べています。
Document AI Workbench の使用方法
ユーザーは、Google Cloud コンソールのシンプルなインターフェースを使用して、トレーニング データの準備、モデルの作成と評価、モデルの本番環境へのデプロイを行えます。デプロイ後は、モデルを呼び出すだけでドキュメントからデータを抽出できます。
トレーニング データのインポートと準備
最初にユーザーが行うことは、ML モデルをトレーニングするためのドキュメントをインポートしてラベルを付けることです。他のツールを使用してドキュメントにラベルが付けられている場合は、JSON 形式の doc.proto でラベルをインポートします。ドキュメントにラベルを付ける必要がある場合は、ドキュメント スキーマを作成してから、Google のシンプルなインターフェースを使用してドキュメントにラベルを付けることができます。ラベル付けが完了すると、光学文字認識(OCR)が自動的にコンテンツを検出してトレーニング データを準備します。
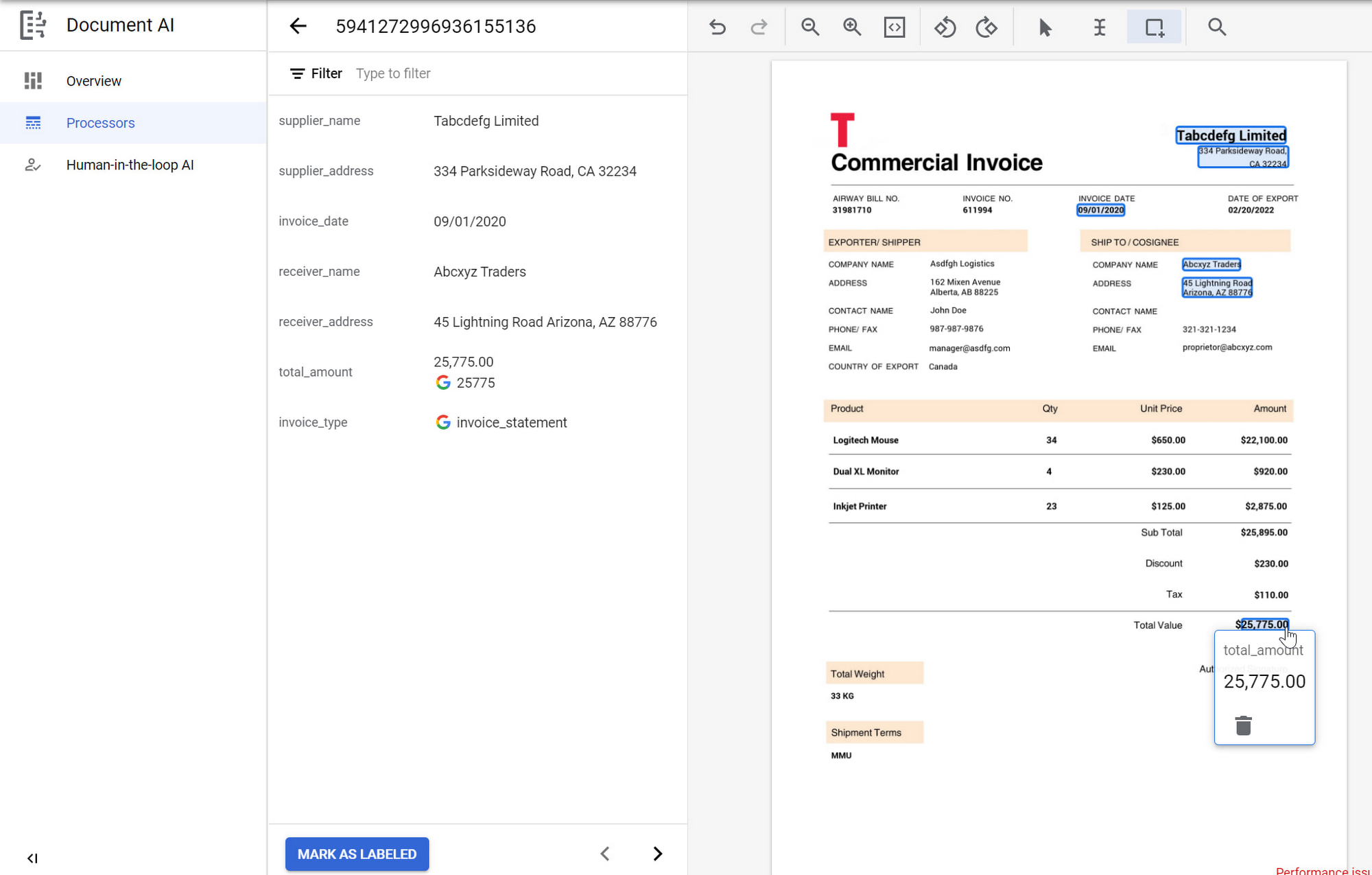
モデルのトレーニング
モデルはワンクリックでトレーニングできます。既存のドキュメント モデルとレイアウトやスキーマが類似しているドキュメント タイプを処理する場合は、関連するモデルをアップトレーニングすることによって、正確な結果をより速く入手できます。関連するアップトレーニング可能なモデルがドキュメントに使用できない場合は、Document AI Workbench の Customer Document Extractor を使用してモデルを作成できます。
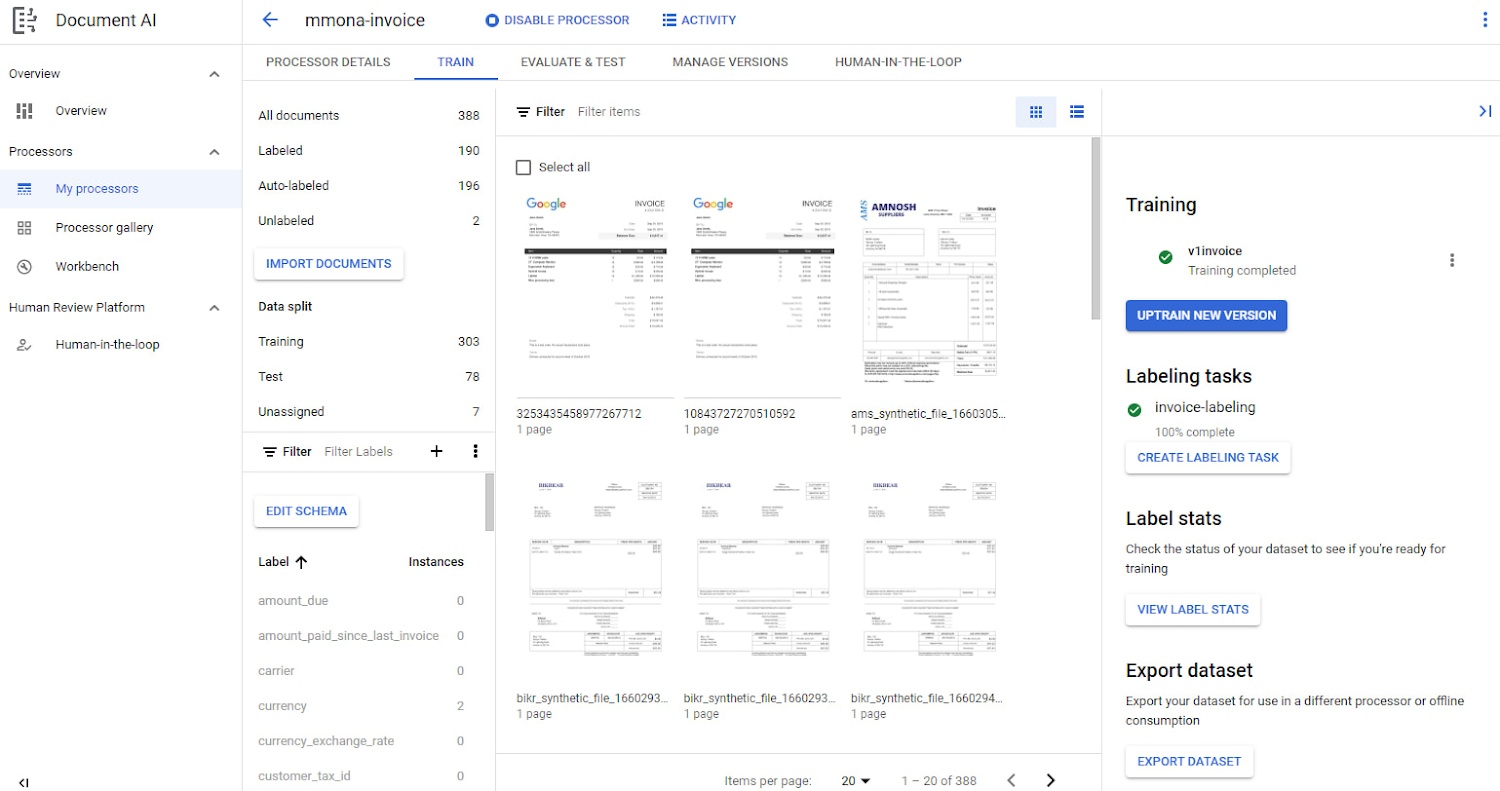
モデルの評価と反復処理
モデルをトレーニングしたら、次は、パフォーマンス指標(F1 スコア、適合率、再現率など)を調査することによってモデルを評価します。ユーザーは、モデルがエラーを予測した特定のインスタンスを掘り下げて、将来のパフォーマンスを向上させるための新たなトレーニング データを提供できます。
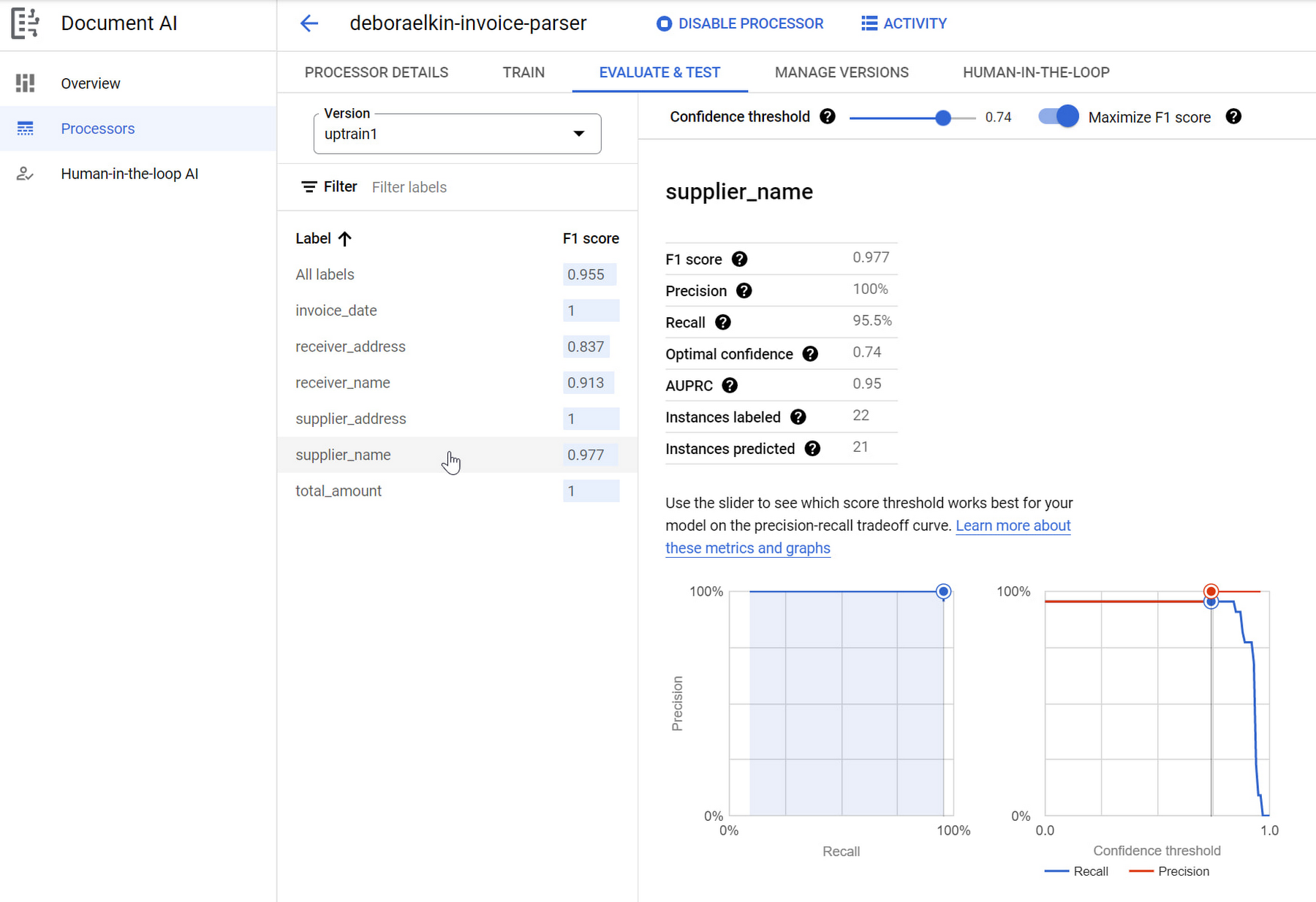
本番環境への移行
モデルが精度目標を満たしたら、次は本番環境にデプロイします。デプロイ後は、モデルのエンドポイントを呼び出してドキュメントから構造化データを抽出することができます。最後に、ユーザーは、信頼レベルが必要なしきい値を下回っている予測を修正できる、人間参加型のレビュー ワークフローを構成できます。人間によるレビューを通して、組織は、出力を本番環境で使用する前に修正または確認できます。その後、修正済みのデータを使用してモデルをトレーニングし、将来の予測の精度を上げることができます。
「Google の Document AI Workbench は、柔軟で使いやすいインターフェースと、当社のクライアントが求めているエンドツーエンドの機能を提供してくれます。カスタム ドキュメント抽出器とカスタム ドキュメント分類器のお陰で、プロトタイピングが数か月から数週間に短縮されただけでなく、クライアントに現行のテクノロジー以上のコスト削減を提案できています」とデータと分析の最新化企業 Pandera で CTO を務める Erik Willsey 氏は述べています。
Document AI Workbench を使ってみる

すでに、非常に多くのお客様やパートナーが Document AI Workbench を使用して価値向上を実現されています。詳しくは、Document AI Workbench ランディング ページまたは Document AI に関するこちらの Next’22 セッションをご視聴ください。または、主要パートナーにお問い合わせいただければ、導入のためのサポートをすぐに開始させていただきます。
1. DeepMind は、公共料金請求書やさまざまなベンダーからの注文書などの Google 内部の何千ものドキュメントを使用して、この方法を開発し、評価しました。パフォーマンスは評価データセットによって異なります。



