Google が世界最速のトレーニング スーパーコンピュータで MLPerf の AI パフォーマンスの記録を塗り替える

Google Cloud Japan Team
※この投稿は米国時間 2020 年 7 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
機械学習(ML)モデルの高速トレーニングは、これまでは実現できなかった新しい製品、サービス、研究の飛躍的な進歩を成し遂げようとしている研究チームやエンジニアリング チームにとって非常に重要です。ここ Google で、最新の ML によって実現された進歩には、利便性が向上した検索結果と 100 種類の言語を翻訳可能な単一の ML モデルがあります。
業界標準の MLPerf ベンチマーク コンテストの最新結果によると、Google が世界最速の ML トレーニング スーパーコンピュータを構築したことが示されています。このスーパーコンピュータと最新の Tensor Processing Unit(TPU)チップを使用して、Google は、8 つの MLPerf ベンチマークのうちの 6 つでパフォーマンス記録を塗り替えました。
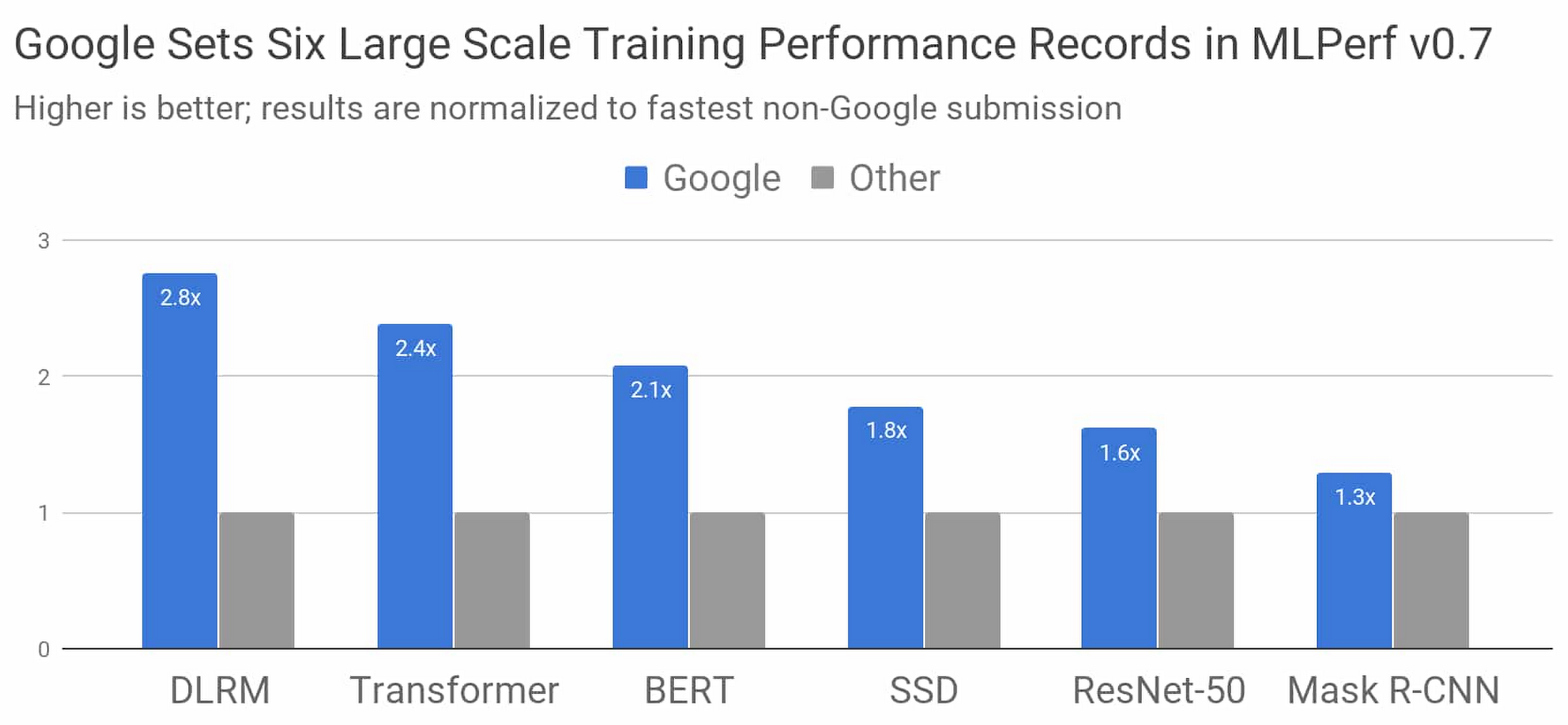
図 1: トレーニングのパフォーマンスを調べる MLPerf v0.7 のすべてのカテゴリで、Google の最速の提出値が、Google 以外の最速の提出値を上回りました。比較に使用される値は、システムのサイズに関係なく(8~4096 チップの範囲)、合計トレーニング時間で正規化されています。棒グラフが高いほど、パフォーマンスが優れていることを示します。1
Google は、TensorFlow、JAX、Lingvo での ML モデル実装でこれらの結果を成し遂げました。8 つのモデルのうちの 4 つは、何もないところから 30 秒以内にトレーニングが完了しました。これを大局的な観点から見るために、2015 年には、当時の最先端のハードウェア アクセラレーションでこれらのモデルをトレーニングした場合、3 週間以上かかっていたことを考えてみてください。Google の最新の TPU スーパーコンピュータでは、同じモデルをわずか 5 年前と比べて、約 10 万倍の速さでトレーニングできます。
このブログ投稿では、コンテストの詳細、Google の提出値がいかにこのような高いパフォーマンスを達成したか、このことがお客様のモデルのトレーニング速度にどのような意味をもたらすかについて説明します。
MLPerf モデルの概要
MLPerf モデルは、産業界と大学、研究施設で共通して使用される、最先端の機械学習ワークロードを表すモデルとして選ばれました。ここでは、上の図の各 MLPerf モデルの詳細について説明します。
- DLRM は、メディアから、旅行、e コマースに至るまでのオンライン ビジネスの中核をなすランキングと推奨モデルを表します
- Transformer は、BERT などの自然言語処理における最近の進歩の基盤となります
- BERT は Google 検索の「過去 5 年で最大の躍進」を可能にしました
- ResNet-50 は、広く使用されている画像分類用のモデルです
- SSD は、モバイル デバイス上で実行できる軽量なオブジェクト検出モデルです
- Mask R-CNN は、広く使用されている画像セグメンテーション モデルで、自律航法や医用画像処理などの領域(Colab で実験可能)に使用できます
前述の最大規模で業界をリードする結果に加えて、Google は、すでに企業で使用できる準備が整っている Google Cloud Platform 上の TensorFlow を使用した値も MLPerf に提出しました。この提出値の詳細については、こちらのブログ投稿で確認できます。
世界最速の ML トレーニング スーパーコンピュータ

Google がこの MLPerf に提出するトレーニング値の測定に使用したスーパーコンピュータは、前回のコンテストで3 つの記録を打ち立てた Cloud TPU v3 Pod の 4 倍の規模を誇ります。このシステムは、4096 個の TPU v3 チップと数百台の CPU ホストマシンで構成され、そのすべてが超高速で超大規模なカスタム相互接続を介して接続されています。このシステムは、合計で 430 PFLOPs を超えるピーク パフォーマンスを実現します。
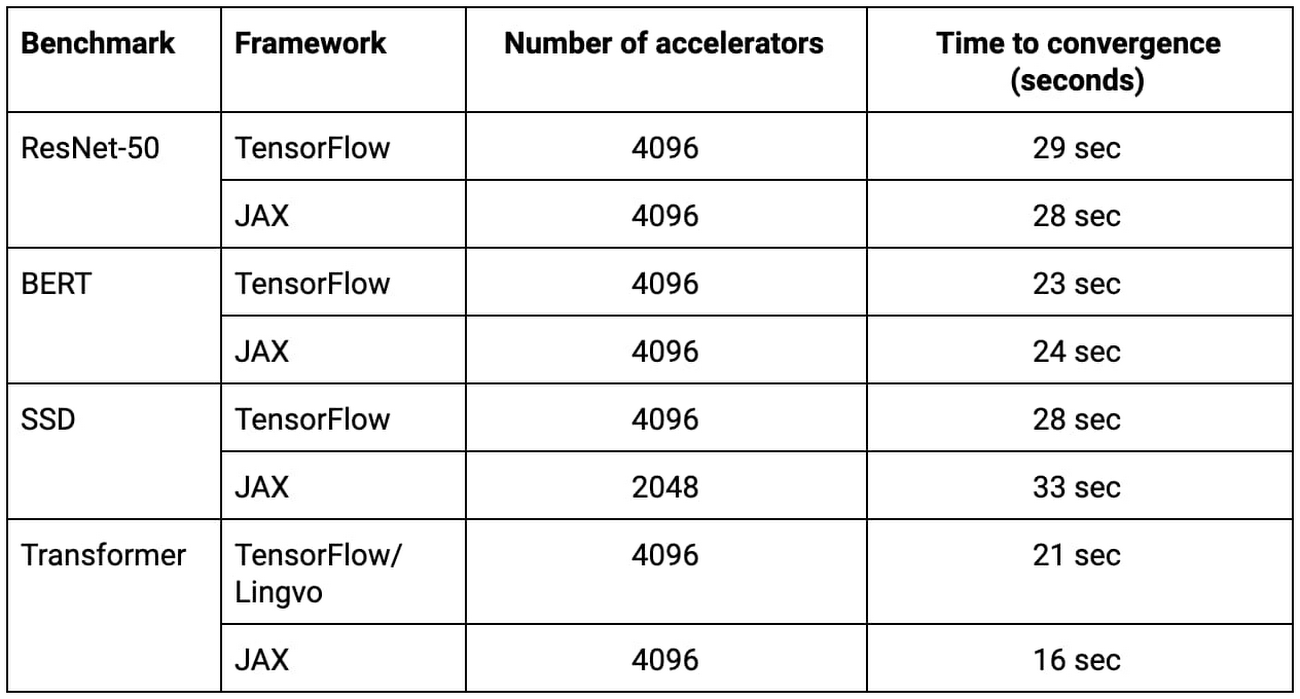
表 1: このすべての MLPerf 提出値が Google の新しい ML スーパーコンピュータで何もないところから 33 秒以内にトレーニングを完了しました。2
TensorFlow、JAX、Lingvo、XLA を使用した大規模トレーニング
何千個もの TPU チップを使用する複雑な ML モデルのトレーニングには、TensorFlow、JAX、Lingvo、XLA におけるアルゴリズムの技術と最適化の組み合わせが必要でした。これらについて説明すると、XLA は Google のすべての MLPerf 提出を支援する基盤となるコンパイラ技術であり、TensorFlow は Google のエンドツーエンドのオープンソース機械学習フレームワークであり、Lingvo は TensorFlow を使用して構築されたシーケンス モデル用の高度なフレームワークであり、JAX はコンポーズ可能な関数変換に基づく新しい研究中心のフレームワークです。前述した記録的な規模は、モデルの同時実行、大規模な一括での正規化、効率的な計算グラフの起動、ツリーベースの重みの初期化によって実現しました。
上の表内の TensorFlow、JAX、Lingvo の提出値のすべて(ResNet-50、BERT、SSD、Transformer の実装)が 2048 個または 4096 個の TPU チップでそれぞれ 33 秒以内でトレーニングされました。
TPU v4: Google の第 4 世代 Tensor Processing Unit チップ
Google の第 4 世代 TPU ASIC は、TPU v3 の 2 倍以上の行列乗算 TFLOPs、メモリ帯域幅の大幅な増加、相互接続技術の進歩を提供します。Google の TPU v4 MLPerf の提出値は、これらの新しいハードウェア機能と、補足コンパイラおよびモデリングの進歩を利用しています。この結果は、前回の MLPerf トレーニング コンテストにおける同様の規模での TPU v3 のパフォーマンスの平均で 2.7 倍の向上を示しています。TPU v4 の詳細は、次のセクションで説明します。
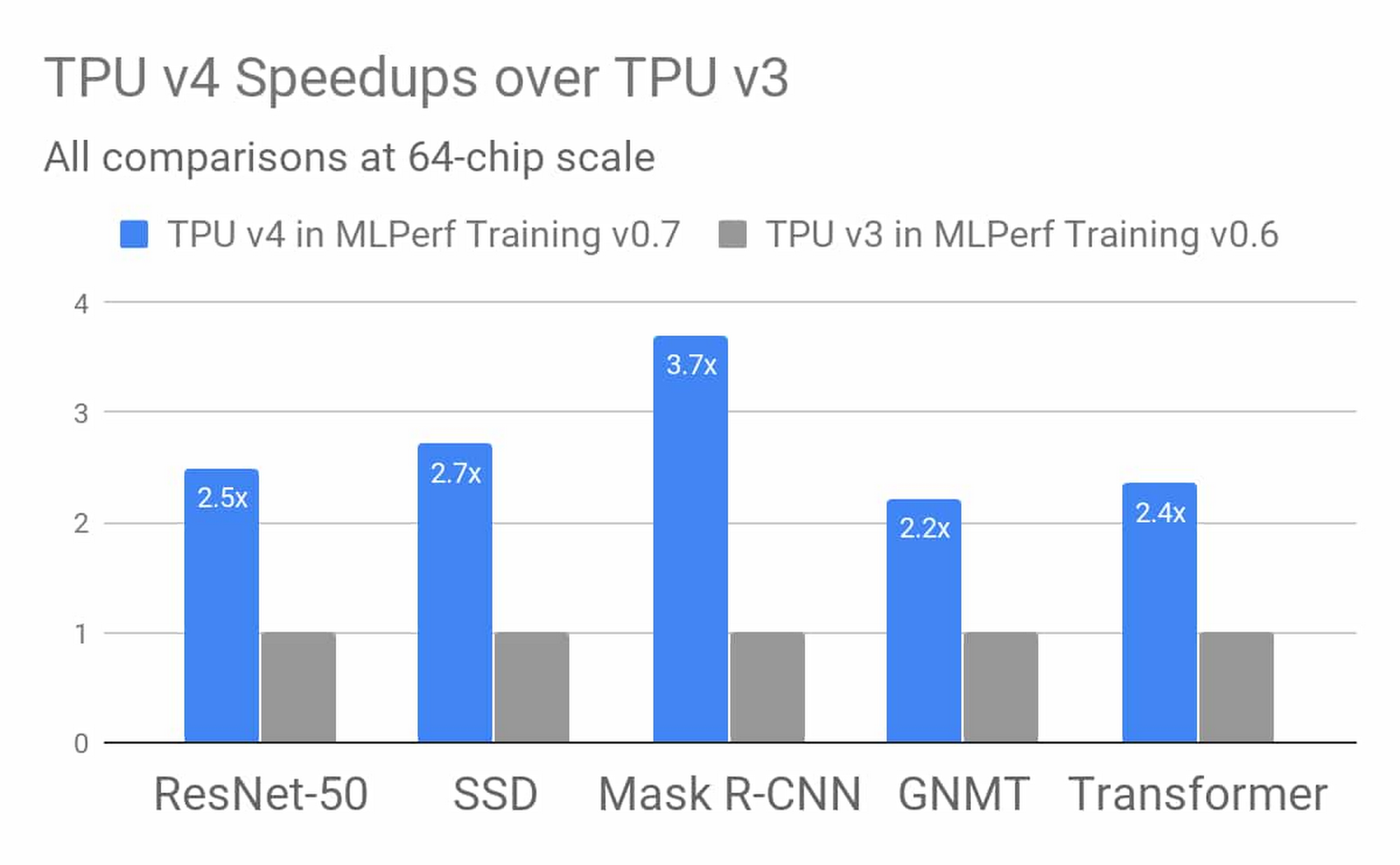
図 2: Google の MLPerf v0.7 のトレーニング パフォーマンスに関する提出値における TPU v4 の結果は、64 個のチップからなる同一規模での Google の MLPerf v0.6 のトレーニングに関する提出値の TPU v3 の結果と比べて、平均で 2.7 倍の向上を示しました。この向上は、TPU v4 のハードウェアの革新とソフトウェアの向上によるものです。3
迅速で継続的な進化
Google の MLPerf v0.7 のトレーニングに関する提出値は、機械学習の研究とエンジニアリングを規模を拡大して進歩させ、その進歩をオープンソース ソフトウェア、Google のサービス、Google Cloud を通してユーザーに提供するという Google の取り組みを表しています。
Google の第 2 世代と第 3 世代の TPU スーパーコンピュータはすぐに Google Cloud でご利用いただけます。詳しくは、Cloud TPU のホームページとドキュメントをご覧ください。Cloud TPU は TensorFlow と PyTorch をサポートしており、JAX Cloud TPU プレビューもご利用いただけます。
1. すべての結果は、2020 年 7 月 29 日に www.mlperf.org から取得されたものです。MLPerf の名前とロゴは商標です。詳しくは、www.mlperf.org をご覧ください。グラフの比較結果: 0.7-70 対 0.7-17、0.7-66 対 0.7-31、0.7-68 対 0.7-39、0.7-68 対 0.7-34、0.7-66 対 0.7-38、0.7-67 対 0.7-29。
2. すべての結果は、2020 年 7 月 29 日に www.mlperf.org から取得されたものです。MLPerf の名前とロゴは商標です。詳しくは、www.mlperf.org をご覧ください。表内の結果: 0.7-68、0.7-66、0.7-68、0.7-66、0.7-68、0.7-65、0.7-68、0.7-66。
3. すべての結果は、2020 年 7 月 29 日に www.mlperf.org から取得されたものです。MLPerf の名前とロゴは商標です。詳しくは、www.mlperf.org をご覧ください。図の比較結果: 0.7-70 対 0.6-2。
-Google AI 担当 Naveen Kumar


