Glance が Google と協力してワンランク上のゲーム レコメンデーション エンジンを構築
Google Cloud Japan Team
※この投稿は米国時間 2023 年 5 月 16 日に、Google Cloud blog に投稿されたものの抄訳です。
モバイルゲームは近年人気が沸騰しており、世界中の数十億の人々がスマートフォンやタブレットでゲームを楽しんでいます。InMobi の子会社の Glance は、ロック画面をベースとしたコンテンツ発見プラットフォームとして世界最大級の規模を誇り、アクティブ ユーザー数は 2 億 2,000 万人を超えます。今や、Glance がもたらす次世代のインターネット体験は、4 億台を超えるスマートフォンでロック画面の使い方を変革しようとしています。Glance は、パーソナライズされたおすすめゲームをユーザーに提案することで、自社のゲームセンター アプリの導入数を伸ばそうと狙っています。現在数百種類のゲームが収録されているこのゲームセンター アプリは、1 か月のアクティブ ユーザー数が 7,500 万人以上で、ユーザーベースが急速に成長しています。
Glance は当初、全体的なユーザー エクスペリエンスを向上させるため、ユーザーのホーム画面に表示されるゲームを個々のユーザーの好みに合ったおすすめのゲームにすることを喫緊の課題としていました。Glance は Google Cloud に着目し、ユーザーの好みに従ってゲーム コンテンツをパーソナライズするレコメンデーション システムを構築することに決めました。
この投稿では、Glance のゲーム レコメンデーション システムがどのようなもので、このソリューションを構築するために Google のさまざまな AI テクノロジーがどのように実装されたかを詳しく見ていきます。
履歴に基づくデータセット
プライバシー ガイドラインに従ってユーザーが任意で Glance に提供した Glance アプリ内の過去のインタラクションから、以下のデータセットを作成しました。
ユーザー メタデータ: ユーザーに関する情報。ユニーク ユーザー ID、ハンドセットの詳細、メーカーの詳細など。
ゲーム メタデータ: ゲームに関する情報。ゲームの名前、バージョン、説明、ユニークゲーム ID など。このデータセットには、ゲームがリリースされている地域、ゲームのカテゴリとサブカテゴリなどの二次情報も含まれます。
ユーザーとゲームのインタラクション データ: ユニーク ユーザー ID、ユニークゲーム ID、インタラクションの開始時間と継続時間、ゲーム バージョンを捕捉するデータ。
これらの一次データソースは分析と実験にも使用し、最終的にはモデリングにも使用しました。各データセットを時間によってパーティション分割し、実験の精神で 30 日分のデータからソリューションを導き出すこととしました。
データの傾向の特定
セッション継続時間とイベントの回数を対応付けたグラフを観測した結果、2 秒未満のユーザー インタラクション イベントは除外することに決めました。そのようなイベントは意図的でなく偶発的に起こったものである可能性が高かったからです。
もうひとつの興味深い傾向は、セッションの大半が夜に発生していて、その次に多かったのが深夜以降の時間帯だったことでした。
また、予想したとおり、他のゲームよりもセッション インタラクション継続時間の中央値がかなり高いゲームがいくつかありました。
外れ値の取り扱い
作成したインタラクション データセットで観測されたセッション継続時間の値は、全体的に一様ではありませんでした。そのため、セッション継続時間の分布の両端に外れ値がありました。
前述したように、検討対象とするセッション継続時間は最低 2 秒とし、それより短いセッションは破棄しました。さらに、数理解析により、ある特定の最大セッション継続時間を単一のセッション インタラクションの代表値としました。つまり、これより高い値はすべて誤りとみなしました。
データの分割
使用するデータは 30 日分と決めましたが、レコメンデーション システムに公平かつ正確にアクセスするため、データの分割方法を決定する必要がありました。
次のようないくつかのアプローチを検討しました。
80/10/10 の比率でランダムに分割する。この方法を採用すると、モデルが未来から傾向を先走って学習し、最終的にデータ漏洩を引き起こす可能性があります。
ユニークゲーム / ユーザーに基づいて層化分割する。これは、協調フィルタリング アプローチのコールド スタート問題につながります。
「最後のワンアウト」戦略に基づいて分割する。つまり、ユーザーがやり取りした(N-1)個のゲームのみを対象とし、最後のゲームはテスト データセット用に確保します。これは時間次元全体にわたるデータ漏洩を引き起こします。
N 週間でデータを層化分割する。実際、私たちは週単位の傾向をいくつか探りました。そのため、最初の N 週間分のデータをトレーニング データセットとし、その後のデータをテストと検証に使用できます。この分割タイプは「グローバル時間分割」とも呼ばれます。
ゲームの数の方がユーザーの数より少なかったため、すべてのゲームがすべてのデータセットに存在すると考えました。つまり、N 個のすべてのゲームについて、トレーニング / テスト / 検証の各データセットに少なくとも 1 回のユーザー インタラクションがある(つまり、少なくとも計 3 回のユーザー インタラクションがある)とみなしました。
最終的に選択したのは、4 番目のグローバル時間分割アプローチでした。そこで、まずデータを時系列順に並べ、分割間隔を定義して、トレーニング、テスト、評価の分割データセットを作成しました。このようにして時間的データ漏洩を回避し、全ユーザーにわたる傾向が適切に捕捉されるようにしました。
データの前処理
次の論理的ステップは、値をスケールすることでした。ただし、分布の非正規性からどのような形の正規化も行えなかったため、継続時間総計の中央値センタリングをとるアプローチを採用しました。
継続時間総計は、ユニーク ユーザーとユニークゲームのペアのすべてのセッションにわたる総インタラクション時間を、トレーニング、テスト、評価の分割データセットごとに合計することによって算出しました。
このアプローチでは、トレーニング分布の継続時間の中央値合計を選択し、値をスケールダウンする式でその合計を使用しました。値をスケールすることで、トレーニングするモデルを迅速に収束させることができます。また、中央値より小さい値はすべて負数として変換され、中央値より大きい値はすべて正数として変換されます。
実験およびモデリング アプローチ
このユースケースに最適なソリューションを見つけるため、深く幅広い実験を行いました。実験には、行列分解、Vertex AI による Two-Tower モデリング、TFRS の実装、強化学習などの手法を用いました。
BQML による行列分解 - 行列分解は、レコメンデーション システムで使用される協調フィルタリング アルゴリズムの一種です。行列分解アルゴリズムは、ユーザーとアイテムの相互作用行列を 2 つの低次元の矩形行列の積に分解することによって機能します。BQML には行列分解機能が最初から組み込まれています。このモデルで必要なことは、モデルを作成してトレーニングを開始する SQL スクリプトを記述することだけです。ユーザーとアイテムの相互作用行列を分解する WALS アルゴリズムは、BQML に実装されています。
これをベースライン モデルとして作成し、ユーザーとゲームの相互作用(インタラクション)ごとのセッション継続時間総計を特徴量としてトレーニングを行いました。
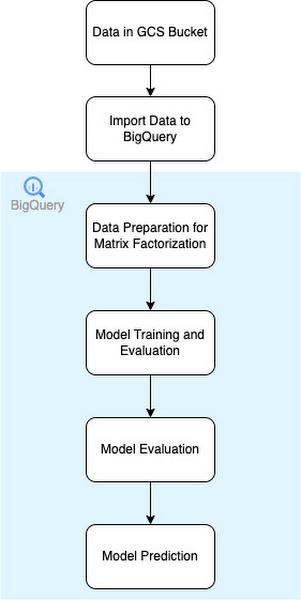
このモデルはかなりうまく機能し、ハイパーパラメータの調整後、テスト データセットと評価データセットについて最高のスコアを記録しました。BigQuery パイプラインにおけるデータの流れを次の図に示します。
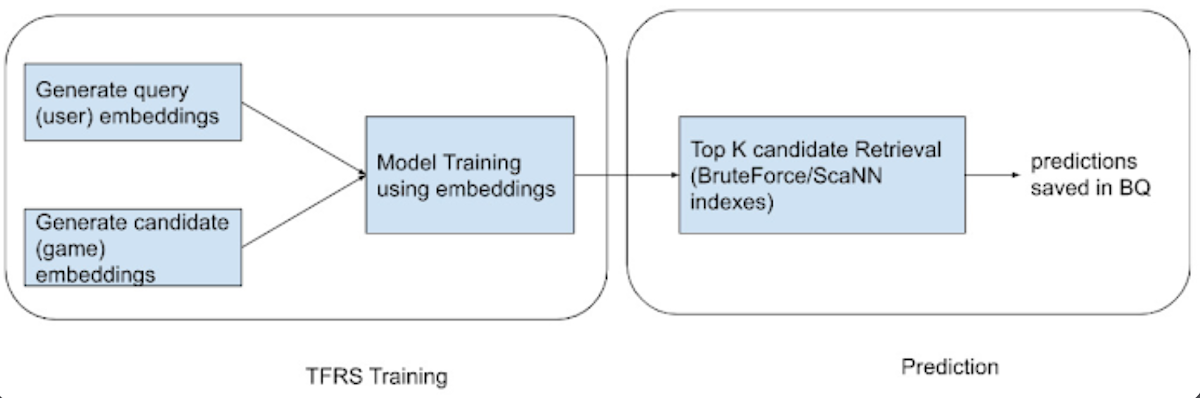
- Vertex AI Matching Engine を使用した Two-Tower エンベディング アルゴリズム - これは、エンベディングに基づいてレコメンデーション システムを構築するアプローチです。Two-Tower アプローチは、クエリタワーと候補タワーを使用してそれぞれのタワーに渡すクエリとその関連する候補のエンベディングを生成するランキング モデルです。生成されたエンベディングはベクトル エンベディング空間で表現されます。
エンベディング ベースのモデルは、ユーザーとアイテム コンテキストを使用して、豊富な情報を持つエンベディングを共通のベクトル空間に作成します。今回の実験的アプローチでは、ユーザー特徴量とゲーム特徴量をさまざまに組み合わせてエンベディングを構築しました。最も良い結果が得られたのは、ゲーム エンベディングにカテゴリが含まれ、ユーザー エンベディングに曜日や時間帯のような時間特徴量が含まれていた場合でした。
これらのエンベディングを作成した後、Vertex AI Matching Engine のインデックスを作成しました。Vertex AI Matching Engine は、業界をリードする大規模で低レイテンシのベクトル データベース(ベクトル類似度マッチングまたは近似最近傍探索サービスとも呼ばれます)を提供します。たとえば、クエリアイテムを与えると、Matching Engine は大規模な候補アイテムのコーパスから意味的に最も似ているアイテムを探します。
今回はこれを利用して、ブルートフォース検索用のインデックスと近似最近傍探索用のインデックスを作成しました。次に、ドット積やコサイン類似度などのさまざまな距離指標を使用して一連の実験を行いました。その結果、エンベディング モデルをうまく機能させるには追加のモデリングと追加のコンテキスト データが必要という結論に達しました。
TFRS によるカスタム モデリング - TensorFlow Recommenders(TFRS)は、レコメンダー システムのモデルを構築するためのライブラリです。TensorFlow を基盤としており、レコメンダー システムの構築、トレーニング、デプロイのプロセスを効率化します。
このアプローチのために構築した TFRS リトリーブ モデルは、クエリモデル(UserModel)と候補モデル(GameModel)の 2 つのサブモデルで構成されていました。前者はクエリ特徴量を使用してクエリ表現を計算し、後者は候補特徴量を使用して候補表現を計算します。これら 2 つのモデルの出力を使用して、クエリと候補のアフィニティ スコアを算出しました。スコアが高いほど、候補とクエリの一致度が高いことを示します。Vertex AI による Two-Tower アプローチと同様に、さまざまなユーザー特徴量とゲーム特徴量を定義してエンベディングを作成する実験を繰り返し、Vertex AI Matching Engine のインデックスを作成しました。
最良の結果と一般化が認められたのは、ユーザー特徴量のみを考慮し、ゲーム特徴量は考慮しなかった場合でした。ゲームについてはユニークゲーム ID のみを使用し、この ID をある特定のゲームをベクトル空間に埋め込むための参照としました。分析には、上位 K 個のおすすめゲームを提示するブルート フォースのインデックスを使用しました。ブルート フォースを使用したのは、探索空間が限られていたためです。
コンテキスト バンディットによる強化学習 - TF-Agents によって実装した多腕コンテキスト バンディット アルゴリズムを実装しました。多腕バンディット(MAB)は、エージェントが長期的に見て累積的報酬が最大になるアクション(アーム)を選ぶことを要求される ML フレームワークです。各ラウンドで、エージェントは現在の状態に関する情報(コンテキスト)を受け取り、この情報とそれまでのラウンドで得た経験を基にアクションを選択します。各ラウンドの最後に、選択したアクションに対応する報酬がエージェントに与えられます。
このアプローチでは、アームあたりの特徴量を含む多腕コンテキスト バンディット(MACB)モデリングを利用しました。つまり、学習エージェントは、それぞれ固有の特徴量を持つ「アーム」のひとつからゲームを選択できます。これにより、ユーザーとゲーム コンテキストがニューラル ネットワークを通じて埋め込まれるため、一般化に役立ちます。
この方法では、コンテキストは BQML 行列分解モデルから取得しました。エージェントのアルゴリズムには、探索係数を事前に指定した Epsilon Greedy アルゴリズムを採用し、モデルが他のアームを探索しながら確実に傾向を学習できるようにしました。
このモデルは、100 万のユニーク ユーザーのサブセットでしかトレーニングされなかったことを考えると、驚くほど良好な結果をもたらしました。限られたトレーニング サンプルから卓越した一般化可能性を獲得し、計 1,900 万のユニーク ユーザーのコンテキスト空間を理解してマッピングすることができました。
このモデルは今回のプロジェクトにおいて比較的優秀な成績を上げたもののひとつで、準最適アーム指標やリグレット指標のようなモデル指標を最適化することを狙いとしていました。MACB の実験では、次のアプローチに従いました。

実験の指標
上記のすべての実験において、以下の 4 つの指標を計算しました。
K での平均適合率の平均(MAP)
K での正規化減価累積利得(NDCG)
平均ランク
平均二乗誤差
上記の「K」は、おすすめとして提案される結果の数を表します。実験の際、K の値は 5、10、およびすべてとしました。
これらの指標に基づき、異なるモデリング手法の間でモデルをランク付けしました。ただし、これら 4 つの指標の中で特に注目したのは、MAP と NDCG の値を比較することでした。その理由は、これらの指標が目下の課題をより的確に表しているためです。
結果と観察
最良のモデルでは、以前に使用していたベースライン モデルよりも成績が大幅に向上しました。最も成績が良かったモデルは BQML 行列分解モデルで、2 位はコンテキスト バンディット モデル、3 位は Vertex AI Two-Tower、最後は TFRS アプローチでした。エンベディング ベースのモデルの成績が芳しくなかったのは、与えられたデータセットに、特定のユーザー属性の特徴量が含まれていなかったためです。また、K の値を増やすとモデルの成績も向上しましたが、これは予想された挙動でした。
これらのモデルの運用化とスケーリングのアプローチを検討した Glance のチームは、まず新しいモデルをごく一部のトラフィックに対してデプロイし、A/B テストの要領でエンゲージメント指標を対照トラフィックと比較しました。このデプロイメントは、出力のレイテンシを低く抑え、ユーザー エンゲージメントの背後にある主な要因をより深く理解するために、調整が加えられました。モデルが良好な成績を示した後、Glance は、必要に応じてモデルをデプロイするトラフィックの割合を広げるため、さらなる費用最適化が図れるような体制を整えました。
このプロジェクトの後、Glance のチームは BQML 行列分解モデルを本番環境に実装することを決定し、その結果、暫定的ながら、ユーザーが Glance のプラットフォーム上にあるゲームとのやり取りに費やす時間は増加しました。
Google Cloud AI サービス(AIS)によるエンドツーエンドの迅速な導入
Google Cloud と Glance のパートナーシップは、お客様が望ましい成果を上げられるよう支援するために、Google が複雑な問題を解決する AI 搭載ソリューションをどのように提供しているかを示す最新の例のひとつです。Google Cloud の AI サービスについて詳しくは、AI と ML のプロダクト ページをご覧ください。
Glance のゲーム部門でデータ サイエンスのコンサルタントを務める Paul Duff 氏は、ほんの数週間で本番稼働可能なモデルを作り上げた Cloud AIS と BQML のようなすぐに使えるプロダクトにいかに満足しているかを強調し、次のように述べています。「Google のチームは、Glance のゲームセンター アプリのオフラインのレコメンデーション システムを開発するという合意された目標をはるかに超え、すべてのマイルストーンを納期どおりに、あるいは納期より前に達成し、4 種類の詳細に文書化されたワーキング モデルを提供してくれました。私たちは(合意されたプロジェクト範囲を超えて)その中で最も優秀なモデルを本番環境に導入し、プロジェクト終了日の前に主要な指標が上昇したことを確認できました。チームの体制は、プロジェクト全体を通して優れたコミュニケーションの模範となるものでした。」
プロジェクト全体にわたって支援・指導していただいた Naveen Poosarla 氏と Charu Shelar 氏に深く感謝いたします。このプロジェクトを成功に導くために共に尽力してくれた Glance のチーム(Gaurav Konar 氏、Rohit Anand 氏、Rohit Kalyan 氏)と Wipro および Capgemini のパートナー チーム(Tulluru Durga Pravallika 氏、Viral Gorecha 氏)の皆様に感謝します。そして、我らが偉大なるリーダー Nitin Aggarwal に大きな感謝を捧げます。
免責条項: このブログで発信する情報は、プロダクト使用状況指標に関連するデータの特定のサブセットに関する有益な情報を提供することを目的としています。ここで提示した結果は必ずしも全体的なプロダクト使用状況指標を反映しているとは限りませんのでご注意ください。
- Google Cloud、AI エンジニア Gopala Dhar


