各応用方法に適した機械学習アプローチを選択する
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 2 日に、Google Cloud blog に投稿されたものの抄訳です。
多くのお客様が、機械学習(ML)で問題を解決するテクノロジー スタックの選択方法を知りたいと望んでいます。利用可能なソリューションは数多くあります。ご自身で構築できるものもあれば、購入できるものもあります。今回は構築にポイントを置き、各種オプション、解決可能な問題、おすすめについて解説します。
多くのデータでトレーニングするほど優れた ML 応用が実現する
まずは重要なコンセプトの確認から始めましょう。つまり、ML モデルの品質は、データのサイズによって改善されるということです。下のグラフが示すように、目覚ましい ML のパフォーマンスと精度は、データサイズの向上によってもたらされます。これはテキストモデルですが、同じ原則が、あらゆる種類の ML モデルに当てはまります。
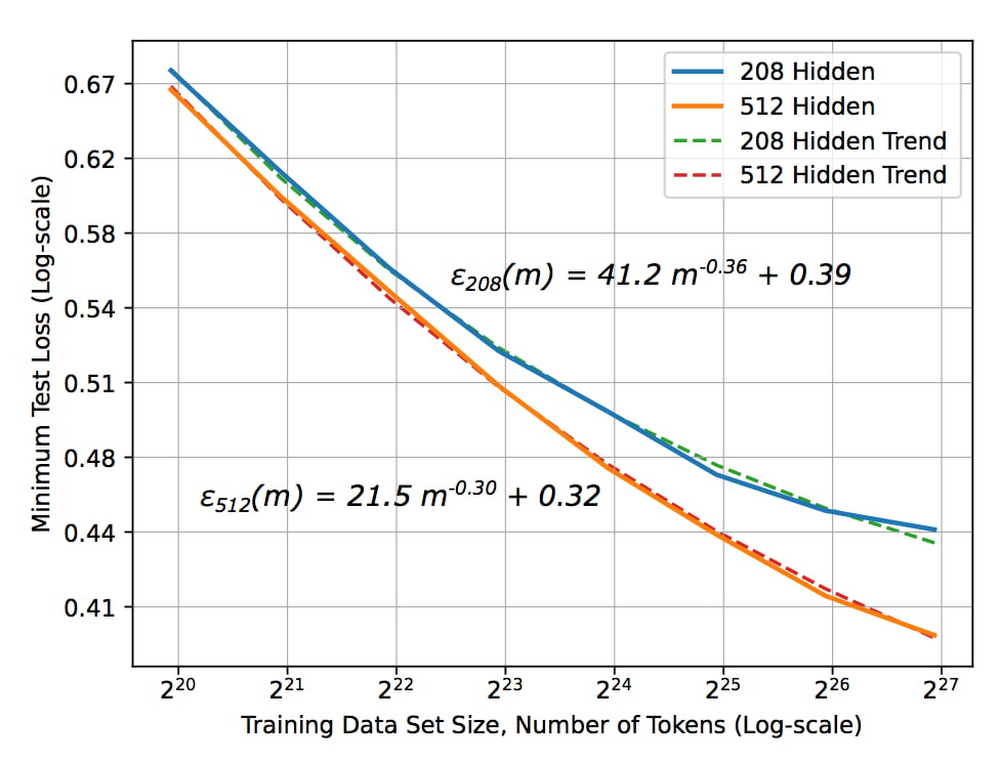
X 軸はデータのサイズを表し、Y 軸はエラー率を表します。データのサイズが大きくなるとエラー率は減少します。ただし、データのサイズについて注目すべき重要なことがあります。x 軸が 2^20、2^21、2^22 などとなっているのです。言い換えると、ここでは新たな目盛りごとにデータサイズが倍になっています。エラー率を直線的に減少させるには、データのサイズを指数関数的に増やす必要があります。
グラフ中の青い曲線は、オレンジ色の曲線よりやや高度な ML モデルを示しています。では、より優れたモデルを作成するかデータサイズを倍にするかの二者択一について考えてみましょう。どちらの選択肢もコストは同じと仮定すると、より多くのデータを収集し続けるほうが得策です。より優れたモデルの構築は、データサイズ増加による改善が横ばいになり始めたときに初めて必要になります。
第 2 に、ML システムでは、新しい状況が生じた場合に再トレーニングが必要になります。たとえば、YouTube にレコメンデーション システムがあり、おすすめを Google Now で提供しようとする場合、同じレコメンデーション モデルは使えません。Google Now で行うおすすめについて、第 2 のインスタンスでトレーニングを行う必要があります。そのため、たとえモデル、コード、原則が同じであっても、新たな状況向けには新たなデータでモデルを再トレーニングする必要があります。
これら 2 つのコンセプトを組み合わせると、データが多いほど ML モデルは改善され、新しい状況が生じた場合には一般的に ML モデルの再トレーニングが必要ということになります。時間をかけて ML モデルを構築するか、それともベンダーの市販モデルを購入するのか、いずれかを選択します。
構築すべきか購入すべきかという疑問に答えを出すには、まず、解決したい問題と同種の問題を市販モデルで解決できるか判断します。そのモデルは、同じ入力および類似のラベルでトレーニングされているでしょうか。たとえば、商品検索を行おうとしている場合に、当該モデルが入力にカタログ画像を使用してトレーニングされているとしましょう。しかし、行いたいのは、ユーザーがスマートフォンで撮影した商品写真に基づく商品検索です。カタログ画像でトレーニングされたモデルは、スマートフォンの写真に対しては機能しないため、自分で新たなモデルを構築する必要が生じます。
あるいは、欧州議会の演説でトレーニングされたベンダー製翻訳モデルを検討しているとします。同様の演説を翻訳したい場合には、同種のデータが使用されているそのモデルが役に立ちます。
次に考慮すべきなのは、自分自身よりベンダーのほうがデータを多く持っているかという点です。ベンダーのモデルが欧州議会の演説でトレーニングされていても、自分自身がもっと多くの演説データにアクセスできる場合には、自身でモデルを構築すべきです。ベンダーの持つデータのほうが多い場合は、モデルの購入をおすすめします。
まとめ: ベンダーのソリューションが同種の問題についてトレーニングされ、自分自身より多くのデータにアクセスできる場合は、それを購入します。
一般的な ML ユースケース向けのテクノロジー スタック
構築が必要な場合、どのようなテクノロジー スタックが必要になるのでしょうか。開発するにはどんなスキルが必要でしょうか。その答えは、解決しようとする問題の種類によって異なります。ML の応用には、大きく分けて、予測分析、非構造化データ、自動化、パーソナライズという 4 つのカテゴリがあります。おすすめのテクノロジー スタックは、それぞれやや異なっています。
予測分析
予測分析には、不正検出、クリック率予測、需要予測が含まれます。
ステップ 1: エンタープライズ データ ウェアハウスを構築する
ここでのデータは主に構造化データです。そこで、最初のステップとして、エンタープライズ データ ウェアハウス(EDW)にデータを保管することをおすすめします。EDW は、トレーニング サンプルおよび長期間追跡されるプロダクト履歴のソースであり、サイロを解消して組織全体からデータを収集できます。
ステップ 2: データ分析に習熟する
次に、データに関する素養を積み、データ分析スキルを身に付け、ダッシュボードの構築を開始して、データに基づく意思決定を可能にします。この時点でデータはすべて揃っており、どれが信頼できるものか把握できるでしょう。
ステップ 3: ML を構築する
EDW から、SQL パイプラインを使用してモデルを構築できます。EDW 内のデータで ML を行う場合は BigQuery ML を使用することをおすすめします。もっと高度なモデルを構築する場合は、BigQuery データで TensorFlow / Keras モデルをトレーニングできます。3 つ目のオプションは AutoML テーブルです。最先端の精度が得られ、オンライン マイクロサービスの構築に適しています。
非構造化データ
ML を使用して非構造化データから分析情報を取得するお客様事例としては、動画へのアノテーション付け、眼疾患の特定、メールの優先順位付けなどが挙げられます。非構造化データには、動画、画像、自然言語、テキストなどがあります。ディープ ラーニングによって、言語理解、画像分類、音声入力などの非構造化データについて ML を行う方法が、大きく変化しました。
非構造化データに使用されるモデルにはディープ ラーニングが導入されます。ここでは、AutoML の使用が費用対効果の面で非常に有利です。費やす時間を考えると、新しい ML モデルをゼロから作成する価値はほとんどありません。少しばかり良いモデルを得ようとするよりも、より多くのデータを収集するほうが、資金の使い道として効率的です。非構造化データの種類にかかわらず、小規模から中規模のデータサイズには AutoML の使用をおすすめします。
ただし AutoML には拡張限度があります。ある程度までデータのサイズが大きくなると、アーキテクチャ検索のコストが非常に高くなります。そのような場合は、カスタム再トレーニングが可能な TensorFlow Hub などの最高水準モデルを検討するとよいでしょう。データのサンプル数が数百万規模の場合は、独自のニューラル ネットワーク(NN)アーキテクチャを構築できます。ただし、この記事の冒頭のグラフと同様のグラフをプロットして、データサイズが横ばいになり始めていることを確認してください。カスタム NN アーキテクチャの構築は、横ばいになってから行うようにしてください(横ばいになってからは、データ量を増やしてもモデルの改善につながりません)。
自動化
ML を自動化に使用しているお客様事例には、メンテナンスのスケジューリング、小売店の来客数のカウント、診断書のスキャンなどがあります。このような問題を対象にテクノロジー スタックを選択する際の考慮事項は、構築する ML モデルは 1 つだけではないということです。たとえば、メンテナンスをスケジューリングしたり、トランザクションを拒否したりする場合には、リンクされた複数のモデルをトレーニングする必要があります。
個々のモデルではなく ML パイプラインの観点から物事を考えます。パイプラインでは、前述のテクノロジーをすべて使用したオーケストレーションが可能です。その後の運用化には 3 つの選択肢があり、洗練度別に 3 つのレベルがあります。
Vertex AI には、すぐに使えるサーバーレス トレーニングとバッチ / オンライン予測があります。データ サイエンティストのチームにはこれをおすすめします。
Deep Learning VM Image、Cloud Run、Cloud Functions または Dataflow は、カスタマイズされたトレーニングとバッチ / オンライン予測を特徴としています。データ エンジニアとサイエンティストから成るチームにはこれをおすすめします。
Vertex AI Pipelines は全面的なカスタマイズが可能であり、ML エンジニアリング チームとデータ サイエンス チームが分かれている組織におすすめです。
自動化を行うときに、1 つのパイプラインにまとめられる個々のモデルはさまざまであり、事前構築されるもの、カスタマイズされるもの、ゼロから構築されるものがあります。Vertex AI では、これらすべてのモデルタイプに対応する統合インターフェースの提供により、モデルの運用化が簡単になります。
パーソナライズ
ML を応用したパーソナライズの例には、顧客セグメンテーション、顧客ターゲティング、商品のおすすめなどがあります。顧客セグメンテーションでは構造化マーケティング データが使用されるため、パーソナライズにも EDW の使用をおすすめします。商品のおすすめについては、以前の購入およびウェブに関するログが同様に EDW の中にあります。クラスタリング アプリケーションまたはレコメンデーション システム(行列分解など)を強化し、EDW から直接エンベディングを作成して高度なレコメンデーション システムを実現できます。
個々のユースケースに関しては、データサイズとスコープに基づいてテクノロジー スタックを選択してください。BigQuery ML では行列分解の方法が迅速かつ簡単であるため、それから始めるとよいでしょう。ML の応用が有効であることがわかり、精度をもう少し上げたくなったら、AutoML Recommendations を試してみてください。しかし、データの大きさが AutoML Recommendations で対応可能な範囲を超えたら、独自のカスタム TensorFlow および Keras モデルのトレーニングを検討してください。
まとめると、ML の成功は「構築するか購入するか」という問いから始まります。市販のソリューションが類似のデータでトレーニングされており、自分自身の手持ちより多くのデータにアクセスできる場合は、そのソリューションを購入してください。それ以外の場合は、4 つの ML 応用カテゴリ向けにおすすめした上記のテクノロジー スタックを使用してソリューションを構築してださい。
Google の人工知能(AI)および ML ソリューションの詳細を確認し、オンデマンドの Applied ML Summit のセッションに登録してみてください。
-分析および AI ソリューション部門ディレクター Lak Lakshmanan




