説明可能性によって ML を向上させる Vertex AI Example-based Explanations
Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
人工知能(AI)は、人間には検知できないパターンを自動的に学習できるため、データをより有効に活用するための優れたツールとなります。高性能の機械学習モデルは質の高いデータの上に成り立っています。しかし、多くの場合、データセットに不適切なラベルや曖昧なサンプルなどの問題があることで、モデルのパフォーマンスが低下してしまっています。データ品質は企業にとって尽きることのない課題であり、機械学習(ML)のベンチマークで使用されているデータセットの中にもラベルエラーが発生しているものがあります。そのため、ML モデルのデバッグやトラブルシューティングが難しいことは周知の事実です。特別なツールがなければ、モデルのエラーを根本原因に結び付けることは難しく、問題を解決するための次のステップを知ることはさらに困難です。
Google は本日、ラベルの誤りなどのデータの課題を軽減するための実用的な説明を取得できる新機能である Vertex AI Example-based Explanations の公開プレビュー版がご利用いただけるようになったことを発表します。Vertex AI Example-based Explanations を使用すると、データ サイエンティストは誤分類されたデータを迅速に特定してデータセットを改善し、関係者をより効率的に意思決定や進行に関与させられるようになります。この新機能により、モデル改良のためにやみくもに推測を行う必要がなくなり、問題をより迅速に特定し、価値を生み出すまでの時間を短縮できます。
Examples-based Explanations が優れたモデルを作成する仕組み
より良いモデルを構築できるようユーザーをサポートすることから、関係者とのコミュニケーションを円滑にすることまで、Vertex AI Example-based Explanations にはさまざまな使用方法があります。以下は、この機能の特徴的な性能について説明したものです。

誤分類分析のユースケースを説明するために、鳥と飛行機の画像のみを利用して、STL-10 データセットのサブセットで画像分類モデルをトレーニングしました。その結果、鳥の画像が飛行機として誤分類されていることがわかりました。そのような画像の一つに対して、Example-based Explanations を使用して、潜在空間でこの誤分類された鳥の画像に酷似している他の画像をトレーニング データ内から取得しました。取得したこれらの画像を調べてみると、誤って分類された鳥の画像と、それに似た画像はどれも暗いシルエットであることがわかりました。
さらに詳しく確認するために、同様の検索例を拡張して 20 個の最近傍を表示しました。その結果、15 例が飛行機の画像であり、鳥の画像は 5 例だけであることが判明しました。これは、トレーニング データの鳥の画像の 1 つだけが暗いシルエットの画像であったため、トレーニング データの中に暗いシルエットの鳥の画像が不足していることを示しています。すぐに実行可能なインサイトは、鳥のシルエットの画像を使用してより多くのデータを収集することにより、モデルを改善することでした。

誤分類の分析に限らず、Example-based Explanations によって能動的学習が可能になるため、Example-based Explanations が混在する分類から取得された場合、データを選択的にラベル付けできます。たとえば、1 点の画像に対する合計 10 個の説明のうち、5 つは「鳥」のクラスから、5 つは「飛行機」からのものだとします。この画像は人間によるアノテーションの候補となり、データをさらに充実させることができます。
Example-based Explanations は、画像以外にも使用できます。複数のタイプのデータ(画像、テキスト、表形式)のエンベディングを生成できます。
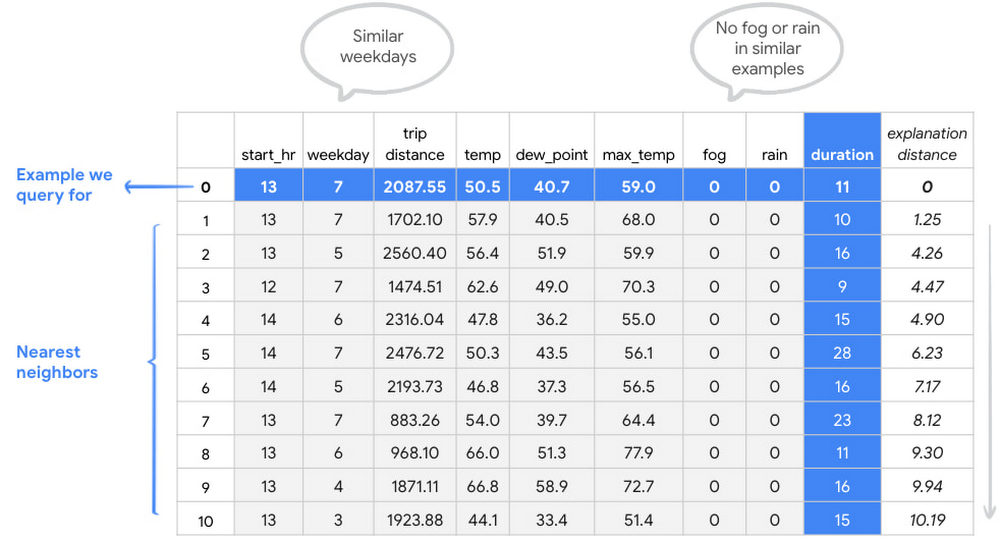
Example-based Explanations の使用方法を示した図を見てみましょう。サイクリング時間を予測するトレーニング済みのモデルがあるとします。モデルのサイクリングの予測時間を調べる場合、Example-based Explanations を使用することで基礎となるデータポイントの問題を特定できます。
下の図の 5 行目を見ると、移動距離に比べて所要時間が長すぎるように見えます。このサイクリングは、クエリのサイクリングと非常に似通っています。これは、Example-based Explanations が同様の例を見つけることになっているため、想定されていたものです。距離、時刻、気温などの条件のすべてが、クエリのサイクリングと 5 行目のサイクリングの間で非常に類似していることを考慮すると、所要時間ラベルが疑わしいと考えられます。この直後の手順は、このデータポイントを詳しく調べてデータセットから削除するか、所要時間の違いを生じさせた要因(自転車に乗っている人が休憩した、など)を見落としていないか確認することです。
Vertex AI で Examples-based Explanations を使ってみる
Example-based Explanations はわずか 3 つのステップでセットアップできます。
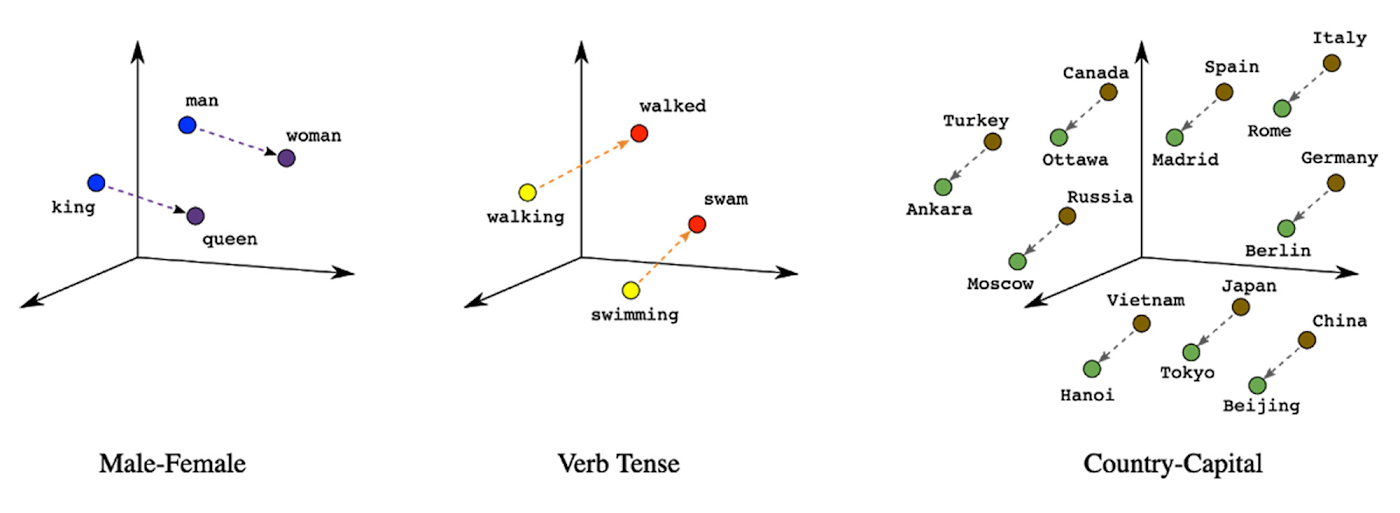
まず、モデルとデータセットをアップロードします。このサービスは、潜在空間(エンベディングと呼ばれる)にデータセット全体を表示します。具体的な例として、潜在空間の単語を調べてみましょう。下の図は、こうした単語のエンベディングを示しています。ここでは、各単語の有意義なセマンティクス(動詞間の関係、国と首都の関係など)がベクトル空間の位置で符号化されます。
次に、インデックスとモデルをデプロイします。その後、Example-based API でクエリを実行できるようになります。
これで、同様のデータポイントに対してクエリを実行できます。また、モデルを再トレーニングするか、データセットを変更する場合は、手順 1 と 2 を繰り返すだけで済みます。
内部的には、Example-based Explanations API は Google の研究組織が開発した最先端のテクノロジー(こちらのブログ投稿で紹介)を基礎として構築されています。このテクノロジーは、Google 検索、YouTube、Play ストアなどの幅広い Google アプリケーションで大規模に使用されています。このテクノロジー「ScaNN」を使用すると、類似例のクエリをその他のベクトル類似性検索手法よりも大幅に高速化し、再現率を改善できます。
Example-based Explanations の使用方法に関する詳細は、こちらの 構成に関するドキュメントにある手順を実施してご確認ください。Vertex AI の詳細については、プロダクト ページにアクセスするか、こちらのチュートリアルとリソースの概要をご覧ください。
- Cloud AI プロダクト マネージャー Irina Sigler




