Vertex AI Example-based Explanations improve ML via explainability
Irina Sigler
Product Manager, Cloud AI
Artificial intelligence (AI) can automatically learn patterns that humans can’t detect, making it a powerful tool for getting more value out of data. A high-performing model starts with high-quality data, but in many cases, datasets have issues such as incorrect labels or unclear examples that contribute to poor model performance. Data quality is a constant challenge for enterprises—even some datasets used as machine learning (ML) benchmarks suffer from label errors. ML models are thus often notoriously difficult to debug and troubleshoot. Without special tools, it’s difficult to connect model failures to root causes and even harder to know the next step to resolve the problem.
Today, we're thrilled to announce the public preview of Vertex AI Example-based Explanations, a novel feature that provides actionable explanations to mitigate data challenges such as mislabeled examples. With Vertex AI Example-based Explanations, data scientists can quickly identify misclassified data, improve datasets, and more efficiently involve stakeholders in the decisions and progress. This new feature takes the guessing games out of model refinement, enabling you to identify problems faster and speed up time to value.
How Examples-based Explanations create better models
Vertex AI Example-based Explanations can be used in numerous ways, from supporting users in building better models to closing the loop with stakeholders. Below, we describe some notable capabilities of the feature:

To illustrate the use case of misclassification analysis, we trained an image classification model on a subset of the STL-10 dataset, using only images of birds and planes. We noted some images of birds being misclassified as planes. For one such image, we used Example-based Explanations to retrieve other images in the training data that appeared most similar to this misclassified bird image in the latent space. Examining those, we identified that both the misclassified bird image and the similar images were dark silhouettes.
To take a closer look, we expanded the similar example search to show us the 20 nearest neighbors. From this, we identified that 15 examples were images of planes, and only five were images of birds. This signaled a lack of images of birds with dark silhouettes in the training data, as only one of the training data bird images was a dark-silhouetted one. The immediate actionable insight was to improve the model by gathering more data with images of silhouetted birds.

Beyond misclassification analysis, Example-based Explanations can enable active learning, so that data can be selectively labeled when its Example-based Explanations come from confounding classes. For instance, if out of 10 total explanations for an image, five are from class “bird” and five are from class “plane,” the image can be a candidate for human annotation, further enriching the data.
Example-based Explanations are not limited to images. They can generate embeddings for multiple types of data: image, text, tabular.
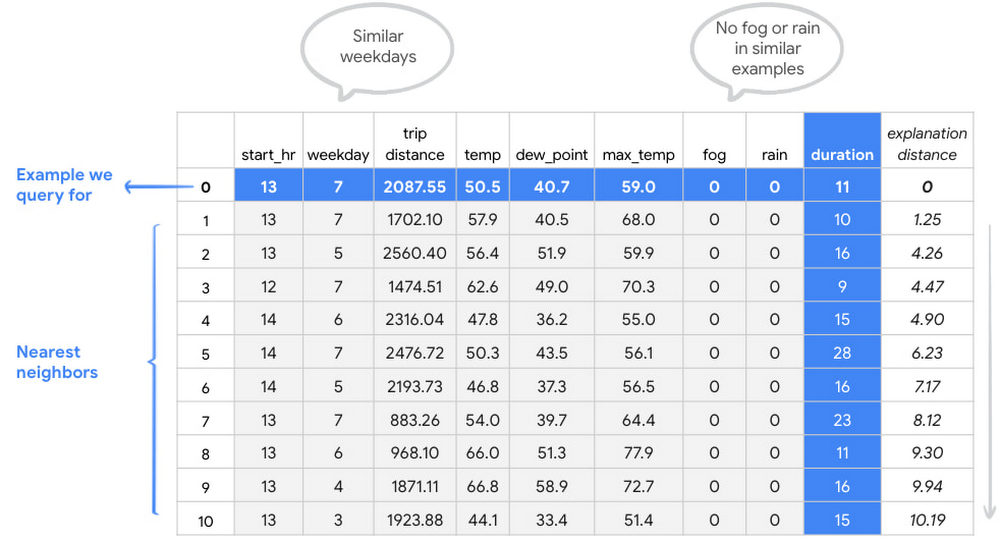
Let’s look at an illustration of how to use Example-based Explanations with tabular data. Suppose we have a trained model that predicts the duration of a bike ride. When examining the model’s projected duration for a bike ride, Example-based Explanations can help us identify issues with the underlying data points.
Looking at row #5 in the below image, the duration seems too long when compared with the distance covered. This bike ride is also very similar to the query ride, which is expected since Example-based Explanations are supposed to find similar examples. Given the distance, time of day, temperature, etc. are all very similar between the query ride and the ride in row #5, the duration label seems suspicious.The immediate next step is to examine this data point more closely and either remove it from the dataset or try to understand if there might be some missing features (say, whether the biker took a snack break) contributing to the difference in durations.
Getting started with Examples-based Explanations in Vertex AI
It takes only three steps to set up Example-based Explanations.
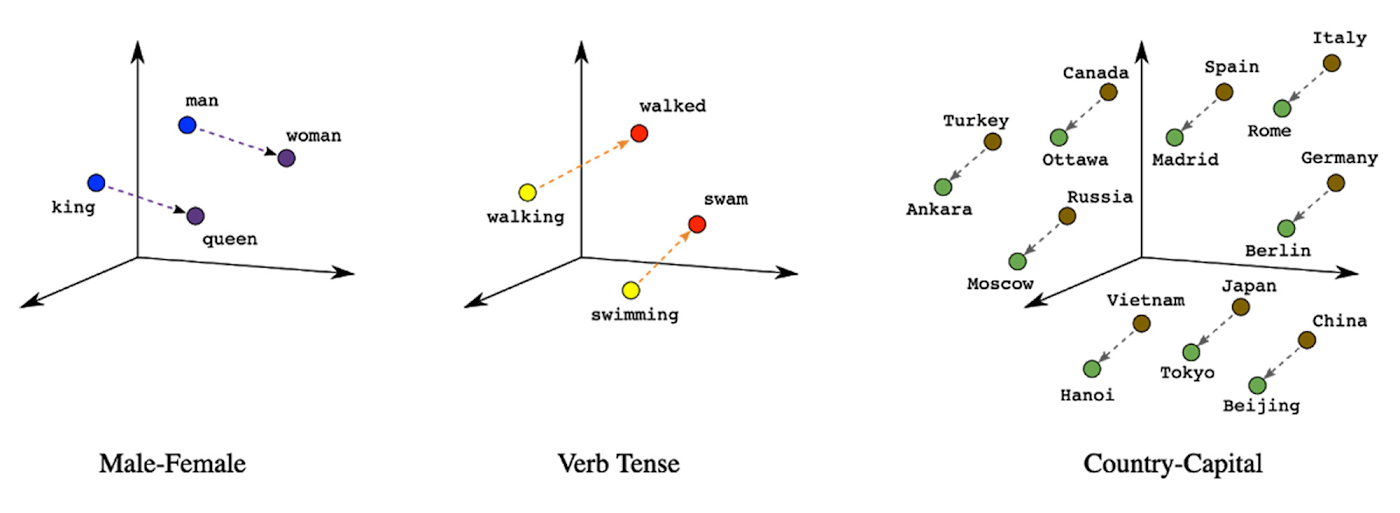
- First, upload your model and dataset. The service will represent the entire dataset in a latent space (called embeddings). As a concrete example, let’s examine words in a latent space. The below visualizations show such word embeddings, where the position in the vector space encodes meaningful semantics of each word, such as the relation between verbs or between a country and its capital.
- Next, deploy your index and model, after which the Example-based API will be ready to query.
- Then, you can query for similar data points and only need to repeat steps 1 and 2 when you retrain the model or change your dataset.
Learn how to use Example-based Explanations by following the instructions available in this configuration documentation. To learn more about Vertex AI, visit our product page or explore this summary of tutorials and resources.




