Cloud TPU v4 が MLPerf 2.0 ベンチマーク 5 項目で最速のトレーニング時間を記録
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 30 日に、Google Cloud blog に投稿されたものの抄訳です。
今日、ML を活用したイノベーションは、コンピューティングを根底から変革し、まったく新しいクラスのインターネット サービスを生み出しています。たとえば、PaLM や Chinchilla など最近の最先端大規模モデルは、人間の創造性が ML サービスによって増強されるようになるというパラダイム シフトの到来を告げています。これらの兆候が示すとおり、私たちは今、コンピューティングの大きな飛躍の初期段階にあります。この変革を実現するには、民主化された手頃な価格のアクセスをクラウド コンピューティングによって可能にし、最適なコンピューティング、ネットワーキング、ストレージ、ML を、これまでにない大規模な問題ドメインにシームレスに適用できるようにする必要があります。
MLCommons® Association から本日発表された MLPerf™ 2.0 の結果は、極めて強力かつ効率的な ML インフラストラクチャが場所を問わず一般利用可能になっていることを浮き彫りにしました。Google の TPU v4 ML スーパーコンピュータは、ベンチマーク 5 項目で最速記録を打ち立て、他団体の最速提出値に対して平均 1.42 倍、Google 自身の MLPerf 1.0 提出値に対して 1.5 倍の速度向上を実現しました。さらに説得力のある事実は、これらのレコード実行のうち 4 件が、Google I/O において Google が発表した一般利用可能な Google Cloud ML ハブで実施されたものであることです。ML ハブは、エネルギーの 90% 以上をカーボンフリーでまかなう、Google のオクラホマ データセンターで運営されています。
具体的な成果は次のとおりです。
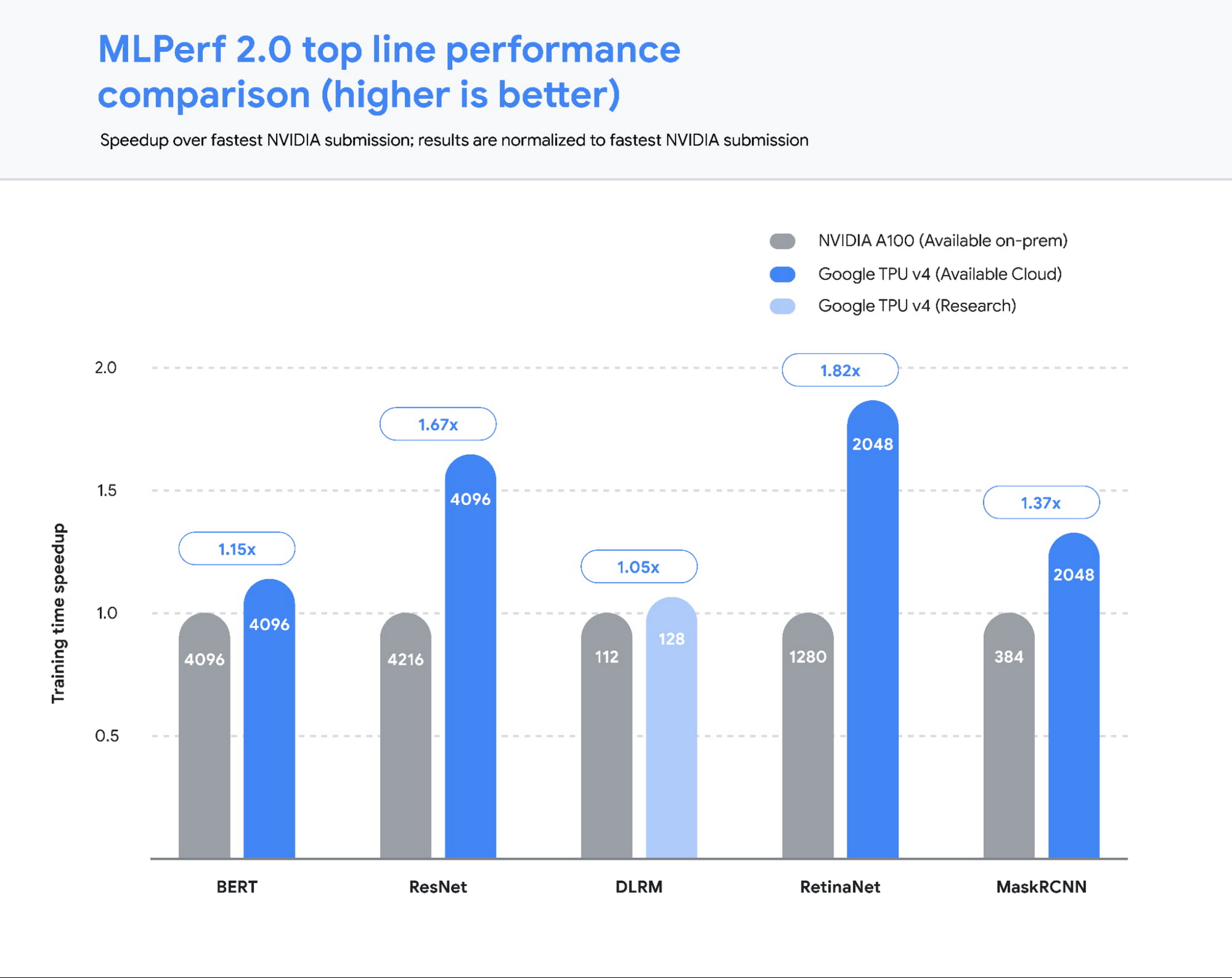
図 1: TPU は、公開されているベンチマーク 5 項目すべてにおいて、他団体の最速提出値(NVIDIA オンプレミス)よりも大幅に高速であることを示しました。棒グラフが高いほど、パフォーマンスが優れていることを示します。棒グラフ内の数字は、各提出値に使用されたチップ / アクセラレータの数量を表しています。
パブリック クラウドで優れたパフォーマンスを実証
すべて TensorFlow で実行された Google の 2.0 提出値1は、ベンチマーク 5 項目すべてにおいて優れたパフォーマンスを示しました。提出値のうち 2 つはフルスケールの TPU v4 Pod で実行されたものです。各 Cloud TPU v4 Pod は超高速相互接続ネットワークで互いに接続された 4,096 のチップから構成されます。ホストあたりの帯域幅は業界トップの毎秒 6 テラビット(Tbps)であり、最大規模のモデルでも迅速なトレーニングが可能です。
ハードウェアのほかにも、TPU ソフトウェア スタック改善のための Google の取り組みがこれらのベンチマーク結果に大いに貢献しています。これらの改善の多くは、TPU コンパイラとランタイムのスケーラビリティおよびパフォーマンスの最適化によるものです。埋め込み検索の高速化や TPU Pod 全体でのモデル重み分布の改善などを含む最適化は、TPU ユーザーの間で広く利用できるようになっています。たとえば、画像モデルとレコメンデーション モデルで最高のパフォーマンスを発揮できるよう、仮想化スタックにパフォーマンスの改善を加え、CPU ホストと TPU チップの両方の計算能力をフルに活用できるようにしました。これらの最適化は、検索や YouTube など、Google 内部の最先端 ML ユースケースからの教訓を反映したものです。こうした取り組みから得たメリットを Google Cloud ユーザーの皆さんと共有できることをうれしく思います。
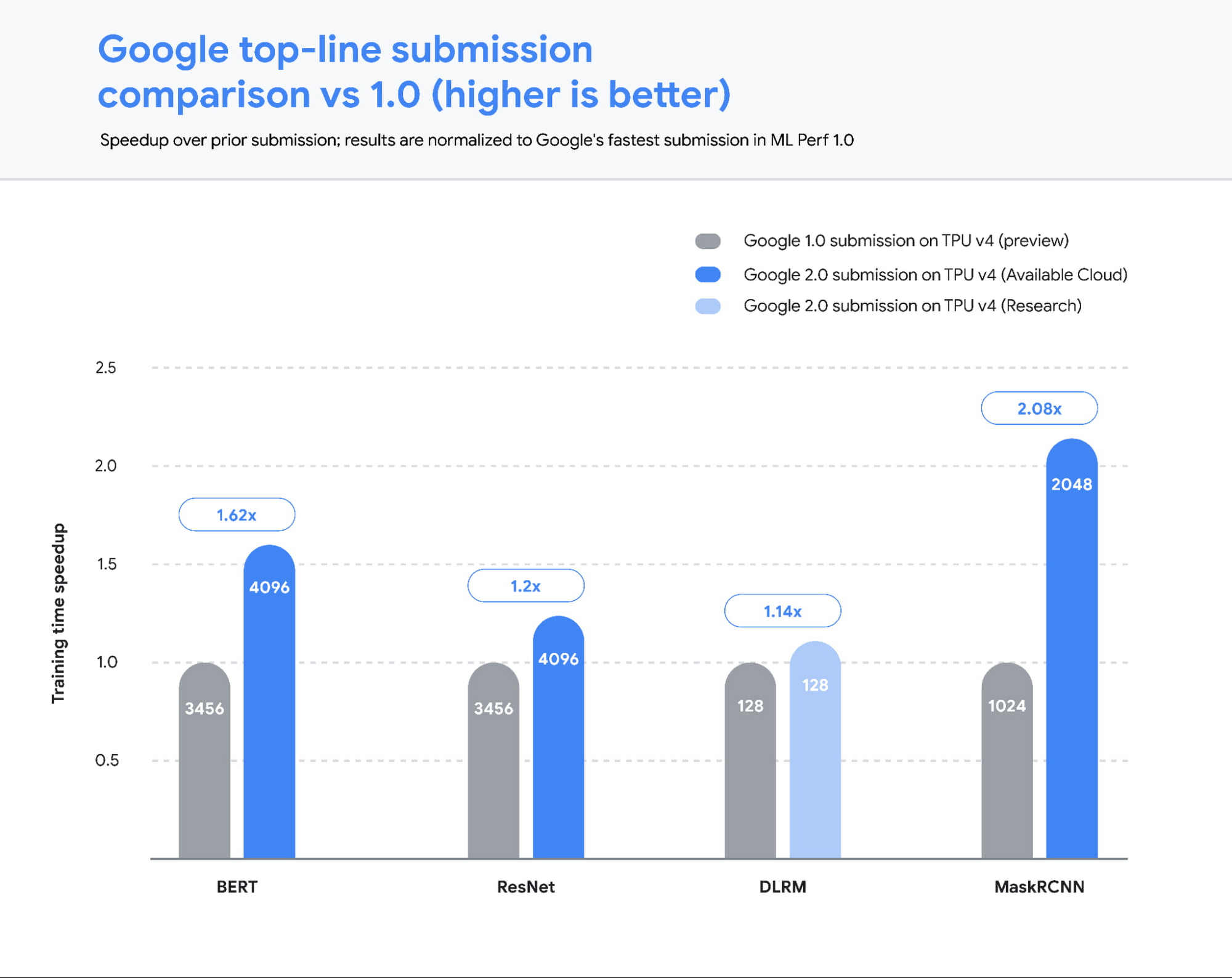
図 2: 2.0 の提出値は、コンパイラ インフラストラクチャの改善を活かし、チップあたりパフォーマンスとスケーラビリティの向上を実現し、1.0 の提出値と比べて平均 1.5 倍高速化しています ²
MLPerf での成果をお客様に還元
大規模環境における業界トップレベルの Cloud TPU のパフォーマンスは、お客様にとってのコスト削減にもつながります。図 3 に示す分析に基づくと、Google Cloud の Cloud TPU は、Microsoft Azure 上の A100 と比較して最大 35〜50% の節約を実現します(図 3 を参照)。この結果は次の方法で算出されました2。
Google と NVIDIA からの最大規模の MLPerf 提出値、つまり ResNet と BERT のエンドツーエンドの時間を比較しました。これらの提出値では、同様の数のチップ(4,000 個以上の TPU および GPU チップ)が使用されています。パフォーマンスはチップ数に比例してスケールしないため、チップ数がほぼ同じである 2 つの提出値を比較しました。
ResNet では、チップ数 4,216 の A100 と Google のチップ数 4,096 の TPU の提出値の比較を簡素化するため、GPU に有利になるように、4,096 個の A100 チップが 4,216 個のチップと同じパフォーマンスを実現すると仮定しました。
料金については、一般提供されている Cloud TPU v4 のオンデマンド料金(チップあたり 1 時間 3.22 ドル)と、Azure が A100 に設定しているオンデマンド料金3(チップあたり 1 時間 4.1 ドル)を比較しました。オンプレミス(NVIDIA の結果)から Azure Cloud に移行する際の仮想化のオーバーヘッドをゼロと想定しているため、ここでも A100 に有利に計算されています。
GPT-3 や PaLM などの実際のモデルが、MLPerf ベンチマークで使用されている BERT および ResNet モデルよりもはるかに大きいことを考えると、コストの節約は特に重要な意味を持ちます。PaLM は 5,400 億個のパラメータに基づくモデルですが、MLPerf ベンチマークで使用されている BERT モデルのパラメータ数はわずか 3 億 4,000 万個であり、スケールにして 1,000 倍の違いがあります。Google の経験から言えることとして、TPU を使用するメリットは規模とともに大幅に拡大し、Cloud TPU v4 でのトレーニングをさらに魅力的なものにします。
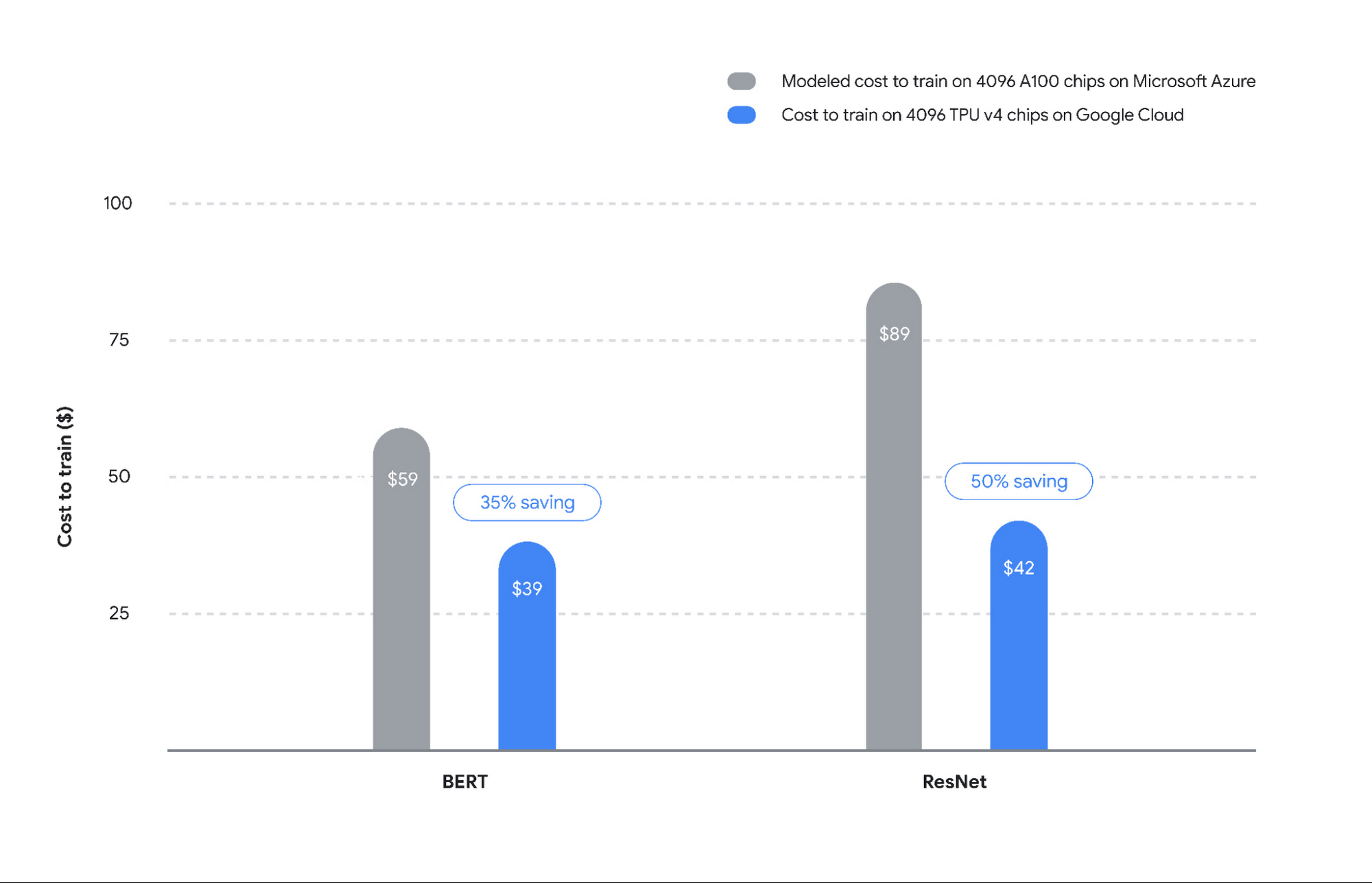
図 3: Cloud TPU v4 を使用すると、BERT モデルの場合で A100 よりも約 35% の節約、ResNet モデルの場合で約 50% の節約につながります ⁴
2 つのメリットを同時に得る - サステナビリティへの継続的な取り組み
パフォーマンスを大規模に実現する場合は、主要な制約事項および最適化目標として環境への配慮を念頭に置く必要があります。MLPerf の結果を生成するために使用される Cloud TPU v4 Pod は、90% カーボンフリー エネルギーを活用し、1.10 の電力使用効率で稼働しています。つまり、データセンターに供給される電力のうち、電力変換や発熱などのロスによって損失されている電力の割合は 10% 未満に抑えられています。TPU v4 チップは、v3 世代の 3 倍に相当するピーク FLOPS を実現しています。カーボンフリー エネルギーの使用に加え、並外れた電力使用効率と計算効率を兼ね備えた Cloud TPU は、世界で最も効率的な集積回路の一つとなっています4。
Cloud TPU への切り替え
お客様にとって今は、Cloud TPU を導入する最高のタイミングです。Cohere、LG AI Research、Innersight Labs、Allen Institute などのお客様は、Cloud TPU に切り替えた理由として、大規模環境での優れたパフォーマンスとコスト削減、そしてサステナビリティへの揺るぎない取り組みを挙げています。ワークロードに Cloud TPU を導入する準備ができている場合は、こちらのフォームに必要事項をご記入ください。Google Cloud の TPU サービスを利用した ML の飛躍的進歩とイノベーションのさらなる加速について、世界中の ML 実務担当者の方をサポートさせていただけることを楽しみにしております。




1. 終了した MLPerf™ v2.0 トレーニング。https://mlcommons.org/en/training-normal-20/(2022 年 6 月 29 日)(結果 2.0-2010、2.0-2012、2.0-2098、2.0-2099、2.0-2103、2.0-2106、2.0-2107、2.0-2120)から取得されました。MLPerf の名前とロゴは、米国および他の国々における MLCommons Association の商標です。権利はすべて同組織が有しており、無断使用は固く禁じられています。詳しくは、www.mlcommons.org をご覧ください。
2. 終了した MLPerf v1.0 および v2.0 トレーニング。https://mlcommons.org/en/training-normal-20/(2022 年 6 月 29 日)(結果 1.0-1088、1.0-1090、1.0-1092、2.0-2010、2.0-2012、2.0-2120)から取得されました。
3. このベンチマークには、8 台の 80 GB NVIDIA Ampere A100 GPU(ディープ ラーニングおよび密結合 HPC 向けに設計され、CentOS または Ubuntu Linux に対応した Azure の主力 GPU 対応製品)を搭載した、ND96amsr A100 v4 Azure VM が使用されています。
4. トレーニングのコストは公式の MLPerf 指標ではなく、MLCommons Association によって検証されていません。本文中に説明されているように、Azure のパフォーマンスは Azure に有利な見積もり値であり、MLPerf の結果ではありません。計算は、終了した MLPerf v2.0 トレーニングの結果に基づいています。https://mlcommons.org/en/training-normal-20/(2022 年 6 月 29 日)(結果 2.0-2012、2.0-2106、2.0-2107)から取得されました。
- プリンシパル エンジニア、Naveen Kumar
- ML インフラストラクチャ担当プロダクト管理ディレクター、Vikram Kasivajhula




