Google Cloud、Cloud TPU v4 と 90% カーボンフリー エネルギーを活用した、世界最大級の一般利用可能な ML ハブを発表
Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
検索、YouTube のような Google プロダクトに見られる最先端機能は Google のカスタム機械学習(ML)アクセラレータである Tensor Processing Unit(TPU)が実現しています。Google Cloud ユーザーには、このアクセラレータは Cloud TPU として提供されています。ML の機能、パフォーマンス、スケールに対するユーザーの要求は、かつてないペースで増大し続けています。人工知能(AI)における次世代の基盤となる進歩に対応するため、Google は本日、Cloud TPU v4 Pod を備えた Google Cloud 機械学習クラスタ(プレビュー版)を発表しました。これは、世界最高レベルの速度、効率、持続可能性を誇る ML インフラストラクチャ ハブです。
研究者やデベロッパーは Cloud TPU v4 Pod で駆動する Google Cloud の ML クラスタを使用して、より洗練されたモデルをトレーニングし、大規模な自然言語処理(NLP)、レコメンデーション システム、コンピュータ ビジョン アルゴリズムなどのワークロードを強化して、AI の最前線でブレークスルーを実現できます。9 エクサフロップの全体ピーク パフォーマンスを発揮する Google の Cloud TPU v4 Pod クラスタは、90% のカーボンフリー エネルギーで動作することに加え、累積コンピューティング能力の点で世界最大の一般利用可能な ML ハブだと言えます。
「2,000 人の IT 部門意思決定者へ実施した最近の調査では、AI プロジェクト失敗の多くは不適切なインフラストラクチャ機能が根本原因であることがわかりました。企業における目的特化型 AI インフラストラクチャの重要性が増大する中、Google はこれに対応するため、9 エクサフロップの集約演算が可能な新しい機械学習クラスタをオクラホマ州で立ち上げました。これは世界最大の一般利用可能な ML ハブと言え、90% のカーボンフリー エネルギーで動作が可能だと報告されています。このような取り組みは、持続可能性を意識した AI インフラストラクチャの革新への Google の継続的なコミットメントを示すものです」- IDC、インフラストラクチャ リサーチ担当シニア バイス プレジデント、Matt Eastwood 氏
「可能性」の拡大
Google I/O 2021 での Cloud TPU v4 の発表を受け、Google は、Cohere、LG AI Research、Meta AI、Salesforce Research などのいくつかのトップ AI リサーチチームに Cloud TPU v4 Pod への早期アクセス権を付与しました。研究者は TPU v4 が提供するパフォーマンスとスケーラビリティに非常に満足し、特に迅速な相互接続、最適化されたソフトウェア スタック、Google の新しい TPU VM アーキテクチャにより独自のインタラクティブな開発環境をセットアップできる機能、そして JAX、PyTorch、TensorFlow など任意のフレームワークを使用できる柔軟性が高く評価されました。このような特性により、研究者は優れたコスト パフォーマンスと炭素効率性を実現しつつ、最先端の大規模 ML モデルをトレーニングして AI の限界を押し上げることができます。




さらに TPU v4 は、言語理解、コンピュータ ビジョン、音声認識など数多くの領域で Google Research にブレークスルーをもたらしました。たとえば、最近発表された Pathways Language Model(PaLM)は、2 つの TPU v4 Pod 間でトレーニングされます。
「先進の AI ハードウェアにもっとアクセスしやすくするため、Google は数年前に TPU Research Cloud(TRC)プログラムを発足しました。これは、世界中の多数の ML 愛好家に TPU への無償アクセスを提供するものでした。以来、このプログラムは、『Writing Persian poetry with AI(AI でペルシャ語の詩を書く)』から『Discriminating between sleep and exercise-induced fatigue using computer vision and behavioral genetics(コンピュータ ビジョンと行動遺伝学を使用した、睡眠とエクササイズによる疲労との相違の識別)』まで幅広いトピックについて数百もの論文を発表し、オープンソース GitHub ライブラリを公開しています。Cloud TPU v4 のリリースは Google Research と TRC プログラムの双方にとって重要なマイルストーンです。また、AI の善用に向けて世界中の ML デベロッパーと長期的に協働できることをとても嬉しく思います」- Google Research and AI、シニア バイス プレジデント、Jeff Dean
持続可能な ML のブレークスルー
この研究が主にカーボンフリー エネルギーによって実施されているという事実は、Google Cloud ML クラスタの卓越性をさらに高めています。Google は、持続可能性へのコミットメントの一環として、2017 年以降、Google のデータセンターおよび Cloud リージョンは年間エネルギー消費量の 100% に相当する再生可能エネルギーの購入という目標を達成してきました。さらに 2030 年までに、事業全体を 24 時間 365 日カーボンフリー エネルギー(CFE)で行うことを目指しています。ML クラスタが所在する Google オクラホマ データセンターは、この目標に向けて順調に進んでおり、同じグリッド内では 90% カーボンフリー エネルギー(時間単位)で運用しています。
また、直接的なクリーン エネルギーの利用に加え、電力使用効率(PUE)1評価で 1.10 を実現し、世界で最もエネルギー効率の高いデータセンターの一つとなっています。TPU v4 チップ自体のエネルギー効率も非常に高く、TPU v3 の最大電力ワットあたり約 3 倍のピーク FLOPS を実現しています。高エネルギー効率の ML 固有ハードウェアを搭載する Cloud TPU v4 は、優れたクリーン電力で駆動する高効率なデータセンターで3 つの主要なベスト プラクティスを実現し、エネルギー使用量と炭素排出量を大幅に削減します。
驚異的なスケールとコスト パフォーマンス
主要な ML チームとの作業では、持続可能性に加え、スケールとコスト パフォーマンスという 2 つの課題をさらに確認しました。オクラホマの ML クラスタは、業界で最もエコなクラウド上で、研究者がモデルをトレーニングするために必要なキャパシティを優れたコスト パフォーマンスで提供しています。Cloud TPU v4 は、このような課題を解決するための中心的な役割を担っています。
スケール: 各 Cloud TPU v4 Pod は超高速相互接続ネットワークで互いに接続された 4096 のチップから構成されます。ホストあたりの帯域幅は業界トップの毎秒 6 テラビット(Tbps)に相当し、最大規模のモデルでも迅速なトレーニングが可能です。
コスト パフォーマンス: 各 Cloud TPU v4 チップのピーク FLOPS は、Cloud TPU v3 の最大 2.2 倍で、1 ドルあたりのピーク FLOPS は最大 1.4 倍です。また、Cloud TPU v4 は、チップが数千規模での ML モデルのトレーニングできわめて高い FLOPS 使用率を達成しています。ピーク FLOPS はシステム比較の基本として言及されることがよくありますが、実際にモデルのトレーニング効率を決定するのは大規模に持続する FLOPS です。Cloud TPU v4 の高い FLOPS 使用率(高ネットワーク帯域幅とコンパイラ最適化により他のシステムより大幅に高い)により、トレーニング時間が短縮され、コスト効率が向上します。
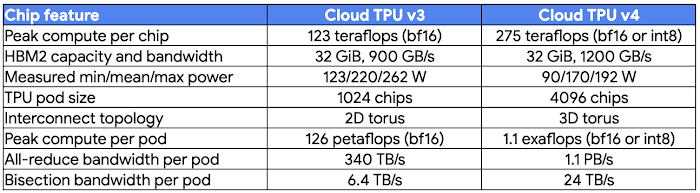
Cloud TPU v4 Pod スライスの構成は、4 つのチップ(1 つの TPU VM)から数千のチップまで可能です。フル Pod より小さい前世代 TPU のスライスにはトーラスリンク(「ラップアラウンド接続」)がありませんでしたが、64 以上のチップの Cloud TPU v4 Pod の全スライスには、3 つのディメンションすべてにトーラスリンクがあります。これにより、集団通信オペレーションに提供できる帯域幅がさらに大きくなります。
また、Cloud TPU v4 では、単一のデバイスから 32 GiB メモリにフルでアクセスできます(TPU v3 では 16 GiB)。組み込みアクセラレーションは速度が 2 倍で、大規模なレコメンデーション モデルのトレーニング時もパフォーマンスが向上します。
料金
Cloud TPU v4 Pod へのアクセスは、評価(オンデマンド)、プリエンプティブル、および確約利用割引(CUD)の各オプションがあります。詳細については、こちらのページをご覧ください。
使ってみる
Google は、Google サービスを駆動する最先端の ML インフラストラクチャをユーザーの皆様にご利用いただき、コミュニティで Cloud TPU v4 の業界トップのスケール、パフォーマンス、持続可能性、コスト効率を活用した ML による次のブレークスルーが実現するのを楽しみにしています。
AI ワークロードに Cloud TPU v4 Pod を使用するには、担当の Google Cloud アカウント マネージャーに問い合わせるか、こちらのフォームを送信してください。
オープンソース ML 研究における Cloud TPU の利用にご興味がありましたら、Google の TPU Research Cloud プログラムをご確認ください。
謝辞
著者一同は、このリリースの実現に取り組んだ Cloud TPU エンジニアリング チームとプロダクト チームに感謝いたします。また、このブログ投稿の執筆にご協力いただいたソフトウェア エンジニアの James Bradbury、アウトバウンド プロダクト マネージャーの Vaibhav Singh、プロダクト マネージャーの Aarush Selvan にも感謝いたします。
1. Google は、オーバーヘッドのすべての原因も含め、すべてのシーズンを含む直近 12 か月間の包括的な PUE を報告しています。
- インフラストラクチャ担当バイス プレジデント兼ゼネラル マネージャー Sachin Gupta
- Cloud TPU 担当プロダクト マネージャー Max Sapozhnikov


