Cloud TPU VM の一般提供を開始

Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 10 日に、Google Cloud blog に投稿されたものの抄訳です。
昨年、Google Cloud に Cloud TPU VM が導入され、TPU ホストマシンへの直接アクセスが提供されることで、TPU ハードウェアをより簡単に利用できるようになりました。本日は、TPU VM の一般提供(GA)についてお知らせいたします。
Cloud TPU VM により、物理的な TPU ハードウェアが接続されているのと同じホスト上でインタラクティブに作業できます。このアクセスのメカニズムは、より的確にデバッグを行うことだけでなく、(ネットワーク アクセスが発生する)TPU ノード アーキテクチャでは実現できなかった分散強化学習などのトレーニング設定も可能にするため、急速に成長している TPU ユーザー コミュニティによって積極的に採用されています。
一般提供版の新機能
Cloud TPU は、大規模なランキングやレコメンデーションのワークロード用に最適化されました。嬉しいお知らせもあります。この新機能の先行ユーザーである Snap 社では、ビジネス クリティカルな広告ランキングのワークロードにおいて、約 4.65 倍のパフォーマンス/TCO 改善を達成しました。Snap 社のブログ投稿「大規模なレコメンデーション モデルのトレーニング」のハイライトを以下にご紹介します。
> TPU は CPU と比べて、レコメンデーション システムモデルのトレーニング速度を著しく向上させ、トレーニング費用を大幅に削減できる
> Cloud TPU 向けの TensorFlow は、大きな埋め込みテーブルと検索速度に対処するための優れた API を提供する
> TPU v3-32 スライスでは、同等の A100 構成と比較して約 3 倍優れたスループット(A100 では 67.3% のスループット減)を得られ、費用を 52.1% 低く抑えることができた(約 4.65 倍のパフォーマンス/TCO)
ランキングとレコメンデーション
この TPU VM の一般提供版とともに、Google は新しい TPU Embedding API を導入します。これにより、ML ベースのランキングやレコメンデーションのワークロードを加速できます。
現在、多くの企業のビジネスに音声 / 動画レコメンデーション、プロダクトのレコメンデーション(アプリ、e コマース)、広告ランキングなど、ランキングやレコメンデーションのユースケースが組み込まれています。これらの企業は、ユーザーにサービスを提供し、ビジネス目標を推進するにあたって、ランキングやレコメンデーションのアルゴリズムに依存しています。ここ数年、これらのアルゴリズムに対するアプローチは、純粋に統計的なものから、ディープ ニューラル ネットワーク(DNN)をベースとしたものへと進化しています。こうした最新の DNN ベースのアルゴリズムでは、より高いスケーラビリティと精度が得られますが、一方で大量のデータを使用する傾向があり、従来の ML インフラストラクチャでのトレーニングやデプロイが難しく、費用がかかる場合があります。
Cloud TPU による高速化を組み込むことで、この問題を低費用で解決できます。Embedding API は Pod 内にある、カスタム構築された相互接続を通じて互いにつながっている数百の Cloud TPU チップへのシャーディングを自動的に行うことにより、埋め込みテーブルなどの大容量データを効率的に処理できます。
すぐに使用を開始できるよう、Google は TF2 ranking and recommendation API を Tensorflow Recommenders ライブラリの一部としてリリースします。また、TF2 モデルガーデンにて DLRM および DCN v2 ランキング モデルをオープンソース化いたしました。詳しいチュートリアルはこちらでご利用いただけます。
フレームワーク サポート
TPU VM 一般提供版では、3 つの主要なフレームワーク(TensorFlow、PyTorch、JAX)をサポートし、それぞれのフレームワークとの設定を容易にするために最適化された 3 つの環境を提供します。一般提供版は TensorFlow v2-tf-stable、PyTorch/XLA v1.11 、JAX [0.3.6] で検証されています。
TPU VM 固有の機能
TPU VM では、ローカル実行のセットアップ(ユーザーがトレーニング ワークロードを実行するのと同じホストに接続された TPU ハードウェア)により、TPU ノード アーキテクチャを上回るいくつかの追加機能が提供されています。
入力パイプラインのローカル実行
入力データ パイプラインは、TPU ホスト上で直接実行されます。この機能により、これまで PyTorch / JAX の分散トレーニングでインスタンス グループという形で使われていた貴重なコンピューティング リソースを節約できます。Tensorflow の場合、分散トレーニングの設定には 1 つのユーザー VM しか必要なく、データ パイプラインは TPU ホスト上で直接実行されます。
以下の調査は、TPU VM と TPU ノード アーキテクチャ(ネットワーク接続された Cloud TPU)で 10 エポック実行した Transformer(FairSeq、PyTorch/XLA)トレーニングの費用を比較した概要を示しています。
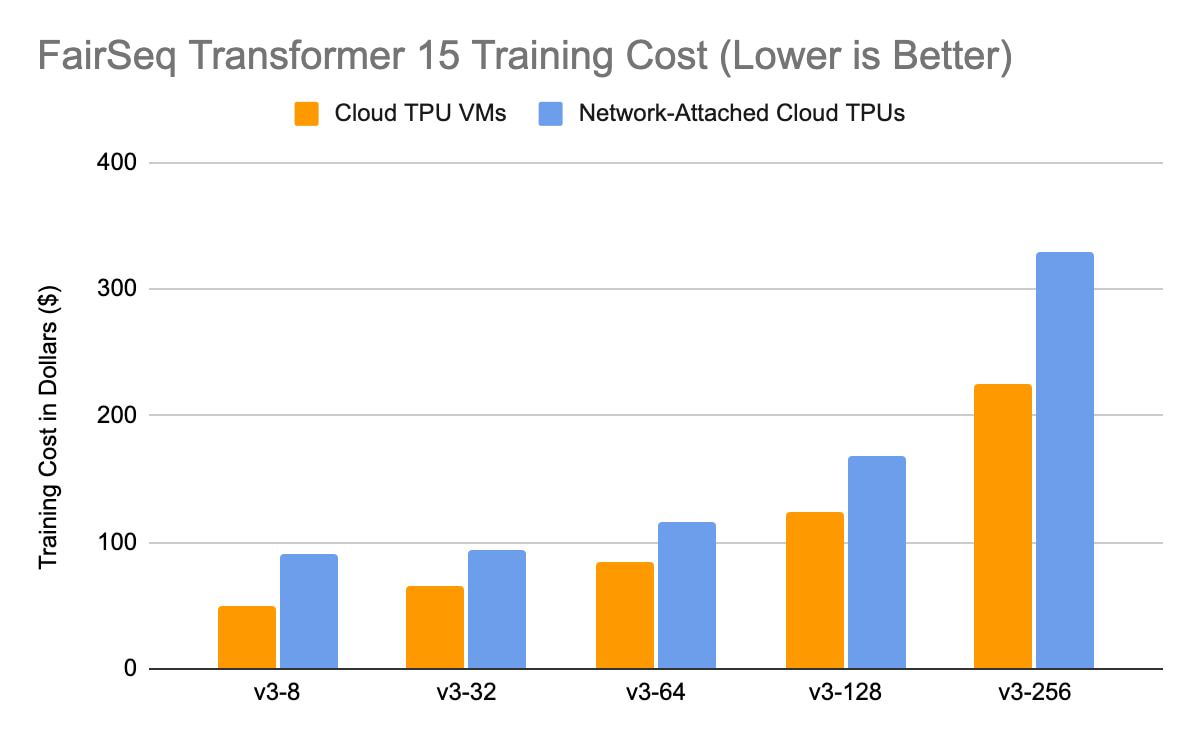
Google 内部データ(Google が Cloud TPU 上で実施した公開ベンチマーク)。
TPU VM を使用した分散強化学習
また、アクセラレータを使用したホストでのローカル実行は、分散強化学習などのユースケースをも可能にします。seed-RL、IMPALA、Podracer など、この領域の代表的な成果は Cloud TPU を使用した開発で得られたものです。
「...大規模な強化学習システムのコンピューティング要件は、Cloud TPU、なかでも、複数の TPU デバイスを低レイテンシのコミュニケーション チャネルで相互接続した Google データセンター内の特別な構成である TPU Pod の利用に特に適していると考えます。」- Podracer、DeepMind
TensorFlow 向けカスタム オペレーション サポート
TPU VM での直接実行により、ユーザーは TensorFlow テキストのような独自のカスタム オペレーションを構築できるようになりました。この機能により、ユーザーは TensorFlow ランタイムのリリース バージョンに縛られることがなくなります。
お客様の声
「ここ数年、Kakao Brain は minDALL-E、KoGPT、直近では RQ-Transformer を含む数多くの画期的な AI サービスやモデルを開発してきました。当社では、Google Cloud での早期リリース以来 TPU VM アーキテクチャを使用しており、当初の TPU ノードのセットアップと比較してパフォーマンスに大きな改善を目にしています。TPU VM の一般提供版で追加された Embedding API などの新機能についても非常に楽しみにしており、引き続き TPU を使用し、ライフスタイルを変える AI 技術によって実現されるソリューションでいくつかの世界最大の『思いも寄らない問題』を解決していく予定です。」- Kim Il-doo 氏 Kakao Brain 社 CEO
その他のお客様の声も、こちらからご覧いただけます。
ご利用方法
TPU VM の利用を開始するには、クイック スタートまたはチュートリアルのいずれかを実施します。TPU を初めて使用する方は、コンセプト ディープダイブやシステム アーキテクチャをご覧ください。Google の先進的な AI インフラストラクチャである Cloud TPU を普遍的に有用かつアクセス可能にするべく、引き続き取り組んでまいります。
- Cloud TPU アウトバウンド プロダクト マネージャー Vaibhav Singh
- Cloud TPU プロダクト マネージャー Max Sapoznikov


{kind=link}