Google、最新の MLPerf ベンチマークで最高水準のパフォーマンスを発揮
Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
MLPerf ベンチマーク結果の最新ラウンドがリリースされ、Google の TPU v4 スーパーコンピュータが前例のないパフォーマンスを大規模に実証しました。これは時期にかなったマイルストーンです。というのは、大規模な機械学習トレーニングによって AI の最近のブレークスルーの多くが可能になり、最新のモデルには数十億から数兆ものパラメータ(T5、Meena、GShard、Switch Transformer、GPT-3)が含まれるためです。
Google の TPU v4 Pod は、広範なトレーニング要件などを満たすように設計されています。TPU v4 Pod は、TensorFlow と JAX を使用して Google が提出した MLPerf ベンチマークの 6 つのうち 4 つでパフォーマンス記録を塗り替えました。各スコアは昨年記録を更新した提出値を大幅に上回っており、Google が世界最速級の機械学習スーパーコンピュータを備えていることが再び明らかになりました。TPU v4 Pod は、社内の機械学習ワークロードに合わせて Google データセンター全体にすでに広くデプロイされており、年内に Google Cloud 経由で利用できるようになります。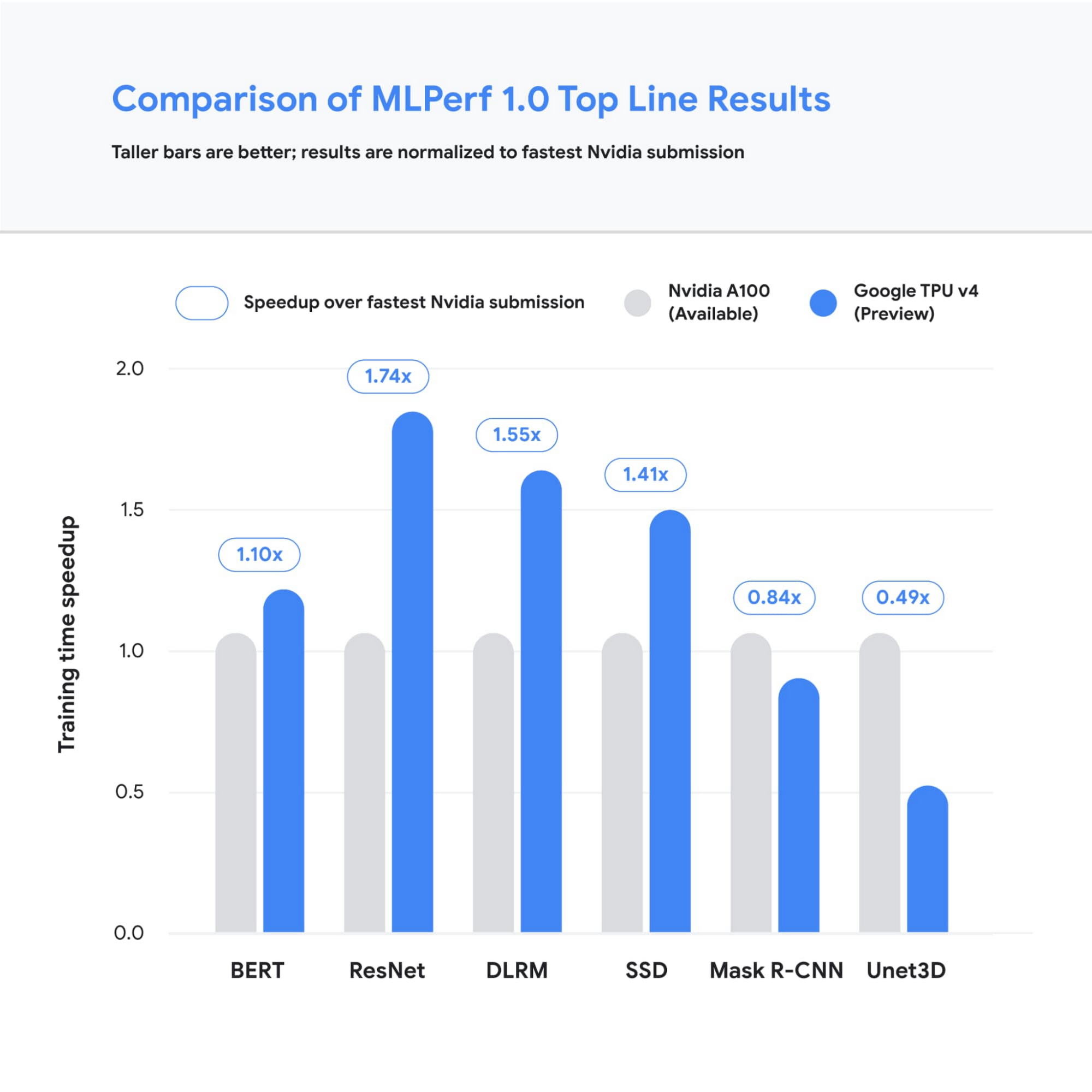
図 1: トレーニングのパフォーマンスを調べる MLPerf v1.0 TPU v4 のすべてのカテゴリで、Google の最速の提出値が、Google 以外の最速の提出値を上回りました。この場合のベースライン提出値はすべて NVIDIA から取得されたものです。比較に使用される値は、システムのサイズに関係なく、合計トレーニング時間で正規化されています。棒グラフが高いほど、パフォーマンスが優れていることを示します。1
では、上述の画期的な結果をもたらした一部のイノベーションと、Google 内外の大規模モデル トレーニングへの影響について詳しく見ていきましょう。
Google は引き続き優れたパフォーマンスを記録
最新の MLPerf に対する Google の提出値は、高水準の優れたパフォーマンス(目標品質の達成時間が最短)を示し、4 つのベンチマークでパフォーマンスの新記録を樹立しました。こうした成果を達成できたのは、複数のベンチマーク用に数百の CPU ホストを用意し、次世代 TPU v4 ASIC を 3,456 までスケールアップしたことによります。Google の最高提出値は昨年の結果と比較して平均 1.7 倍向上しました。つまり、最も一般的な機械学習モデルのいくつかを数秒でトレーニングできるようになりました。
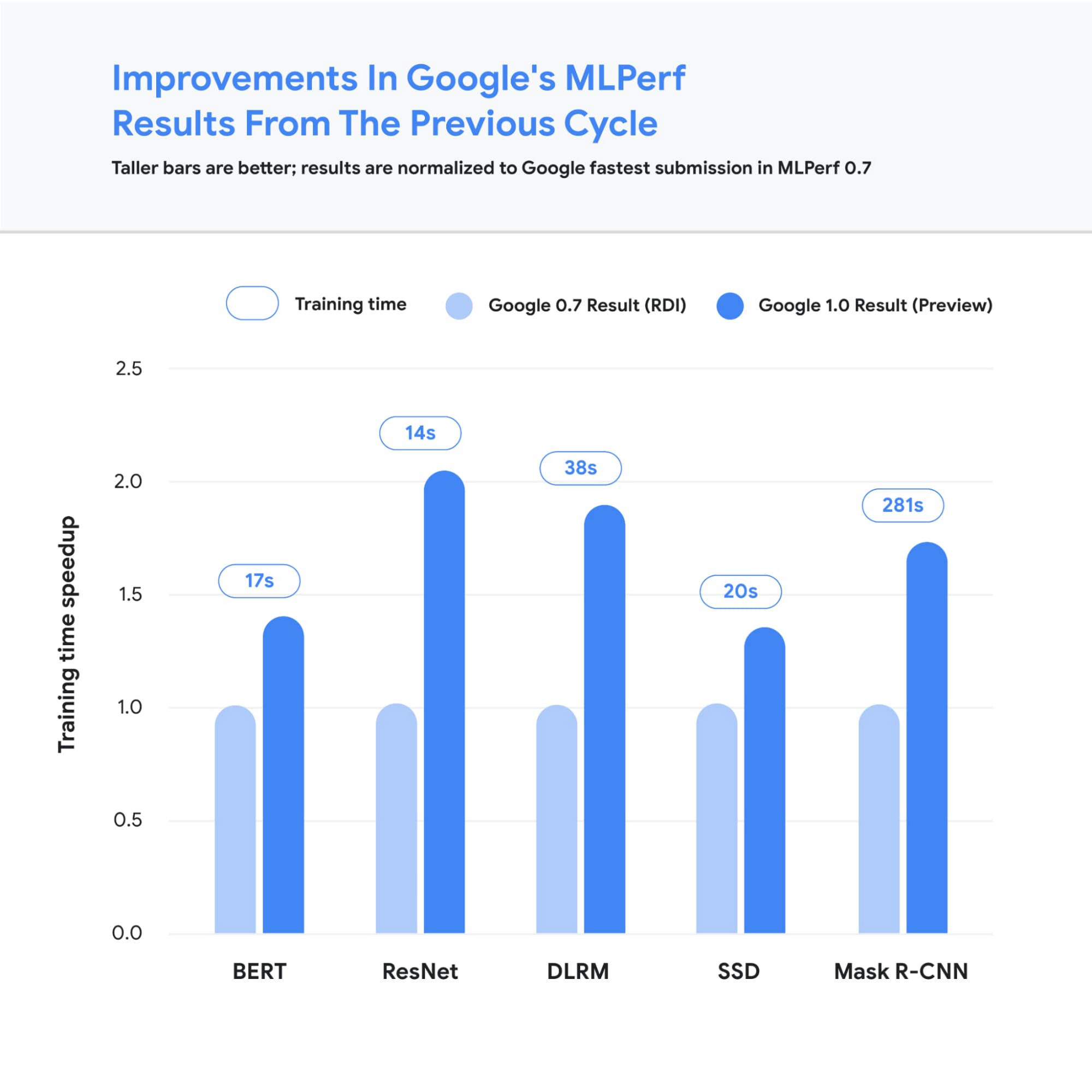
図 2: トレーニングの高速化を調べる MLPerf v1.0 TPU v4 の Google の提出値は MLPerf v0.7 TPU v3 を上回っています(ただし、MLPerf v0.7 の DLRM 結果は TPUv4 を使用して取得されました)。比較に使用される値は、システムのサイズに関係なく、合計トレーニング時間で正規化されています。棒グラフが高いほど、パフォーマンスが優れていることを示します。Unet3D は MLPerf v1.0 の新しいベンチマークであるため、表示されていません。2
このようなパフォーマンスの向上は、ハードウェア スタックとソフトウェア スタックの両方への継続的な投資により達成されました。高速化の一部は、Google の第 4 世代 TPU ASIC の使用によるものです。この TPU ASIC により、前世代の TPU v3 よりも未加工の処理能力が大幅に向上します。4,096 個の TPU v4 チップが相互にネットワーク接続されて TPU v4 Pod が作成され、各ポッドは 1.1 エクサフロップ/秒のピーク パフォーマンスを提供します。
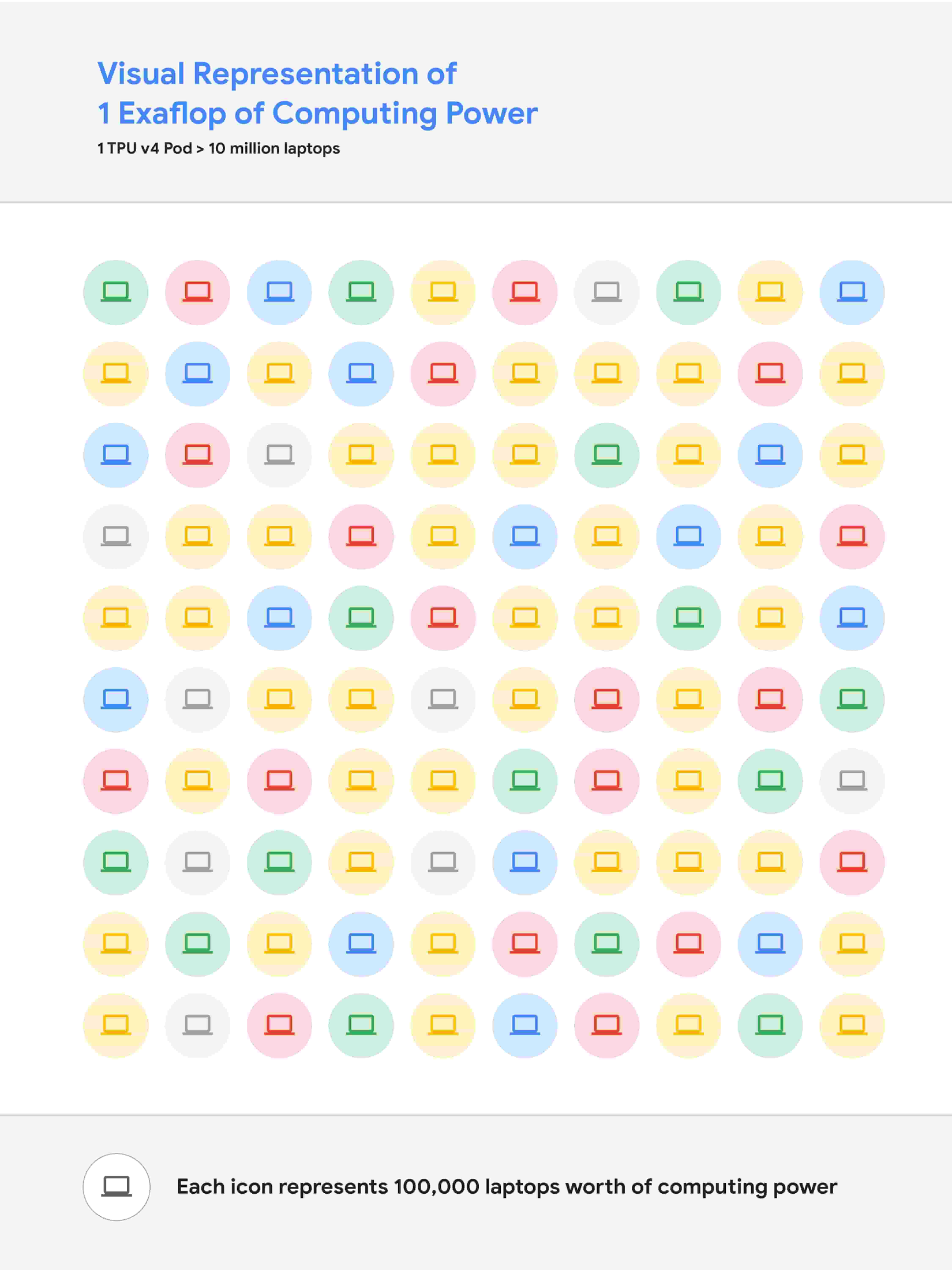
図 3: 1 エクサフロップ/秒の演算能力を視覚的に表したもの。1,000 万台のノートパソコンを同時に実行し、それらすべての演算能力を合わせると、1 エクサフロップ/秒の演算能力とほぼ同等になります。
並行して XLA コンパイラに多数の新機能を導入することで、TPU v4 で実行される ML モデルのパフォーマンスが向上しました。こうした機能の一つにより、共有の均一メモリアクセス システムを使用して、2 個(場合によっては 2 個以上)の TPU コアを単一の論理デバイスとして操作できます。このメモリ空間の統合により、コアで入力データと出力データを簡単に共有できるため、コア全体でよりパフォーマンスの高い処理を割り当てることが可能です。もう一つの機能は、演算と通信のきめ細かいオーバーラップによってパフォーマンスを向上させます。最後に、空間ディメンションが別のバッチ ディメンションに変換されるように、畳み込み演算を自動的に変換する手法を導入しました。この手法により、大規模で一般的な低いバッチサイズでのパフォーマンスが向上します。
カーボンフリー エネルギーで大規模モデル研究を実現
高水準の MLPerf ベンチマークの差異はわずか数秒で測定できますが、これは数十億から数兆のパラメータを含む最先端のモデルによる何日分ものトレーニングの時間に相当します。たとえば、現在では 2048 個の TPU コアで GSPMD を使用して 4 兆個のパラメータの高密度 Transformer をトレーニングできます。これは昨年 OpenAI によって公開された GPT-3 モデルの 20 倍以上です。すでに Google 内で TPU v4 Pod を広く使用しており、MUM や LaMDA など研究のブレークスルーを開発し、Google 検索、アシスタント、翻訳などの主要プロダクトを改良しています。TPU によるトレーニング時間が短縮されると、効率が高まり、研究開発の速度が向上します。こうした TPU v4 Pod の多くは、90% またはそれに近いカーボンフリー エネルギーで動作します。さらに、クラウド データセンターは通常のデータセンターに比べて約 1.4~2 倍エネルギー効率が高く、内部で実行される ML 指向のアクセラレータ(TPU など)は市販システムに比べて約 2~5 倍効果的です。
また、Google Cloud で TPU v4 Pod を間もなく提供する予定です。これにより、世界中のお客様が世界最速級の機械学習トレーニング スーパーコンピュータを利用できるようになります。Cloud TPU は TensorFlow、PyTorch、Jax などの主要なフレームワークをサポートします。さらに、TPU ホストマシンに直接アクセスできるまったく新しい Cloud TPU システム アーキテクチャを最近リリースし、ユーザー エクスペリエンスが大幅に向上しました。
詳細を確認する
Cloud TPU v4 Pod の早期アクセスのリクエストについては、Google Cloud 営業担当者にお問い合わせください。お客様がエクサフロップの TPU 演算能力をご利用になり、機械学習の可能性を広げられることを願っています。
1. すべての結果情報は、2021 年 6 月 30 日に www.mlperf.org から取得されたものです。MLPerf の名称とロゴは商標です。詳しくは www.mlperf.org をご参照ください。グラフは次の結果を使用: 1.0-1067、1.0-1070、1.0-1071、1.0-1072、1.0-1073、1.0-1074、1.0-1075、1.0-1076、1.0-1077、1.0-1088、1.0-1089、1.0-1090、1.0-1091、1.0-1092。
2. すべての結果情報は、2021 年 6 月 30 日に www.mlperf.org から取得されたものです。MLPerf の名称とロゴは商標です。詳しくは www.mlperf.org をご参照ください。グラフは次の結果を使用: 0.7-65、0.7-66、0.7-67、1.0-1088、1.0-1090、1.0-1091、1.0-1092。
-ソフトウェア エンジニア Tao Wang
-プロダクト マネージャー Aarush Selvan




