初心者向けガイド: やさしい機械学習
Google Cloud Japan Team
※この投稿は米国時間 2020 年 9 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
AI を活用したアプリの構築は大変な場合があります。私がさまざまな苦労に耐えてきたのは、AI の使用によるメリットには苦しむだけの価値があることが多いからです。よく言われるように、努力は無駄にならないのです。
幸いにも、使いやすいツールのおかげで、この 5 年間で機械学習を使用した開発ははるかに簡単になりました。最近では、機械学習モデルの構築と調整にはほとんど時間をかけず、従来のアプリ開発に多くの時間をあてています。
この投稿では、簡単に使えるお気に入りの Google Cloud AI ツールをいくつかご紹介し、AI を活用したアプリをすばやく構築するためのヒントをお届けします。では早速始めましょう。
事前トレーニング済みモデルを使用する
機械学習プロジェクトで特に面倒で時間がかかる部分として、ラベル付けしたトレーニング データ(機械学習アルゴリズムが「学習」できるラベル付きサンプル)の収集が挙げられます。
ただし、多くの一般的なユースケースでは、その手間は必要ありません。独自のモデルをゼロから構築する代わりに、誰かが構築、調整、保守している事前トレーニング済みモデルを利用できます。その一例が Google Cloud の AI API です。
Cloud AI API では、次のような目的で機械学習を使用できます。
- 音声ファイルや動画ファイルの音声文字変換
- ドキュメントのテキスト読み取り
- フォームや請求書などの構造化ドキュメントの解析
- 画像からの顔、感情、オブジェクトの検出
- 画像や動画の不適切なコンテンツの検出
- その他多数
こうした API を利用した機械学習モデルは、多くの Google アプリ(Google フォトなど)で使用されているものと似ています。大量のデータセットでトレーニングされていて、多くの場合、非常に正確です。たとえば、Video Intelligence API を使用して自分の家族の動画を分析したところ、「ブライダル シャワー」、「結婚式」、「野球」、さらには「赤ちゃんの笑顔」といった具体的なラベルを検出できました。
Cloud AI API はクラウドで実行されます。無料のオフライン ソリューションが必要な場合は、TensorFlow.js と ML Kit が提供している、ブラウザやモバイル デバイスで直接実行できる事前トレーニング済みモデルのホストを利用できます。TensorFlow Hub には、事前トレーニング済みの TensorFlow モデルがさらに豊富に用意されています。
AutoML を使用した簡単なカスタムモデル
さまざまなユースケースに合う事前トレーニング済みモデルが揃っていますが、カスタマイズしたモデルを構築する必要があることもあります。たとえば、X 線などの医療スキャンを解析して疾患の存在を検出するモデルを構築したり、組み立てラインで装置からウィジェットをソートしたりする場合があるでしょう。あるいは、カタログが届いたときに購入する可能性が特に高いお客様を予測する場合があるかもしれません。
そのような場合には、カスタムモデルを作成する必要があります。このプロセスを可能な限り簡単にする Google Cloud AI ツールが AutoML です。これにより、独自のデータでカスタムモデルをトレーニングでき、そのためのコードを記述する必要もありません(必要な場合を除く)。
以下の GIF は、回路基板上で動作しないコンポーネントを検出するモデルをトレーニングするために AutoML Vision を使用した方法を示しています。データにラベルを追加するインターフェースはクリック&ドラッグであり、[新しいモデルをトレーニング] ボタンをクリックするだけで簡単にモデルをトレーニングすることができます。モデルのトレーニングが完了したら、[評価] タブでモデルの品質を評価し、誤りのある場所を確認できます。
これは、データベースやスプレッドシートにあるような画像(AutoML Vision)、動画(AutoML Video)、言語(AutoML Natural Language と AutoML Translation)、ドキュメント、表形式データ(AutoML Tables)で動作します。
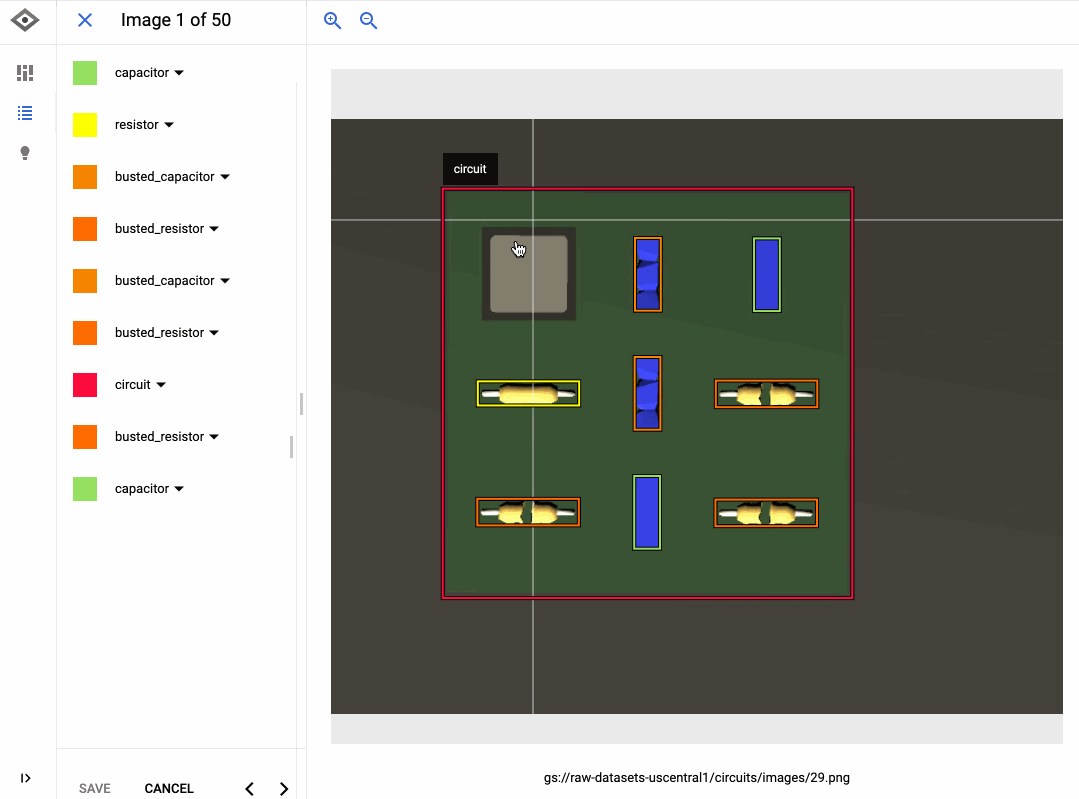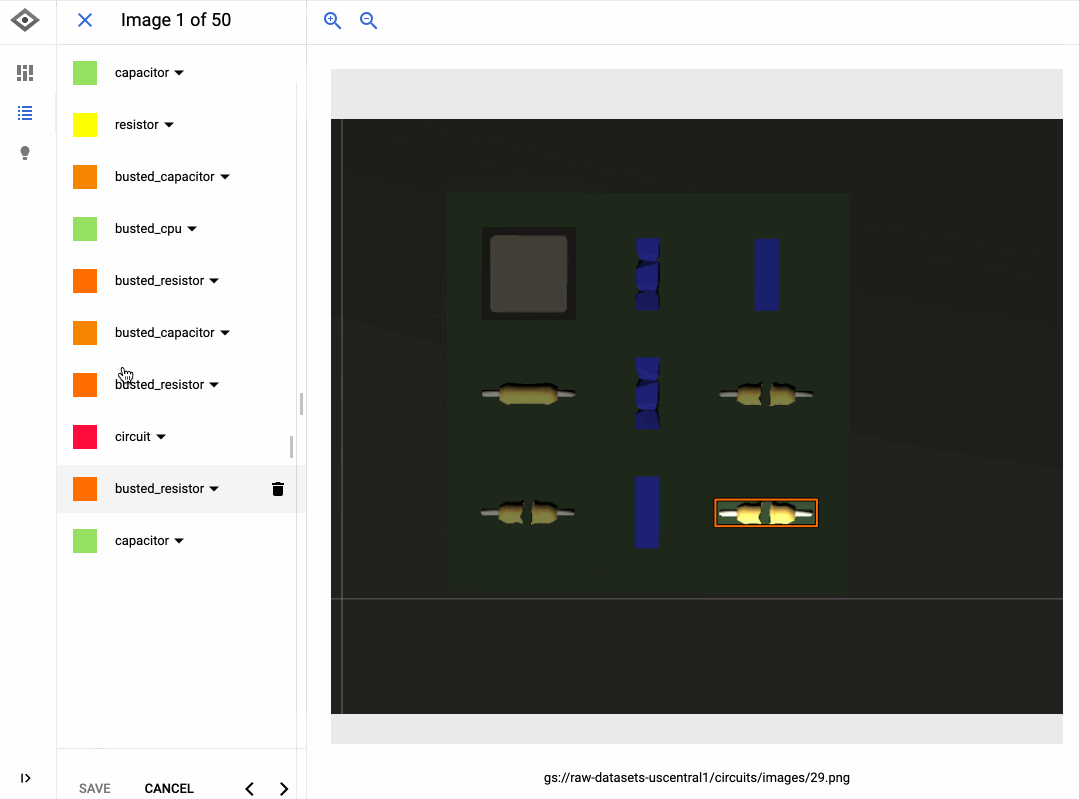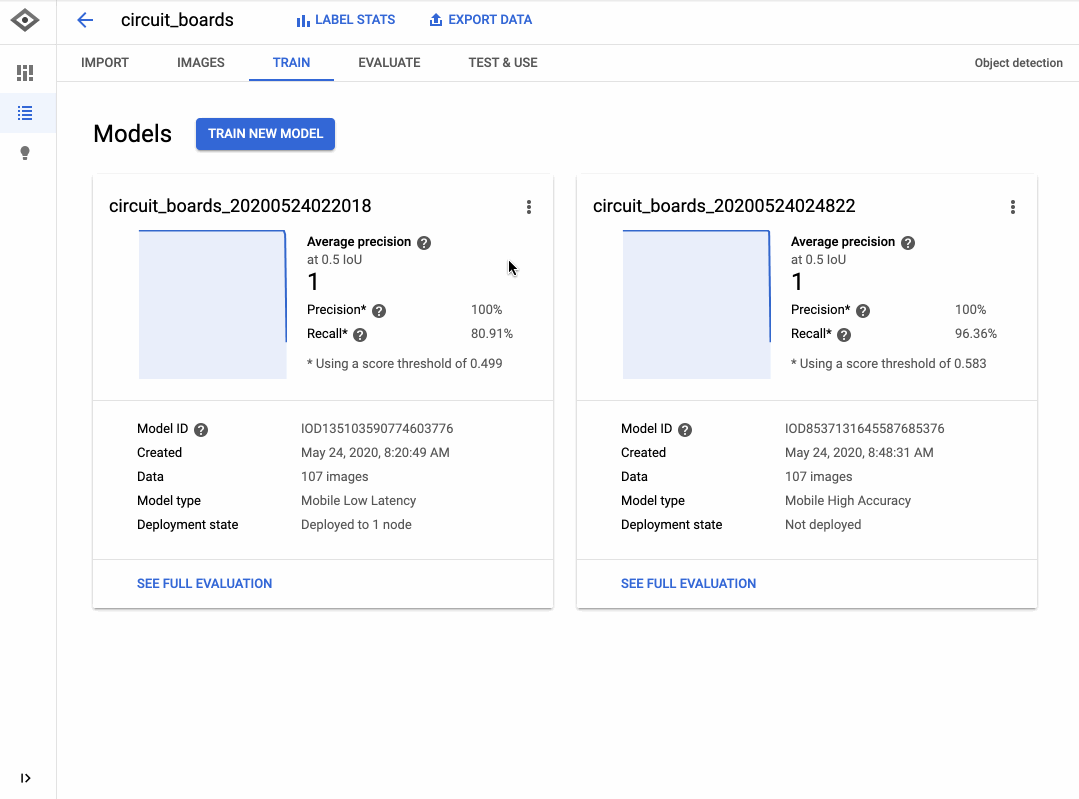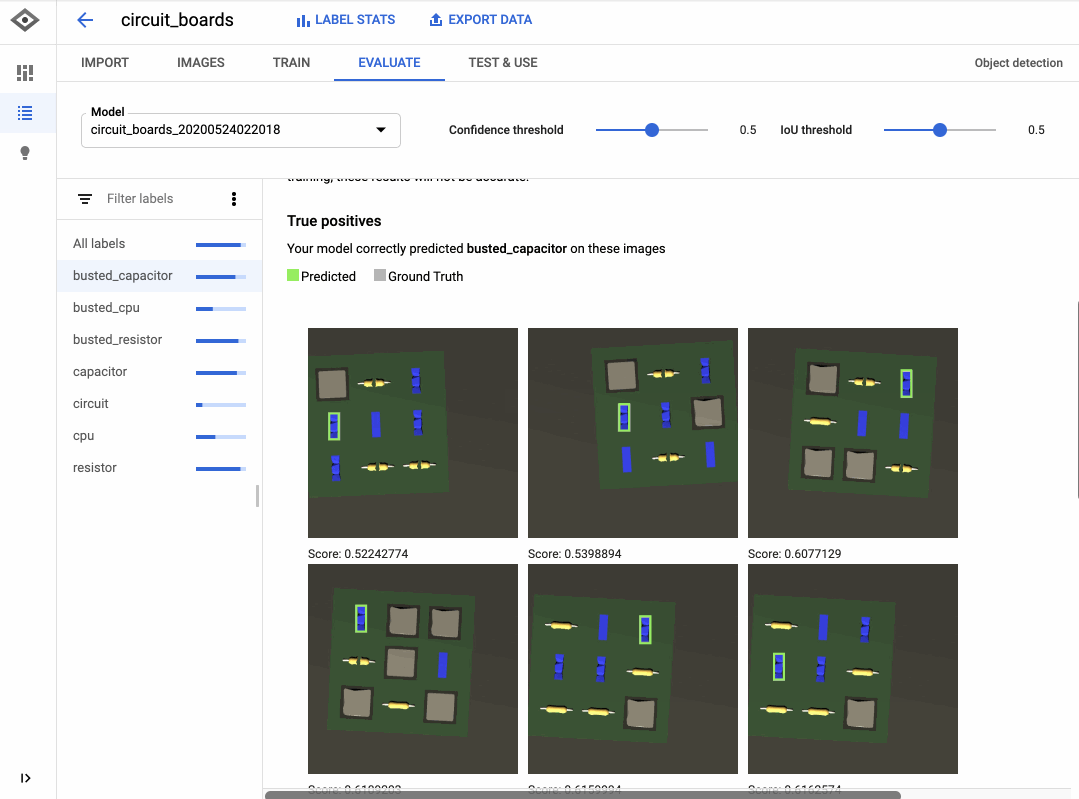
AutoML インターフェースはシンプルですが、生成されるモデルはたいてい非常に高品質です。AutoML は内部で各種モデル(ニューラル ネットワークなど)をトレーニングし、さまざまなアーキテクチャとパラメータを比較して、最も正確な組み合わせを選択します。
アプリで AutoML モデルを使用するのは簡単です。Google によってモデルをクラウドでホストし、標準の REST API やクライアント ライブラリ(Python、Go、Node、Java など)からアクセスできるようにするか、モデルを TensorFlow にエクスポートしてオフラインで利用可能にすることができます。
そのため、程度の差はありますがモデルのトレーニングが楽になります。では、大きなトレーニング データセットはどこから取得すればよいでしょうか?
独自データのラベル付けは不要
冗談を言っているのではありません。
ML プロジェクトを開始する際は、まず必要な処理を実行する事前トレーニング済みモデルがすでに存在するかどうかを確認します。
それが存在しない場合は、データセットがすでに存在するかどうかを確認します。データセットのホスティングおよびコンペサイトである Kaggle には、考えられるほぼすべての種類のデータセットが存在します。COVID-19(新型コロナウイルス感染症)に関するツイートから、メキシコ料理チェーン店の所在地リストやフェイク ニュース記事のコレクションまで、少なくとも一部のデータセットを Kaggle で見つけ、問題の概念実証モデルをトレーニングできます。また、Google データセット検索も役立つツールで、Kaggle と他のソースにクエリを実行するデータセットが見つかります。
もちろん、独自データにラベル付けが必要になることもあります。とはいえ、何百人ものインターンを雇う前に、Google の Data Labeling Service の使用をご検討ください。このツールを使用するには、データにラベルを付ける方法を説明し、Google がそのデータをラベリング担当者のチームに送信します。生成されるラベル付きデータセットは、AutoML や他の AI Platform モデルに直接接続してトレーニングできます。
モデルを、使用可能なアプリへ
多くの場合、機能する機械学習モデルの構築(または検索)は、プロジェクトにおいて難しい部分ではありません。難しいのは、そのモデルを、チームの他のメンバーが自分のデータで利用できるようにすることです。この問題が Google Cloud AI で頻繁に発生したため、API のプロダクト ページに対話型のデモを追加し、API をアップロードしてすぐに試せるようにしました。
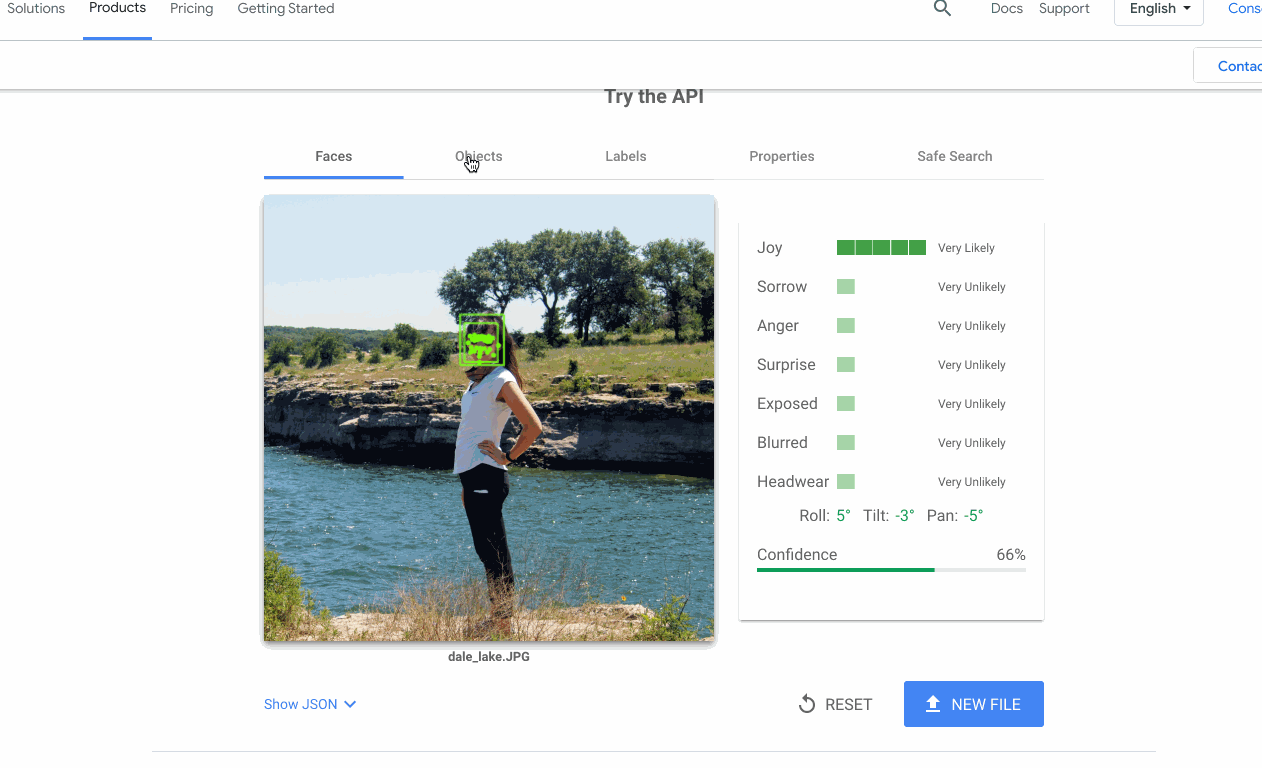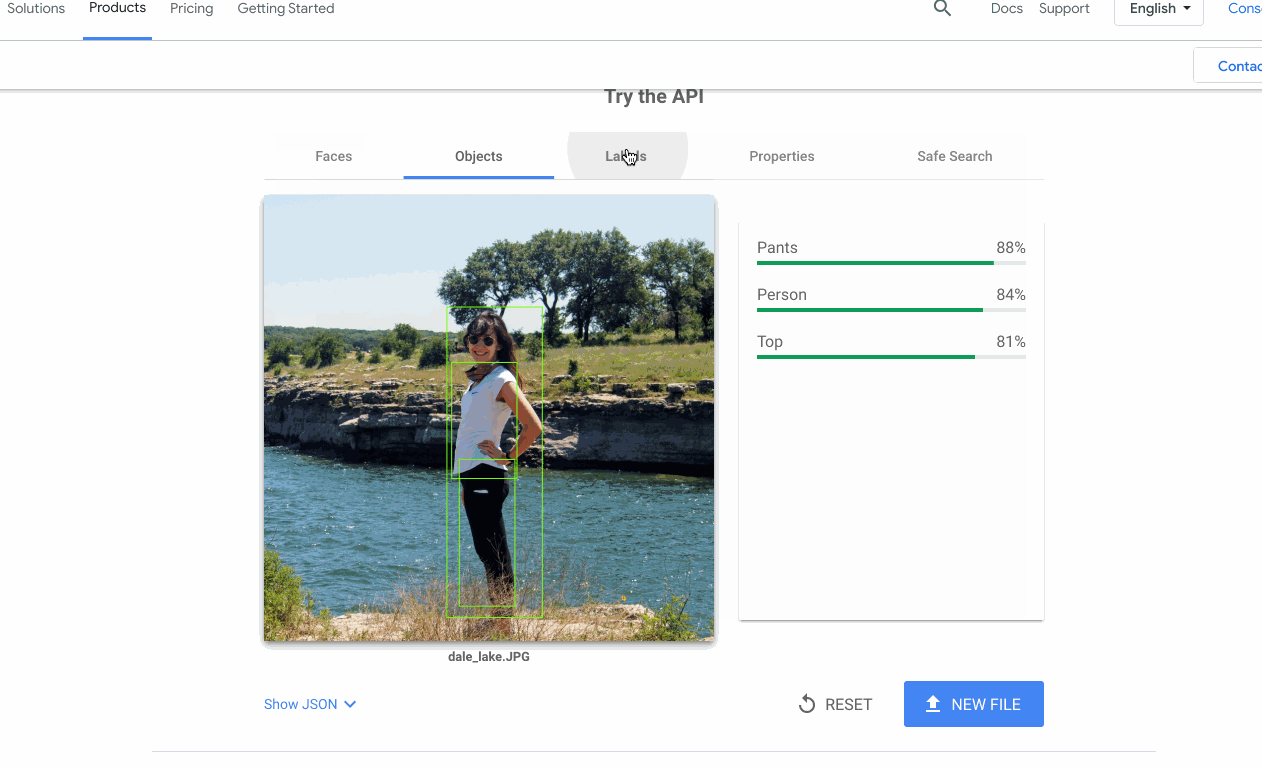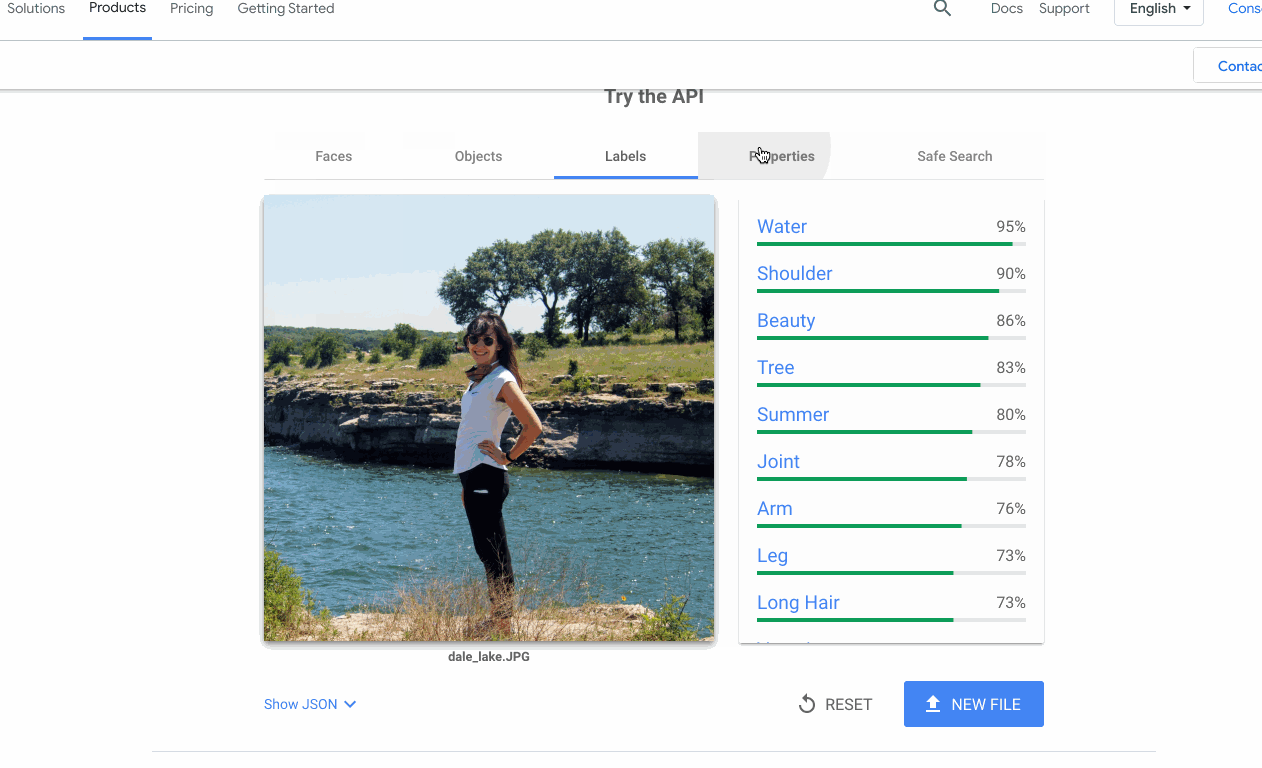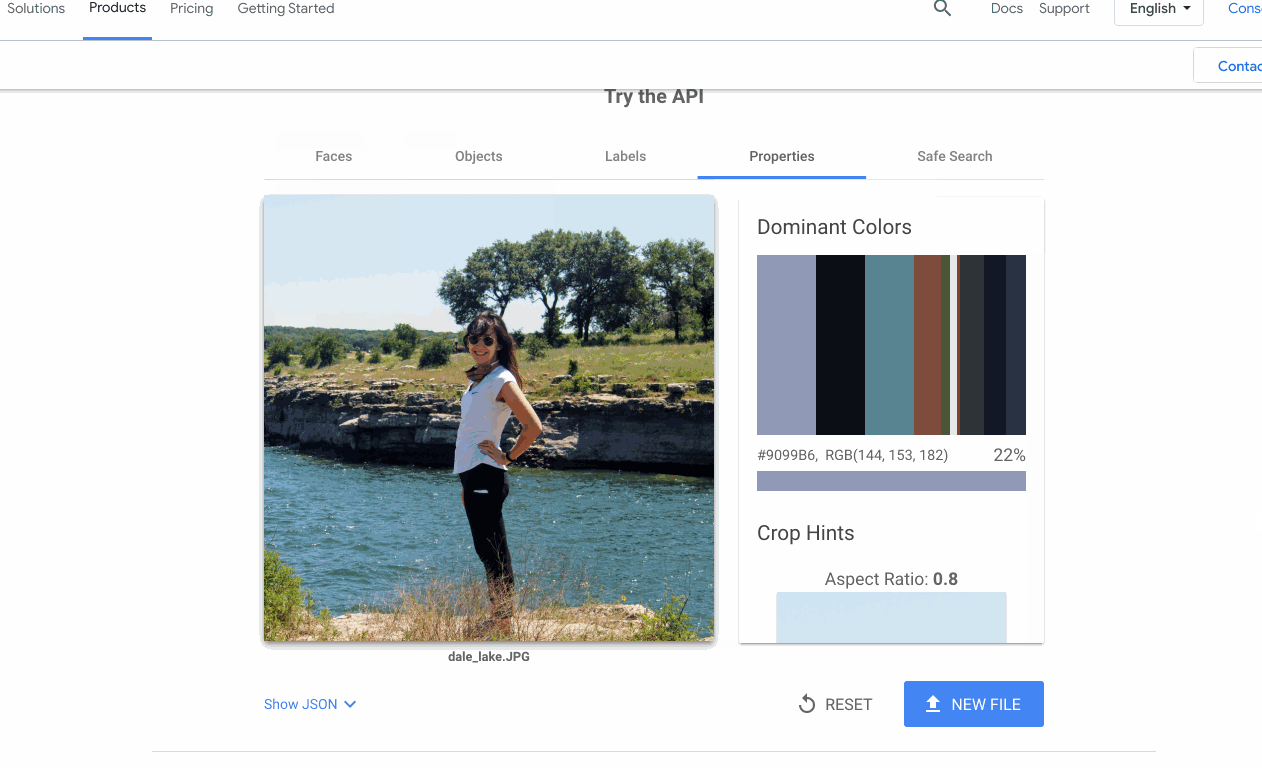
多くの場合、機械学習プロジェクトを成功させることは、プロトタイプをすばやく作成できることに通じます。このために、以下に示す主要なツールやアーキテクチャをいくつか使用しています。
- Google スプレッドシートへの ML の追加。*スプレッドシート、ドキュメント、フォームなどの G Suite アプリは、Apps Script フレームワークを使用して JavaScript で簡単に拡張することが可能です。たとえば、Google スプレッドシートに行を追加するたびに実行されるテキスト分類モデルを構築できます。または、画像をアップロードして ML モデルで分析し、結果を Google スプレッドシートに書き込むことができる Google フォームを作成することもできます。
- Google Cloud Storage と Cloud Functions の組み合わせ。大半の ML プロジェクトはデータイン、データアウトです。入力データ(画像、動画、音声録音、テキスト スニペットなど)をアップロードすると、それに対してモデルが予測を実行します(「出力データ」)。このようなプロジェクトをプロトタイプ化する良い方法は、Cloud Storage と Cloud Functions を使用することです。Cloud Storage はクラウド内のフォルダのようなもので、すべての形式のデータが保存される場所です。Cloud Functions はクラウドでコードのブロックを実行するためのツールで、専用サーバーは必要ありません。クラウド ストレージにアップロードされたファイルにクラウド機能を「トリガー」して実行させることで、2 つが連携するように構成できます。
- 最近では、Document AI パイプラインを構築する際にこの設定を使用しました。
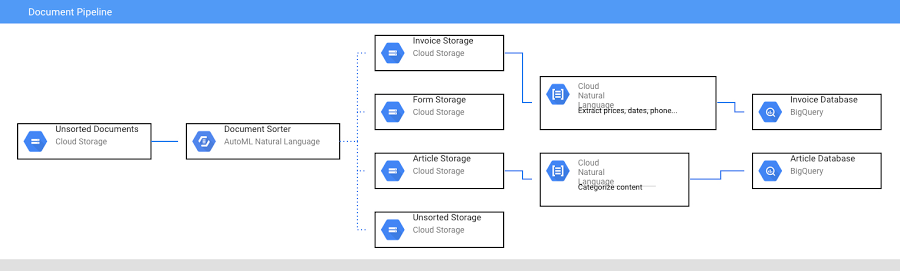
ドキュメントをクラウド ストレージ バケットにアップロードすると、クラウド関数がトリガーされ、ドキュメントがタイプ別に分析されて、新しいバケットに移動されます。これによって新しいクラウド関数がトリガーされ、Natural Language API を使用してドキュメント テキストが分析されます。完全なコードについては、こちらをご覧ください。
次のステップ
機械学習の利用開始は簡単だと思っていただけたら幸いです。機械学習の利用を開始する際に役立つチュートリアルやデモをいくつかご紹介します。
- ソフトウェア デベロッパー: 機械学習を逆さまに学ぶ
- 議会の法案を機械学習で分類する | Sara Robinson
- Cloud Vision API について調べてみる。機械学習に興味はあるけど… | Sara Robinson
- ML を使用した作成に関する YouTube 動画シリーズ(僭越ながら私がご説明します)
- Yufeng Guo による Cloud AI アドベンチャー
- Introduction to TensorFlow for Artificial Intelligence, Machine Learning, and Deep Learning
-AI 応用エンジニア Dale Markowitz




{kind=link}