Google Cloud で独自の限定公開のナレッジグラフを構築する
Google Cloud Japan Team
※この投稿は米国時間 2023 年 2 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
ナレッジグラフは、複数のソースからデータを取り込み、エンティティ(人、組織、場所、物など)を抽出して、姓名、住所、ID などの一般的な属性によって、エンティティ間の関係(所有者、関連ありなど)を確立します。
エンティティはグラフのノードを形成し、エッジ(接続部)は関係があることを表します。このグラフを構築することは、データ アナリストやソフトウェア開発者にとって、エンティティ リンクの確立やデータ検証のための貴重なステップとなっています。
「ナレッジグラフ」という言葉は、新しい検索機能の一部として 2012 年に Google が初めて導入しました。他の上位結果やデータソースから事前に収集したデータを基に、回答のサマリーをユーザーに提供します。
ナレッジグラフのメリット
データのナレッジグラフを構築することには、次のような複数のメリットがあります。
「ダ ヴィンチ」「レオナルド ダ ヴィンチ」「L ダ ヴィンチ」「レオナルド ディ セル ピエーロ ダ ヴィンチ」など、1 つのエンティティとして識別されるテキストをまとめることができる。
「モナリザの画家」のように、この特定のエンティティに属性や関係を追加できる。
類似性に基づいてエンティティをグループ化できる。たとえば、ダ ヴィンチとミケランジェロは 2 人とも 15 世紀後半に活躍した著名な芸術家なので、同じグループに分類します。
また、ナレッジグラフは、ユーザーがエンティティ間の隠れたパターンやつながりを発見するのに役立つ、信頼できる唯一の情報源にもなります。従来のリレーショナル データベースでは、このようなつながりを特定することは難しいうえ、計算量の多い作業となっていました。
ナレッジグラフは、以下を含み、ただしこれらに限定されない、さまざまなユースケースで広くデプロイされています。
サプライチェーン: サプライヤー、製品部品、配送などをマッピングする。
融資: 不動産業者、借り主、保険会社などを関連付ける。
顧客管理: マネーロンダリング防止、身元確認などを行う。
Google Cloud へのデプロイ
Google Cloud に、2 つの新しいサービスが導入されました(現時点ではいずれもプレビュー版です)。
Entity Reconciliation API は、お客様が BigQuery に格納されたデータを使用して、独自の限定公開のナレッジグラフを構築できるようにします。
Google Knowledge Graph Search API は、お客様が Google ナレッジグラフからエンティティに関する情報を検索できるようにします。
これらの新しいソリューションを説明するため、Entity Reconciliation API を使って限定公開のナレッジグラフを構築し、生成された ID を使って Google Knowledge Graph Search API に照会する方法を見ていきましょう。ここでは、Google Cloud Marketplace で入手可能な zoominfo.com の小売企業向けサンプルデータを使用します(リンク 1、リンク 2)。
まず、Enterprise Knowledge Graph API を有効にして、Google Cloud コンソールから Enterprise Knowledge Graph に移動します。
Entity Reconciliation API は、エンティティである組織、ローカル ビジネス、個人の表形式レコードを数クリックで調整できます。これは、次の 3 つの簡単なステップで行われます。
調整が必要な BigQuery のデータソースを特定し、ソースごとにスキーマ マッピング ファイルを作成する。
コンソールまたは API を使用して、調整ジョブを構成、開始する。
ジョブが終了したら、結果を確認する。
ステップ 1
個々のジョブとデータソースに対してスキーマ マッピング ファイルを作成し、Enterprise Knowledge Graph によるデータの取り込み方法と schema.org を使用した共通オントロジーへのマッピング方法を通知します。このマッピング ファイルは、Google Cloud Storage のバケットに保存されます。
このデモでは、組織エンティティ タイプを選択し、BigQuery テーブルのデータベース スキーマを渡しています。必ず最新のドキュメントをご参照ください。
ステップ 2
コンソール ページには、プロジェクトで使用できる既存のエンティティ調整ジョブのリストが表示されます。
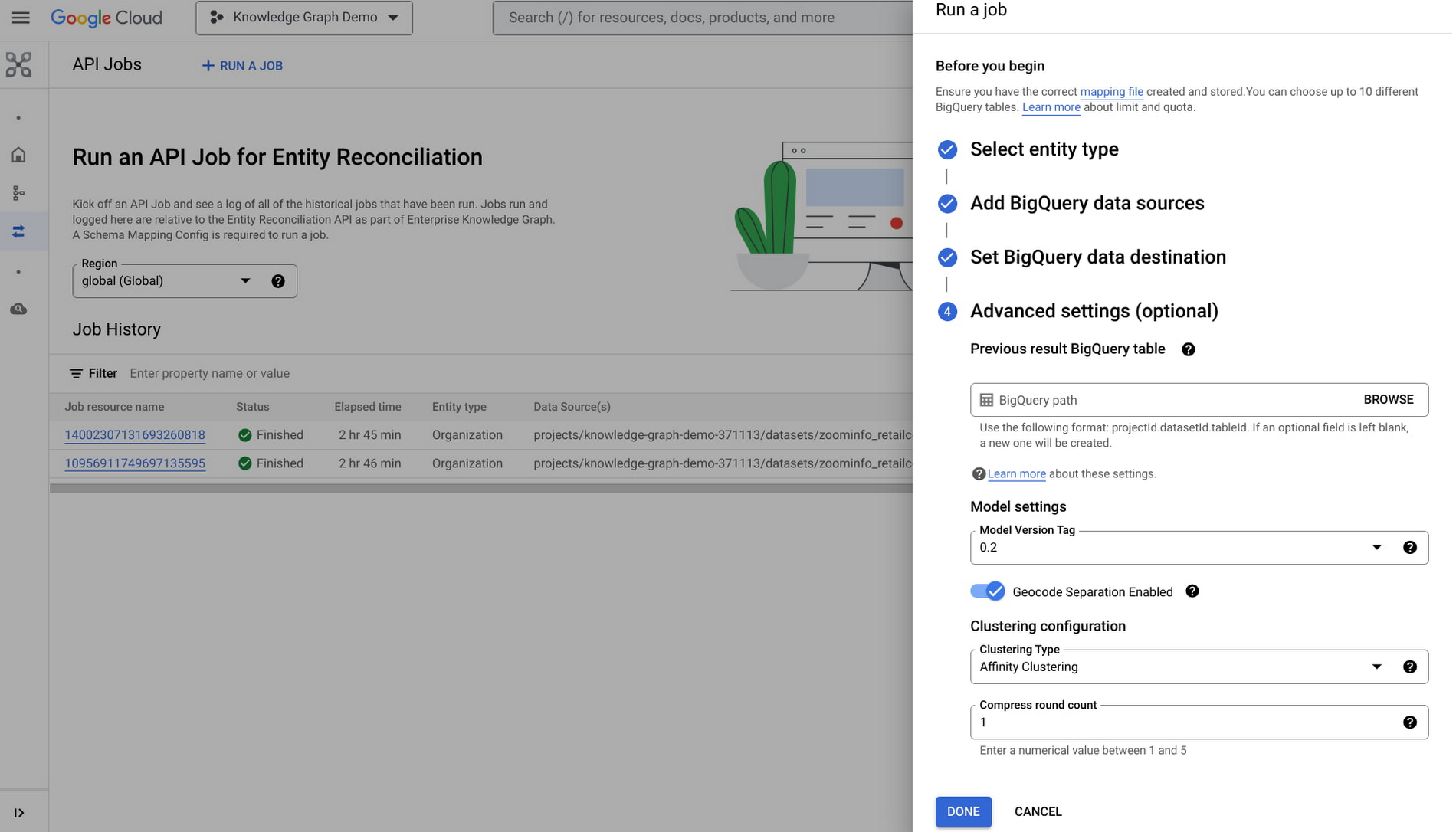
新しいジョブを作成するには、アクションバーの [RUN A JOB] ボタンをクリックし、エンティティ調整を行うエンティティ タイプを選択します。
BigQuery データソースを 1 つ以上追加し、BigQuery データセットの保存先を指定すると、保存先のデータセットの下に一意の名前を持つ新しいテーブルが EKG によって作成されます。生成されたクラスタ ID をさまざまな実行で一貫して使用できるようにするため、[Previous BigQuery result table] などの詳細設定が用意されています。
[DONE] をクリックすると、ジョブが作成されます。
ステップ 3
ジョブが完了したら、出力された BigQuery テーブルに移動し、以下のような単純な結合クエリを使用して出力を確認します。
このクエリは、出力テーブルと Entity Reconciliation API の入力テーブルを結合し、クラスタ ID で並べ替えます。調査の結果、2 つのエンティティが 1 つのクラスタにグループ化されることを確認できます。
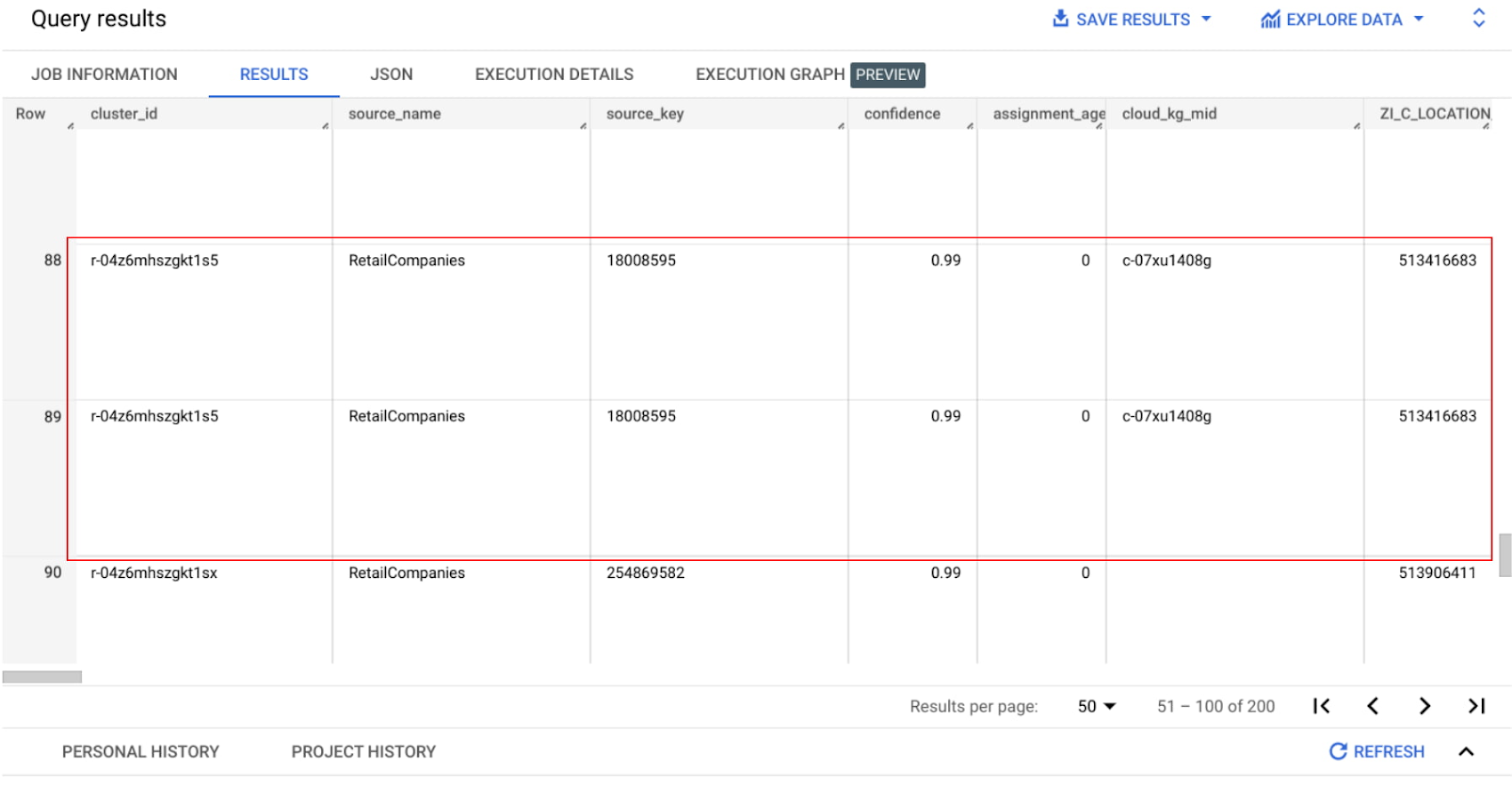
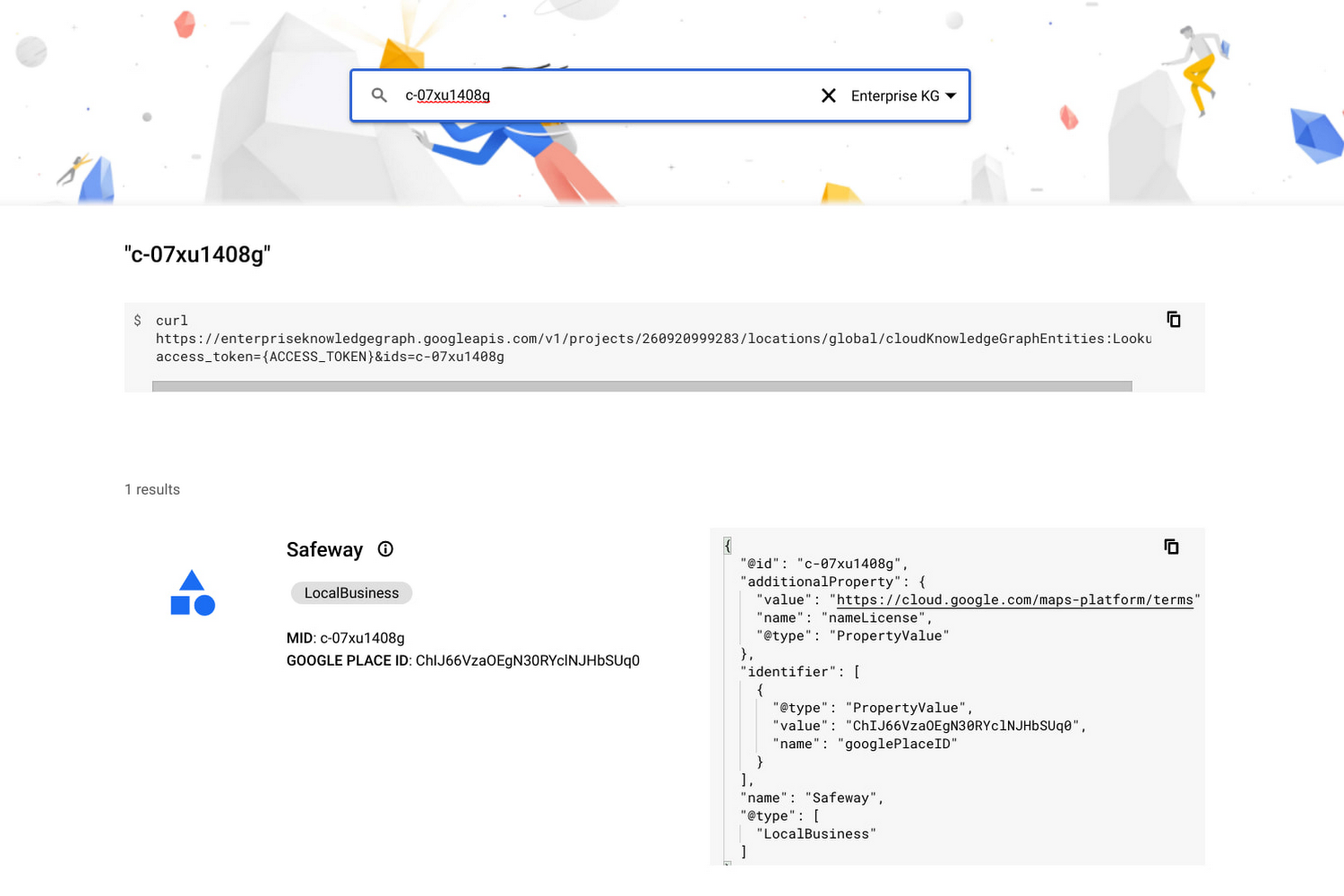
[confidence] のスコアは、これらのエンティティがこのグループに属している可能性がどの程度あるかを示します。なお、cloud_kg_mid 列は、リンクされた Google Cloud ナレッジグラフのマシン ID を返します。これは、Google Knowledge Graph Search API での検索に使用できます。