Utiliser BigQuery avec des sources de données hébergées dans Google Cloud VMware Engine

Nitish Murthy
Product Manager, Google Cloud
Wade Holmes
Solutions Manager
Essayer GCP
Les nouveaux clients peuvent explorer et évaluer Google Cloud avec des conditions exceptionnelles.
EssayerCe billet de blog s’adresse tout particulièrement aux clients qui ont redéployé leurs sources de données « on-premises », autrement dit sur site, vers Google Cloud VMware Engine. Il explique comment utiliser les services de données et d’analyse de Google Cloud avec les données hébergées sur le service managé « VMware as a Service » de Google Cloud.
Nombre de clients se déployant vers Google Cloud cherchent à tirer avantage des services avancés d’analyse proposés par Google. Si vous êtes décideur informatique ou architecte data et que vous souhaitez tirer rapidement avantage de vos données, vous trouverez dans ce billet différentes approches permettant d'accéder à vos données dans BigQuery afin de bénéficier de toute la puissance de Google Analytics, qu’il s’agisse d’analyse avancée ou de ML.
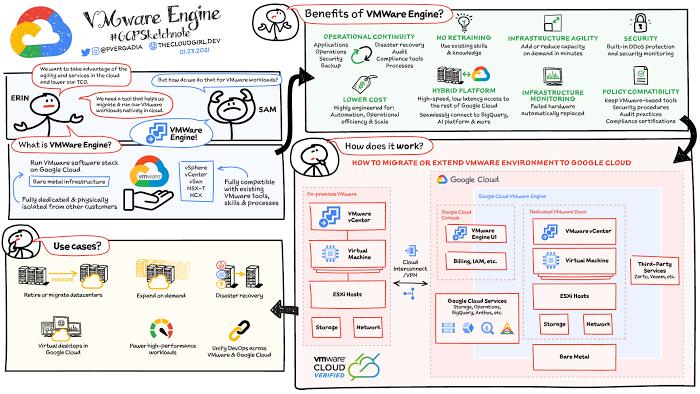
Pourquoi redéployer ses données vers Google Cloud VMware Engine ?
La donnée est au cœur des stratégies d’entreprise. Nos clients consomment, gèrent et analysent de grandes volumétries et gisements de données. Partenaire de prédilection, Google peut vous aider à gérer et comprendre vos bases existantes, sans vous imposer une réarchitecture coûteuse de vos sources et de leur emplacement.
Dans ce billet, nous vous expliquons précisément comment accéder à vos gisements pour les exploiter avec les services d’analyse de Google Cloud, sans avoir à modifier vos bases existantes. Dès que vos données auront été redéployées vers Google Cloud VMware Engine, vous pourrez optimiser les performances de vos flux en profitant de l'infrastructure hautement disponible et tolérante aux pannes de Google. Autrement dit, les solutions d’analyse cloud disponibles via BigQuery vous feront gagner un temps précieux sur l’exploitation de vos données.
Il est essentiel de réaliser qu’un tel redéploiement dans le cloud, via Google Cloud VMware Engine, profite à tous les acteurs de la chaîne data. Les DBA ou administrateurs de base de données ainsi que les responsables d’infrastructure virtuelle/ cloud peuvent continuer d’utiliser dans le cloud leurs environnements familiers, identiques à ceux qu’ils ont l’habitude d’utiliser sur site. De la même façon, l’équipe chargée de l’infrastructure peut autoriser les datas cientists et autres équipes spécialisées IA ou ML à utiliser leurs outils habituels. Mais ces derniers pourront aussi utiliser les fonctionnalités d’analyse avancée, d’IA et de ML de Google Cloud sur les données hébergées à l’origine sur site.
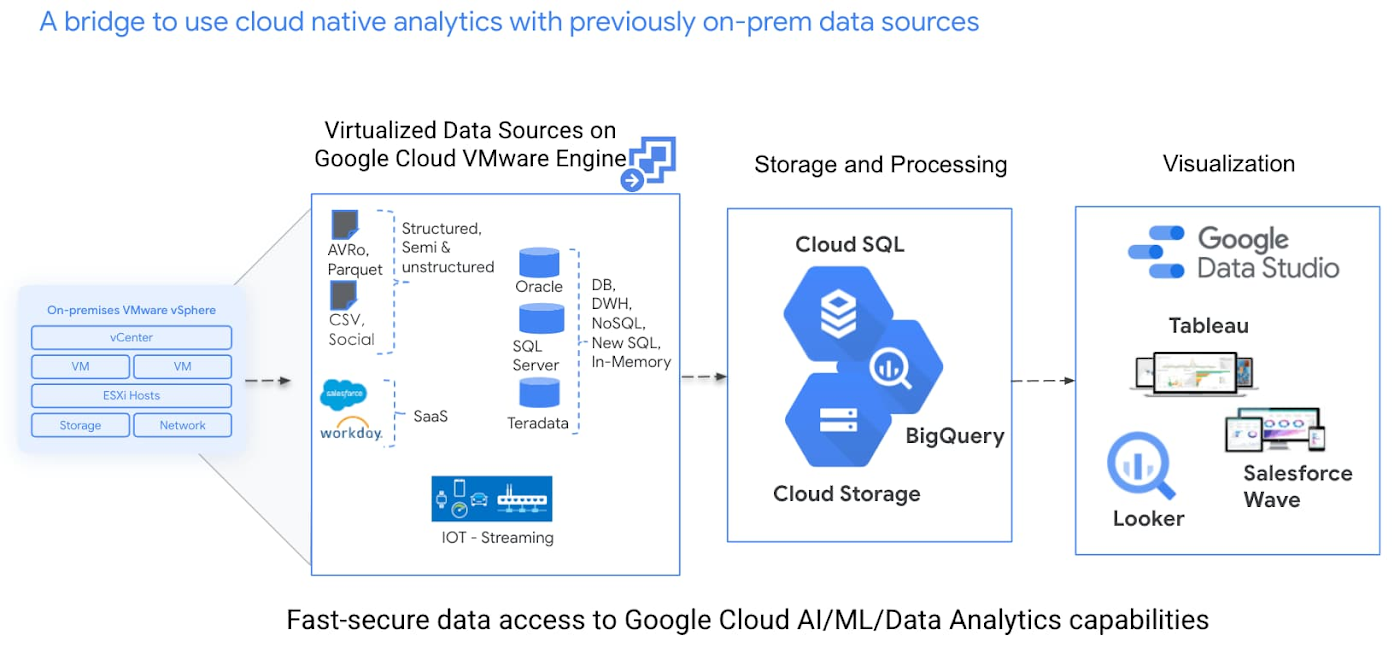
À titre d’exemple, supposons que vous cherchiez des opportunités de ventes croisées pour vos produits. Vous devrez dans un premier temps vous assurer que les données de facturation et celles relatives aux comportements d’achat sont disponibles pour analyse. L’équipe DBA identifiera ensuite les jeux de données nécessaires et l’équipe infrastructure fera en sorte de permettre un accès sécurisé à ces sources. Enfin, l’équipe chargée de la couche applicative répliquera les données dans BigQuery et utilisera des services tels que les recommandations de BigQuery ML (BigQuery ML Recommandations) pour identifier les opportunités de vente croisée.
Autre exemple : prédire l’évolution des ventes et planifier la croissance. Une fois les données de vente répliquées dans BigQuery, vous pouvez utiliser les méthodes de prévision des séries chronologiques (time-series forecasting) de Google Analytics sur vos jeux de données.
Deux approches à mettre en pratique
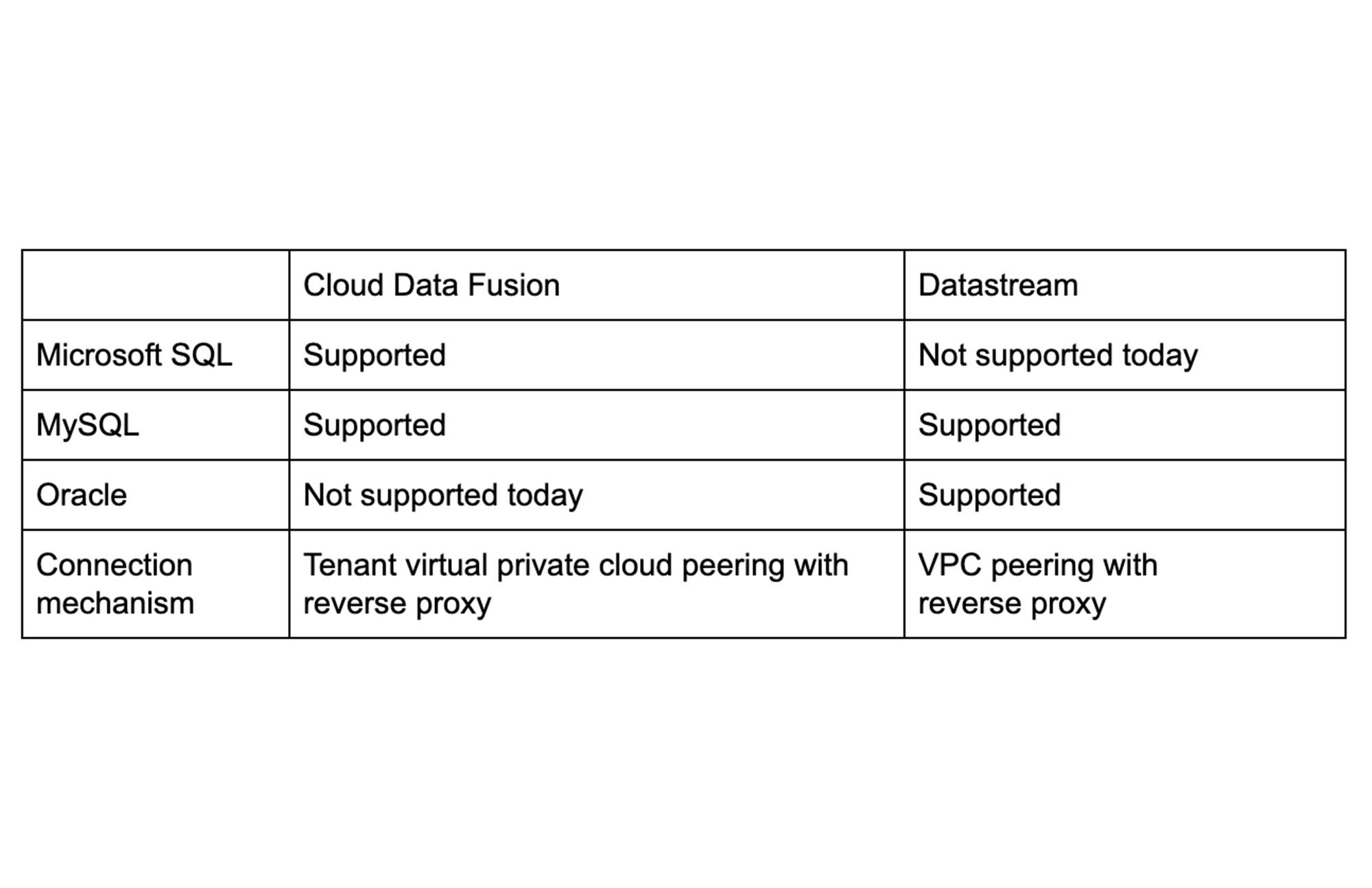
Nous vous proposons deux approches pour répliquer, de manière sécurisée et confidentielle, vos données relationnelles dans BigQuery : Google Cloud Data Fusion ou Google Cloud Datastream.
Data Fusion est un ETL qui prend en charge différents types de flux de données.
Datastream est un service de capture et de réplication des données modifiées.
Sachez que pour chacun de ces deux services, vos données restent confinées au sein de votre projet et une adresse IP interne est utilisée pour y accéder.
Nous allons ici explorer plus en détail la réplication en temps réel afin de vous permettre d’accéder en permanence à vos bases de production, qu’elles soient sous SQL Server, MySQL ou Oracle, à partir de BigQuery.
Basculer ses données internes vers le cloud tout en assurant la maintenance des flux ETL (Extract Transform Load) existants d’alimentation de vos entrepôts prend beaucoup de temps. En optant pour l’approche ELT (Extract Load Transform), vous pouvez charger directement les données dans le système cible (BigQuery, par exemple), avant d’effectuer les transformations nécessaires. De plus en plus souvent préféré au système ETL traditionnel, le processus ELT est non seulement plus simple à mettre en place mais également plus rapide, les données étant chargées plus vite.
Une fois les données hébergées dans Google Cloud, les équipes data peuvent utiliser Cloud Data Fusion et Datastream en profitant du haut débit et de la faible latence du réseau Google Cloud pour répliquer ou déplacer les données de l’infrastructure VMware vers différentes destinations cibles : buckets de stockage natifs de Google Cloud, BigQuery, etc.
Pour simplifier, nous allons partir du principe que tous les services sont consommés dans le cadre d’un même projet. Nous aborderons également les implications tarifaires, selon que l’on transfère des données à partir de Google Cloud VMware Engine, d’un site interne ou d’un autre cloud privé virtuel (VPC).
Cloud Data Fusion :
Cloud Data Fusion fournit une interface visuelle de type pointer-cliquer. Vous pouvez ainsi déployer des flux de type ETL/ELT sans écrire de code (approche No-Code). Un accélérateur de réplication permet également à Cloud Data Fusion de dupliquer directement vos tables dans BigQuery.
Pour gérer les ressources nécessaires, Cloud Data Fusion crée un projet « tenant » (une bulle d’isolation) s’appuyant sur ses propres VPCs (Virtual Private Cloud) pour maximiser la sécurité des données. Pour accéder aux sources de données hébergées dans Google Cloud VMware Engine à l’aide de Cloud Data Fusion, il nous faut utiliser un « reverse proxy » vers le VPC principal.
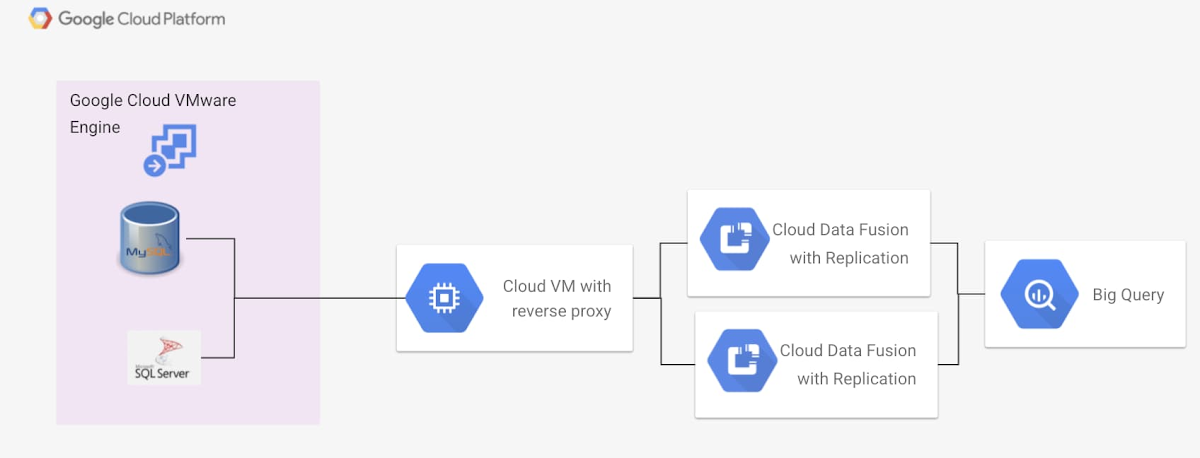
Dans ce scénario, les workloads data sont exécutés sur l’instance Google Cloud VMware Engine du projet. L'accès à l'environnement Google Cloud VMware Engine se fait via un VPC du projet couplé à Google Cloud VMware Engine. Une instance Google Compute Engine au sein de ce VPC expose un « reverse proxy » (Proxy inverse) vers la base de données de Google Cloud VMware Engine pour les services qui ne peuvent pas accéder directement à l'instance de Google Cloud VMware Engine.
Une instance Cloud Data Fusion est activée avec un accès IP privé et un appairage réseau au VPC principal de sorte qu’elle puisse accéder en toute sécurité aux données via l'instance du « Reverse Proxy ». Le processus de configuration de cet accès IP privé et de cet appairage réseau est décrit dans cette documentation.
Une fois ce couplage opéré, le connecteur Java Database Connectivity au sein de Cloud Data Fusion permet d’accéder aux bases de données, soit pour la réplication, soit pour des opérations ETL avancées. Afin de capturer les modifications de données, il faut autoriser le processus de suivi et de capture de données dans les bases hébergées sous Google Cloud VMware Engine. L'ensemble du processus de configuration et de réplication est décrit dans la documentation pour MySQL et pour SQL Server.
Google Cloud Datastream :
Datastream est un service serverless de capture et de réplication de données modifiées. Vous pouvez accéder à des flux de données en continu, à faible latence, à partir de bases de données Oracle et MySQL hébergées sur Google Cloud VMware Engine. Cette approche offre plus de flexibilité dans la gestion des flux de données. Cette solution est actuellement en « disponibilité pré-générale » et uniquement dans certaines régions.
Comme précédemment, la mise en œuvre de Cloud Datastream nécessite la configuration d’un Reverse Proxy hébergé au sein d’une instance Google Compute Engine. Ce « reverse proxy » est nécessaire pour accéder aux sources de données hébergées et sécurisées dans Google Cloud VMware Engine. Cette mise en œuvre est décrite dans cette documentation.
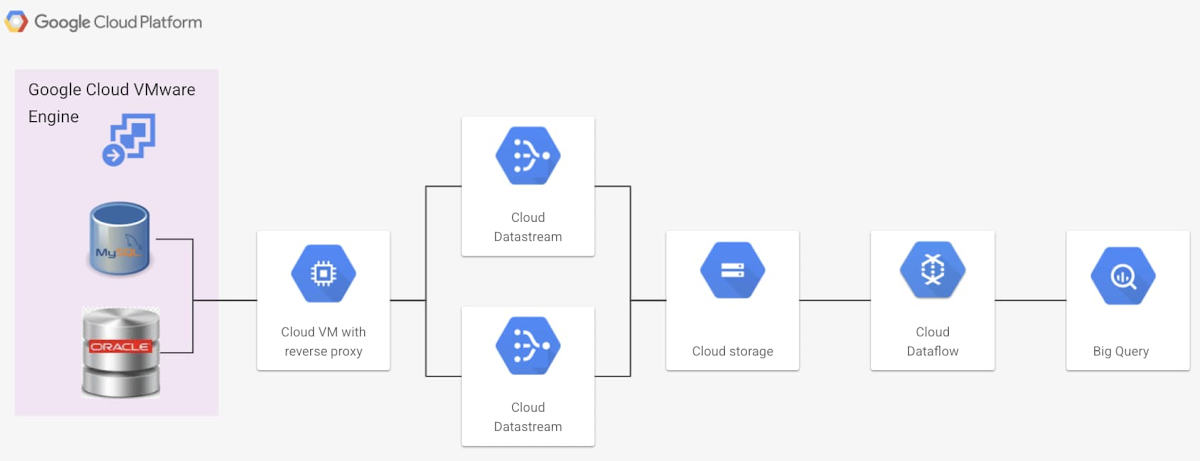
Vous trouverez une documentation complète pour configurer Datastream dans ce guide. Bien évidemment, la réplication ne peut être exécutée qu’après configuration dans Datastream d’un flux qui accède aux données et les achemine vers la cible de stockage cloud. Datastream accède aux données Google Cloud VMware Engine en utilisant un reverse proxy qui doit être exposé dans le VPC du client. Pour acheminer les données vers BigQuery, nous utilisons un modèle « Datastream vers BigQuery » préconfiguré au sein de Google Cloud Dataflow.
Comment bien démarrer un projet
Dans un premier temps, il convient de redéployer vos workloads vers Cloud VMware Engine, tâche généralement gérée par votre administrateur/architecte du cloud. Si les données résidant sur les machines virtuelles hébergées dans Google Cloud VMware Engine n’ont pas été identifiées pendant la phase de redéploiement, il faut dans un second temps les identifier et recréer les rapports existants à l'aide de BigQuery.
Dans la plupart des entreprises, plusieurs personnes sont impliquées dans ce processus : un architecte de données peut être le mieux placé pour savoir où sont les sources de données, un architecte de solutions aura une idée plus précise des implications en termes de coûts/performances, etc. Il faudra également connaître les portes d’entrée de l’infrastructure indispensables aux interfaces réseau.
Les étapes suivantes illustrent une approche possible pour réussir sa redéploiement:
- Identifiez les jeux de données sur les machines virtuelles redéployées vers Google Cloud VMware Engine et qui sont utilisés pour le reporting.
- Sélectionnez le bon pipeline (Datastream ou Data Fusion) en fonction du type de base et des exigences du pipeline (compromis prix/performance et facilité d'utilisation).
- En fonction du pipeline de données, sélectionnez la région appropriée. Il n'y a pas de frais de sortie des données au sein d'une même région.
- Configurez le reverse proxy vers le jeu de données Google Cloud VMware Engine.
- Configurez le service de réplication avec des paramètres basés sur la performance de réplication nécessaire.
- Autorisez l'analyse et la visualisation des données en fonction des besoins de l'entreprise.
Conclusion
Simple et rapide, le service Google Cloud VMware Engine est un excellent moyen pour exploiter vos jeux de données existants dans le cloud. Vous pouvez ainsi capitaliser sur votre infrastructure VMWare existante pour réaliser des analyses de données dans le cloud sans avoir à réarchitecturer vos bases, ce qui prendrait beaucoup trop de temps. Dit autrement, ces approches vous permettent non seulement de profiter des performances d’un matériel dédié sur Google Cloud mais également de bénéficier de fonctionnalités (pour valoriser vos données) qui sont aujourd’hui considérées comme les plus avancées du marché.