이 튜토리얼에서는 Databricks 노트북에서 데이터를 읽고 쓰기 위해 BigQuery 테이블 또는 뷰를 연결하는 방법을 보여줍니다. 이 단계는 Google Cloud 콘솔 및 Databricks 작업공간을 사용하여 설명합니다.
gcloud 및 databricks 명령줄 도구를 사용하여 이 단계를 수행할 수도 있습니다. 하지만 이 튜토리얼에서는 다루지 않습니다.
Google Cloud 의 Databricks는 Google Cloud에서 호스팅되는 Databricks 환경으로, Google Kubernetes Engine(GKE)에서 실행되며 BigQuery 및 기타 Google Cloud 기술과 기본적으로 통합됩니다. Databricks를 처음 사용하는 경우 Databricks 통합 데이터 플랫폼 소개 동영상을 통해 Databricks 레이크 하우스 플랫폼의 개요를 확인합니다.
Google Cloud에 Databricks 배포
다음 단계를 완료하여 Google Cloud에서 Databricks를 배포할 준비를 합니다.
- Databricks 계정을 설정하려면 Databricks 문서 Google Cloud계정에 Databricks 설정의 안내를 따릅니다.
- 등록 후 Databricks 계정 관리 방법을 자세히 알아보세요.
Databricks 작업공간, 클러스터, 노트북 만들기
다음 단계에서는 BigQuery에 액세스하기 위한 코드를 작성하기 위해 Databricks 작업공간, 클러스터, Python 노트북을 만드는 방법을 설명합니다.
Datarick 기본 요건을 확인합니다.
첫 번째 작업공간을 만듭니다. Databricks 계정 콘솔에서 작업공간 만들기를 클릭합니다.
작업공간 이름에
gcp-bq를 지정하고 리전을 선택합니다.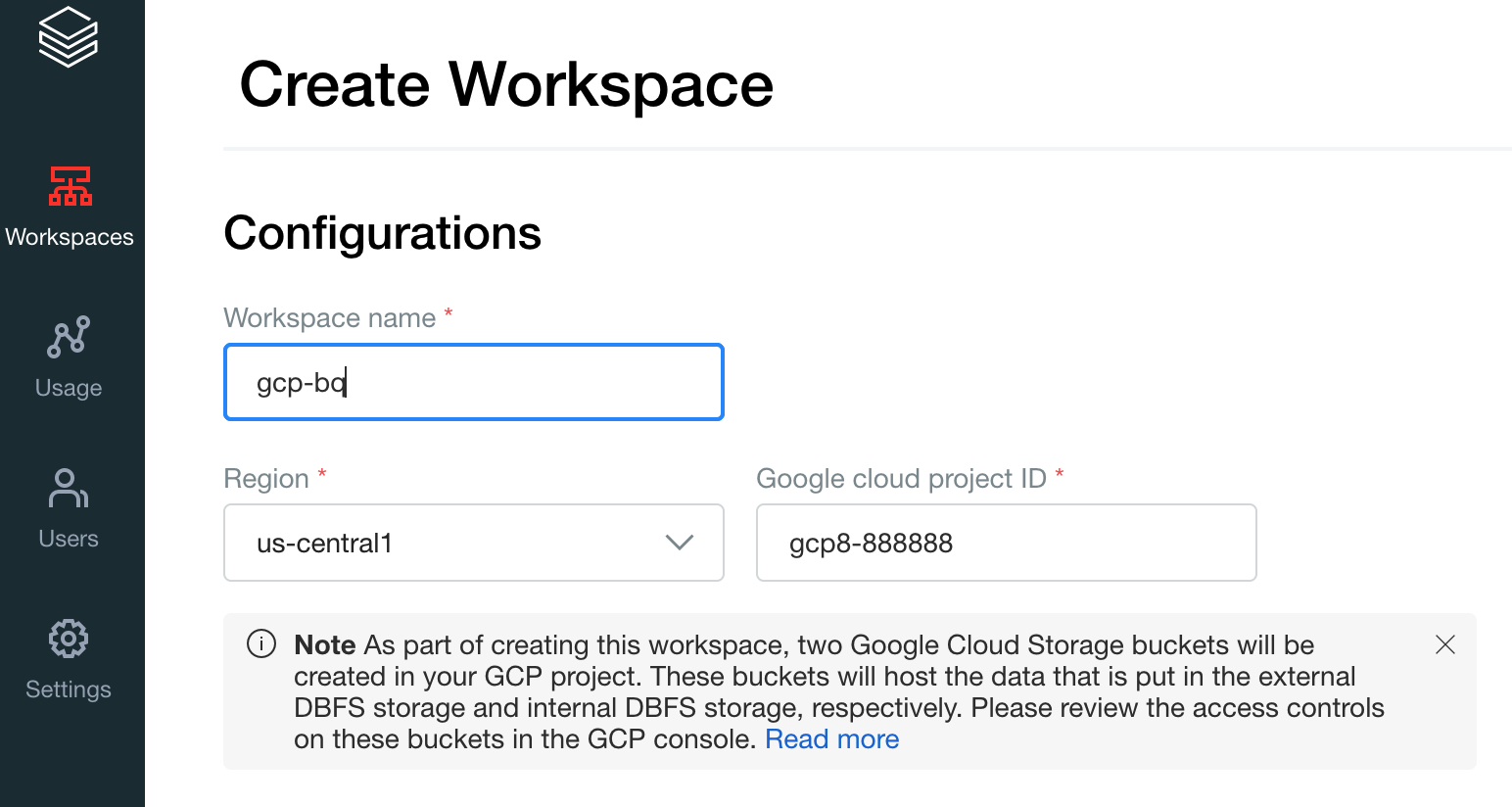
Google Cloud 프로젝트 ID를 확인하려면 Google Cloud 콘솔을 방문하여 값을 Google Cloud 프로젝트 ID 필드에 복사합니다.
저장을 클릭하여 Databricks 작업공간을 만듭니다.
Databricks 런타임 7.6 이상으로 Databricks 클러스터를 만들려면 왼쪽 메뉴 바에서 클러스터를 선택한 다음 상단에서 클러스터 만들기를 클릭합니다.
클러스터 이름과 크기를 지정한 다음 고급 옵션을 클릭하고 Google Cloud서비스 계정의 이메일 주소를 지정합니다.
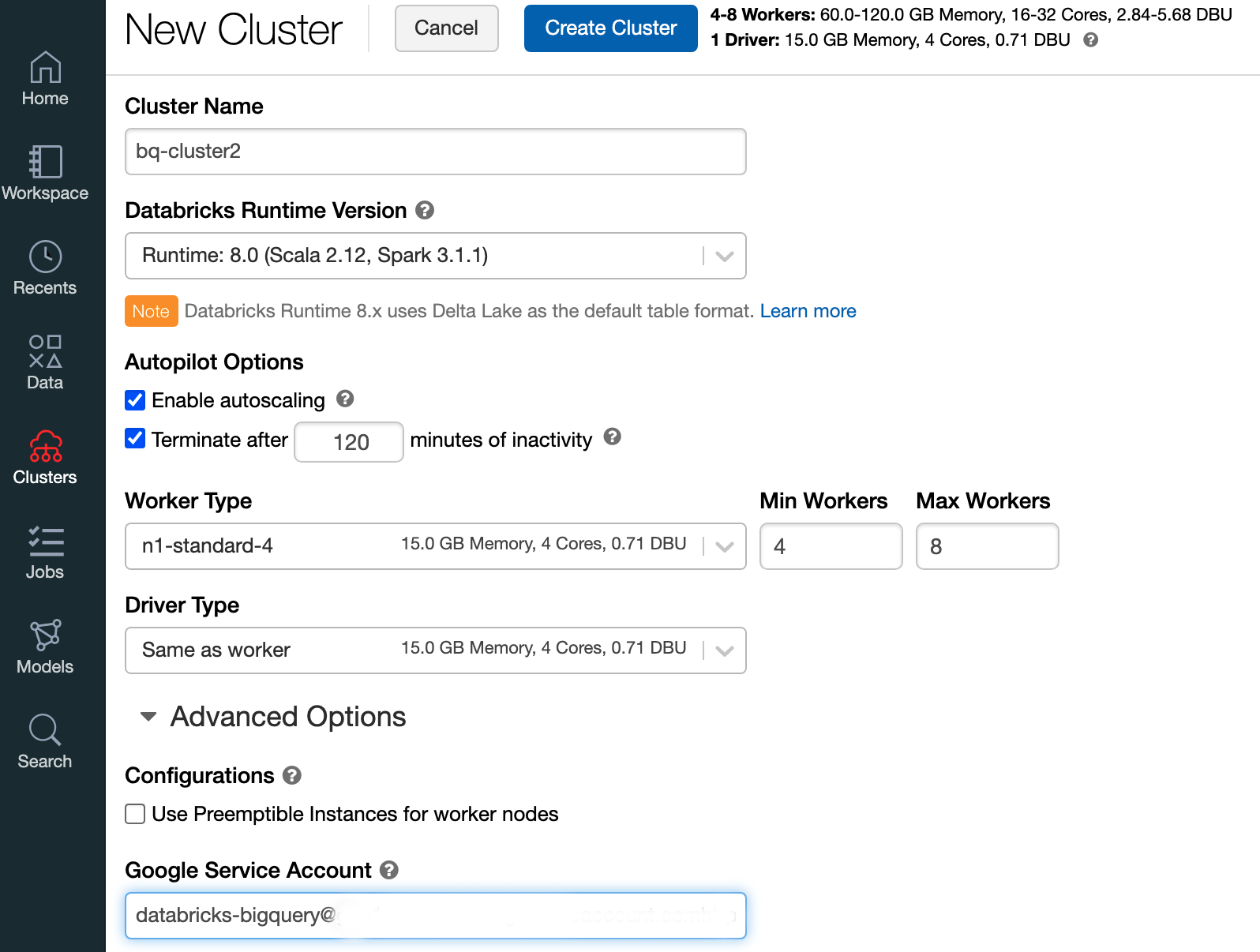
클러스터 만들기를 클릭합니다.
Databricks용 Python 노트북을 만들려면 노트북 만들기의 안내를 따르세요.
Databricks에서 BigQuery 쿼리하기
위 구성을 사용하면 Databricks를 BigQuery에 안전하게 연결할 수 있습니다. Databricks는 오픈소스 Google Spark 어댑터의 포크를 사용하여 BigQuery에 액세스합니다.
Databricks는 중첩된 열을 기준으로 BigQuery에 필터링하는 등 특정 쿼리 조건자를 자동으로 푸시하여 데이터 전송을 줄이고 쿼리를 가속화합니다. 또한 query() API를 사용하여 BigQuery에서 SQL 쿼리를 먼저 실행하는 기능이 추가되어 결과 데이터 세트의 전송 크기를 줄일 수 있습니다.
다음 단계에서는 BigQuery에서 데이터 세트에 액세스하고 BigQuery에 자체 데이터를 쓰는 방법을 설명합니다.
BigQuery의 공개 데이터 세트에 액세스
BigQuery는 사용 가능한 공개 데이터 세트 목록을 제공합니다. 공개 데이터 세트의 일부인 BigQuery Shakespeare 데이터 세트를 쿼리하려면 다음 단계를 따르세요.
BigQuery 테이블을 읽으려면 Databricks 노트북에 다음 코드 스니펫을 사용합니다.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Shift+Return을 눌러 코드를 실행합니다.이제 Spark DataFrame(
df)을 통해 BigQuery 테이블을 쿼리할 수 있습니다. 예를 들어 데이터 프레임의 처음 세 행을 표시하려면 다음을 사용합니다.df.show(3)다른 테이블을 쿼리하려면
table변수를 업데이트합니다.Databricks 노트북의 주요 특징은 Scala, Python, SQL과 같은 다양한 언어의 셀을 단일 노트북에 혼합할 수 있다는 점입니다.
다음 SQL 쿼리를 사용하면 임시 뷰를 만드는 이전 셀을 실행한 후 Shakespeare의 단어 수를 시각화할 수 있습니다.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12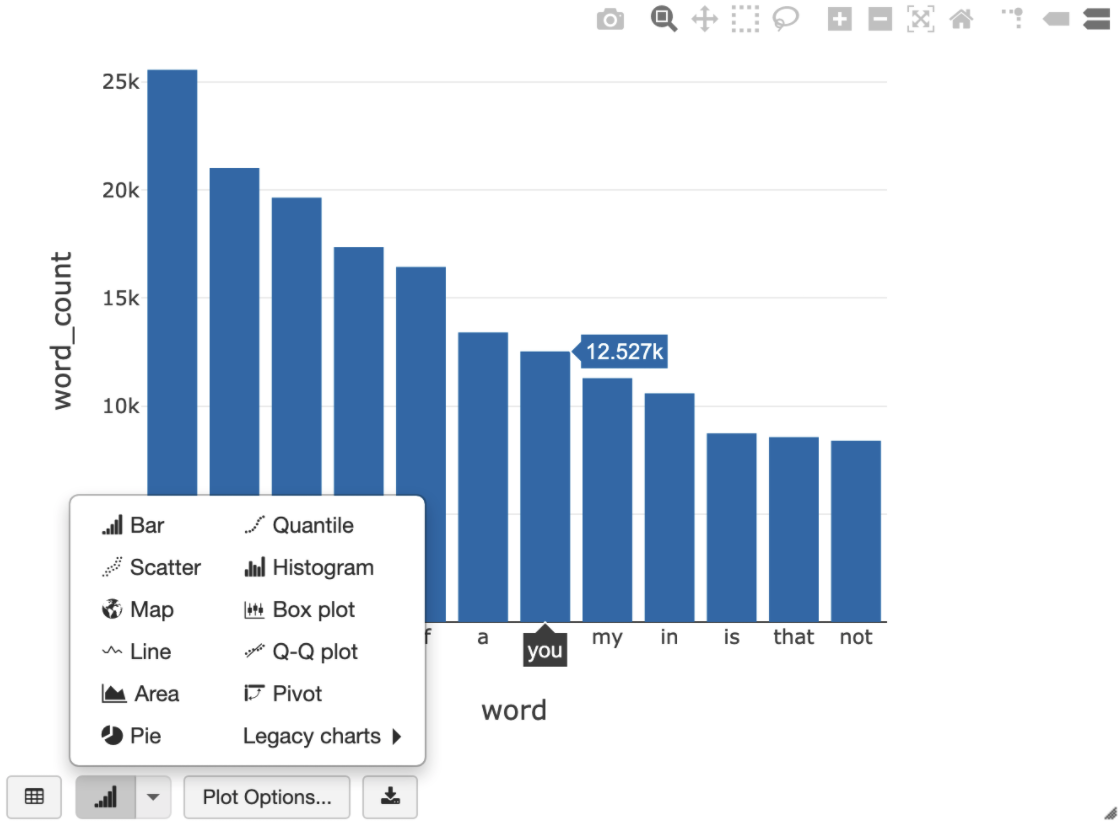
위의 셀은 BigQuery가 아닌 Databricks 클러스터의 데이터 프레임에 대해 Spark SQL 쿼리를 실행합니다. 이 방법의 장점은 데이터 분석이 Spark 수준에서 수행되고 BigQuery API 호출이 더 이상 발생하지 않으며 추가 BigQuery 비용이 발생하지 않는다는 것입니다.
대안으로
query()API를 사용하여 SQL 쿼리 실행을 BigQuery에 위임하고 결과 데이터 프레임의 전송 크기를 줄일 수 있습니다. Spark에서 처리가 완료된 위의 예시와 달리 이 방법을 사용하면 BigQuery에서 쿼리를 실행하는 경우에 가격 책정 및 쿼리 최적화가 적용됩니다.다음 예시에서는 BigQuery의 Scala,
query()API, 공개 Shakespeare 데이터 세트를 사용하여 Shakespeare의 작품에서 가장 일반적인 5개 단어를 계산합니다. 코드를 실행하기 전에 먼저 BigQuery에서 코드가 참조할 수 있는,mdataset라는 빈 데이터 세트를 만들어야 합니다. 자세한 내용은 BigQuery에 데이터 쓰기를 참조하세요.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)더 많은 코드 예시를 보려면 Databricks BigQuery 샘플 노트북을 참조하세요.
BigQuery에 데이터 쓰기
BigQuery 테이블은 데이터 세트에 있습니다. BigQuery 테이블에 데이터를 쓰려면 먼저 BigQuery에 새 데이터 세트를 만들어야 합니다. Databricks Python 노트북에 데이터 세트를 만들려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
작업 옵션을 펼치고 데이터 세트 만들기를 클릭한 다음 이름을
together로 지정합니다.Databricks Python 노트북에서 다음 코드 스니펫을 사용하여 Python 목록으로부터 간단한 Spark 데이터 프레임을 만듭니다.
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())이전 단계의 Spark 데이터 프레임을
together데이터 세트의myTableBigQuery 테이블에 쓰는 노트북에 다른 셀을 추가합니다. 테이블을 만들거나 덮어씁니다. 앞에서 지정한 버킷 이름을 사용합니다.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()데이터 쓰기가 완료되었는지 확인하려면 Spark DataFrame(
df)을 통해 BigQuery 테이블을 쿼리하고 표시합니다.display(spark.read.format("bigquery").option("table", table).load)