Questo tutorial mostra come collegare una tabella o una vista BigQuery per leggere e scrivere dati da un notebook Databricks. I passaggi sono
descritti utilizzando la
Google Cloud console e
Databricks Workspaces.
Puoi anche eseguire questi passaggi utilizzando gli strumenti a riga di comando gcloud e databricks, anche se queste indicazioni non rientrano nell'ambito di questo tutorial.
Databricks on Google Cloud è un ambiente Databricks ospitato su Google Cloud, in esecuzione su Google Kubernetes Engine (GKE) e che fornisce un'integrazione integrata con BigQuery e altre tecnologie Google Cloud . Se non hai mai utilizzato Databricks, guarda il video Introduzione alla piattaforma di dati unificata Databricks per una panoramica della piattaforma lakehouse di Databricks.
Obiettivi
- Configura Google Cloud per connetterti a Databricks.
- Esegui il deployment di Databricks su Google Cloud.
- Esegui query su BigQuery da Databricks.
Costi
Questo tutorial utilizza i componenti fatturabili della Google Cloud console, tra cui BigQuery e GKE. Si applicano i prezzi di BigQuery e i prezzi di GKE. Per informazioni sui costi associati a un account Databricks eseguito su Google Cloud, consulta la sezione Configurare l'account e creare uno spazio di lavoro nella documentazione di Databricks.
Prima di iniziare
Prima di collegare Databricks a BigQuery, completa i seguenti passaggi:
- Abilita l'API BigQuery Storage.
- Crea un account di servizio per Databricks.
- Crea un bucket Cloud Storage per lo spazio di archiviazione temporaneo.
Abilita l'API BigQuery Storage
L'API BigQuery Storage è abilitata per impostazione predefinita per tutti i nuovi progetti in cui viene utilizzato BigQuery. Per i progetti esistenti in cui l'API non è abilitata, segui queste istruzioni:
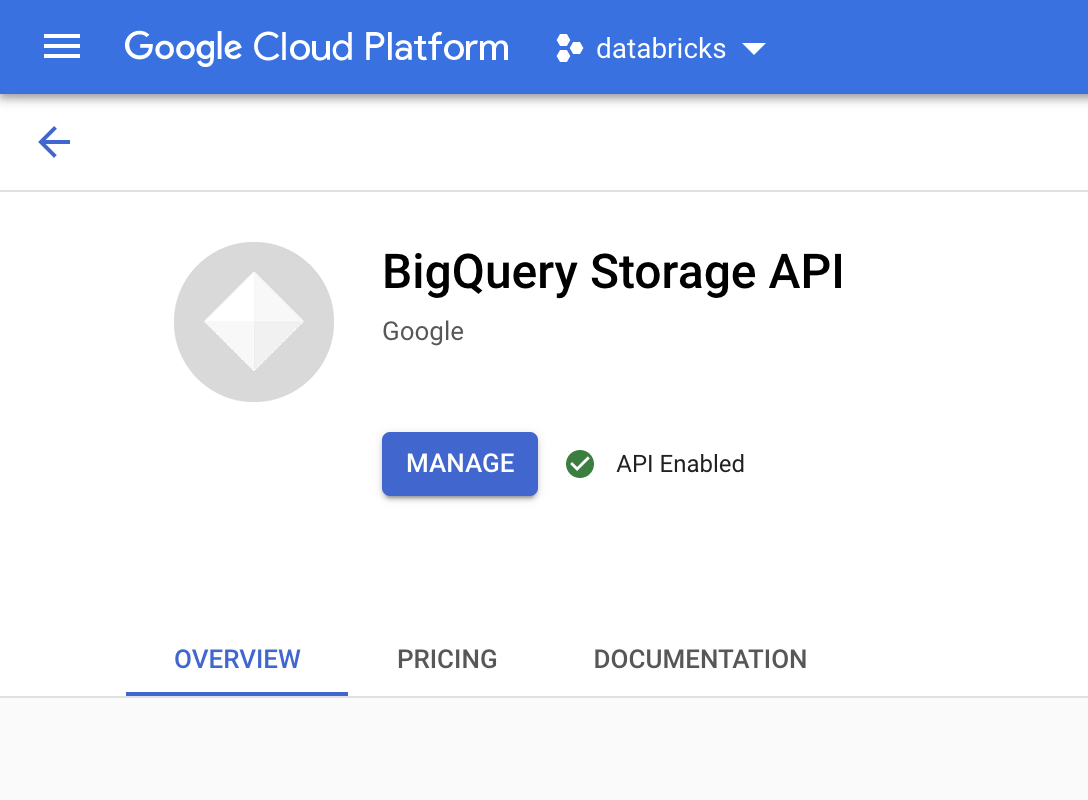
Nella Google Cloud console, vai alla pagina API BigQuery Storage.
Verifica che l'API BigQuery Storage sia abilitata.
Creare un account di servizio per Databricks
Successivamente, crea un account di servizio Identity and Access Management (IAM) per consentire a un cluster Databricks di eseguire query su BigQuery. Ti consigliamo di assegnare a questo account di servizio i privilegi minimi necessari per svolgere le sue attività. Consulta Ruoli e autorizzazioni BigQuery.
Nella Google Cloud console, vai alla pagina Account di servizio.
Fai clic su Crea account di servizio, assegna un nome all'account di servizio
databricks-bigquery, inserisci una breve descrizione, ad esempioDatabricks tutorial service account, quindi fai clic su Crea e continua.In Concedi a questo account di servizio l'accesso al progetto, specifica i ruoli per l'account di servizio. Per concedere all'account di servizio l'autorizzazione per leggere i dati con lo spazio di lavoro Databricks e la tabella BigQuery nello stesso progetto, in particolare senza fare riferimento a una vista materializzata, concedi i seguenti ruoli:
- BigQuery Read Session User
- Visualizzatore dati BigQuery
Per concedere l'autorizzazione a scrivere dati, concedi i seguenti ruoli:
- Utente job BigQuery
- BigQuery Data Editor
Prendi nota dell'indirizzo email del nuovo account di servizio da utilizzare come riferimento per i passaggi futuri.
Fai clic su Fine.
Crea un bucket Cloud Storage
Per scrivere in BigQuery, il cluster Databricks deve avere accesso a un bucket Cloud Storage per eseguire il buffering dei dati scritti.
Nella Google Cloud console, vai a Browser Cloud Storage.
Fai clic su Crea bucket per aprire la finestra di dialogo Crea un bucket.
Specifica un nome per il bucket utilizzato per scrivere i dati in BigQuery. Il nome del bucket deve essere un nome univoco a livello globale. Se specifichi un nome di bucket esistente, Cloud Storage risponde con un messaggio di errore. In questo caso, specifica un nome diverso per il bucket.
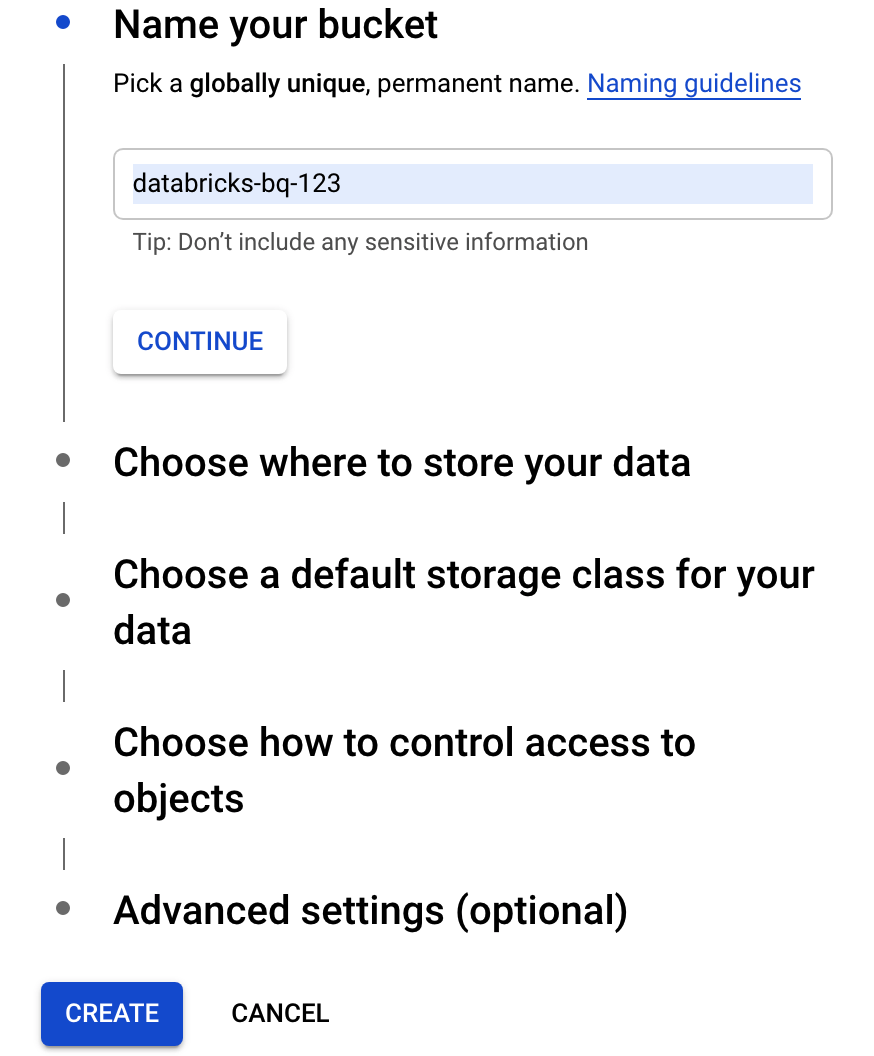
Per questo tutorial, utilizza le impostazioni predefinite per la posizione di archiviazione, la classe di archiviazione, il controllo dell'accesso e le impostazioni avanzate.
Fai clic su Crea per creare il bucket Cloud Storage.
Fai clic su Autorizzazioni, poi su Aggiungi e specifica l'indirizzo email dell'account di servizio che hai creato per l'accesso a Databricks nella pagina Account di servizio.
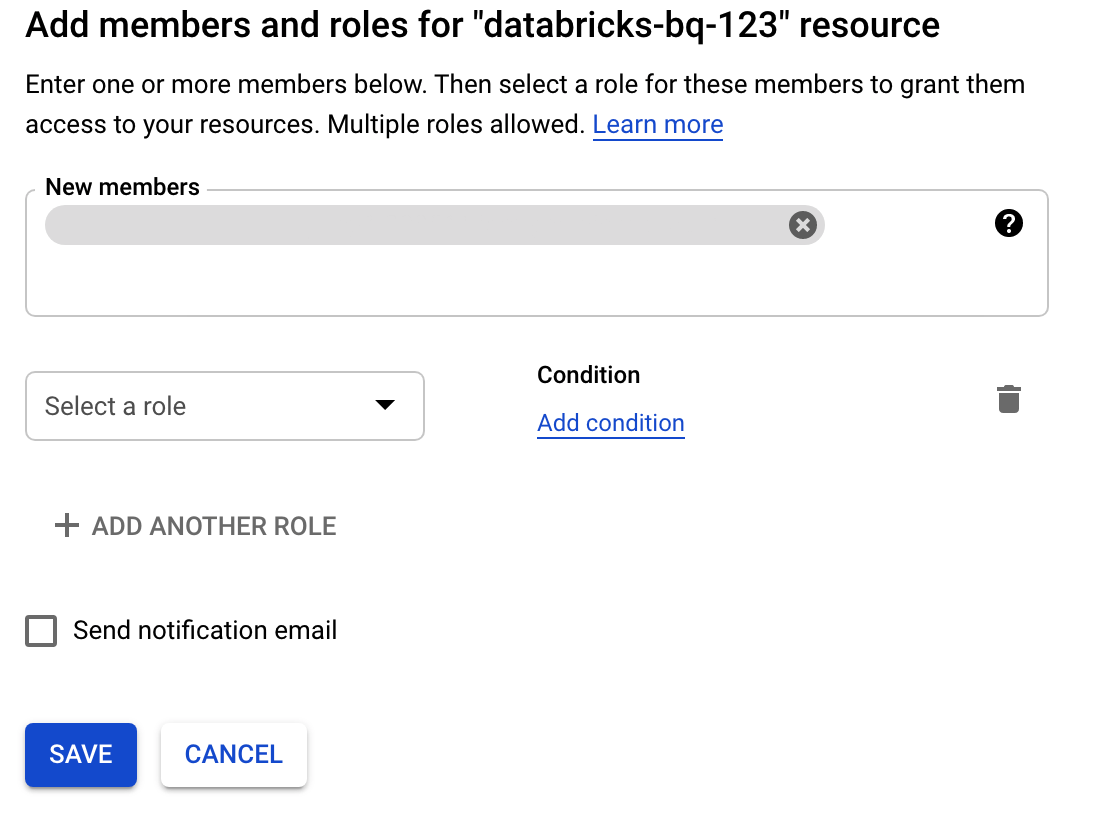
Fai clic su Seleziona un ruolo e aggiungi il ruolo Amministratore dello spazio di archiviazione.
Fai clic su Salva.
Esegui il deployment di Databricks su Google Cloud
Completa i seguenti passaggi per prepararti a eseguire il deployment di Databricks su Google Cloud.
- Per configurare il tuo account Databricks, segui le istruzioni riportate nella documentazione di Databricks, Configurare l'account Databricks su Google Cloud.
- Dopo la registrazione, scopri di più su come gestire il tuo account Databricks.
Crea uno spazio di lavoro, un cluster e un notebook Databricks
I passaggi che seguono descrivono come creare uno spazio di lavoro Databricks, un cluster e un blocco note Python per scrivere codice per accedere a BigQuery.
Verifica i prerequisiti di Databrick.
Crea il tuo primo spazio di lavoro. Nella console dell'account Databricks, fai clic su Crea spazio di lavoro.
Specifica
gcp-bqper il nome dello spazio di lavoro e seleziona la regione.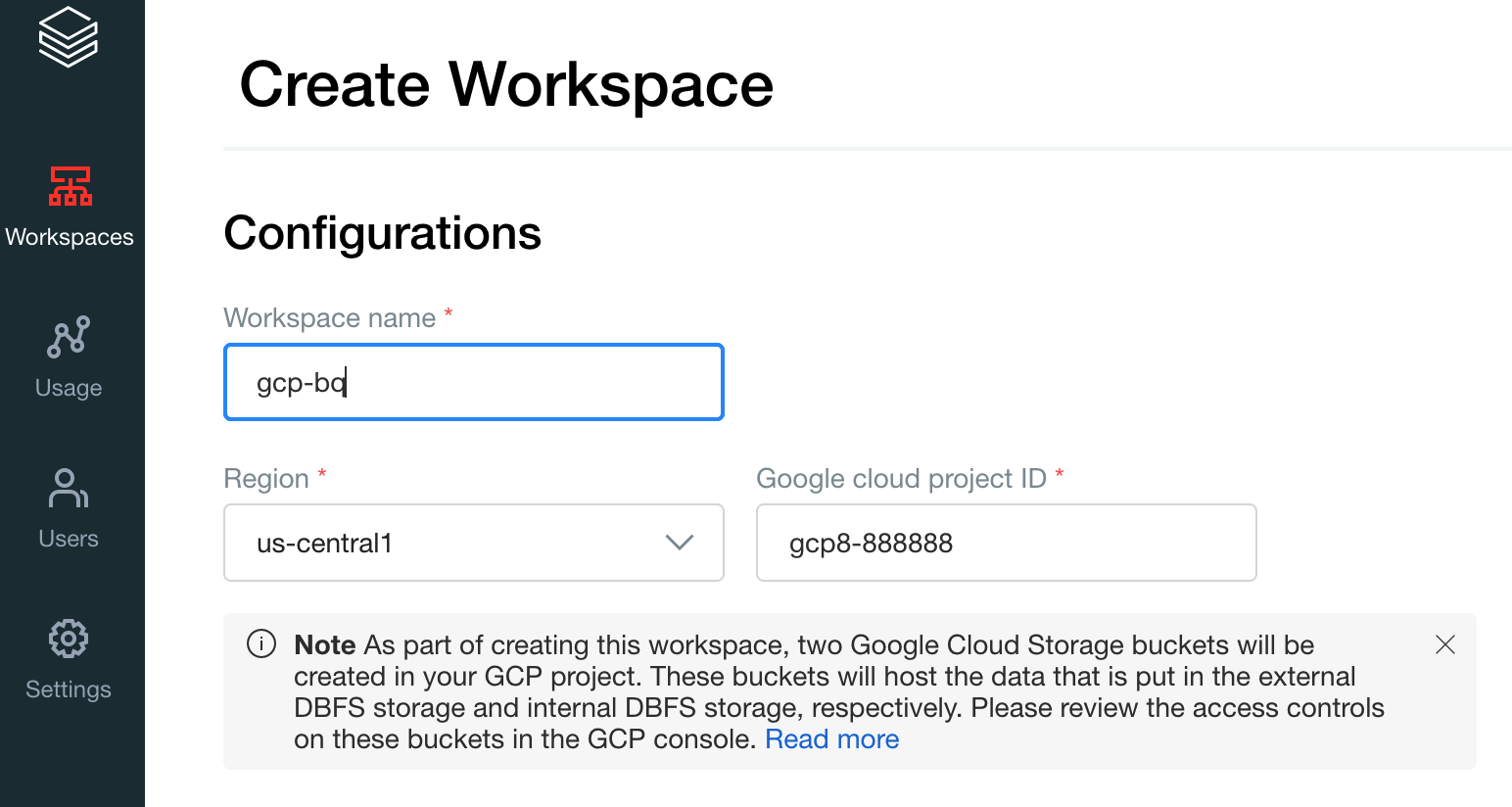
Per determinare il tuo Google Cloud ID progetto, visita la Google Cloud console, quindi copia il valore nel campo Google Cloud ID progetto.
Fai clic su Salva per creare lo spazio di lavoro Databricks.
Per creare un cluster Databricks con il runtime Databricks 7.6 o versioni successive, nella barra dei menu a sinistra seleziona Cluster e poi fai clic su Crea cluster in alto.
Specifica il nome e le dimensioni del cluster, poi fai clic su Opzioni avanzate e specifica l'indirizzo email del tuo account di servizio Google Cloud.
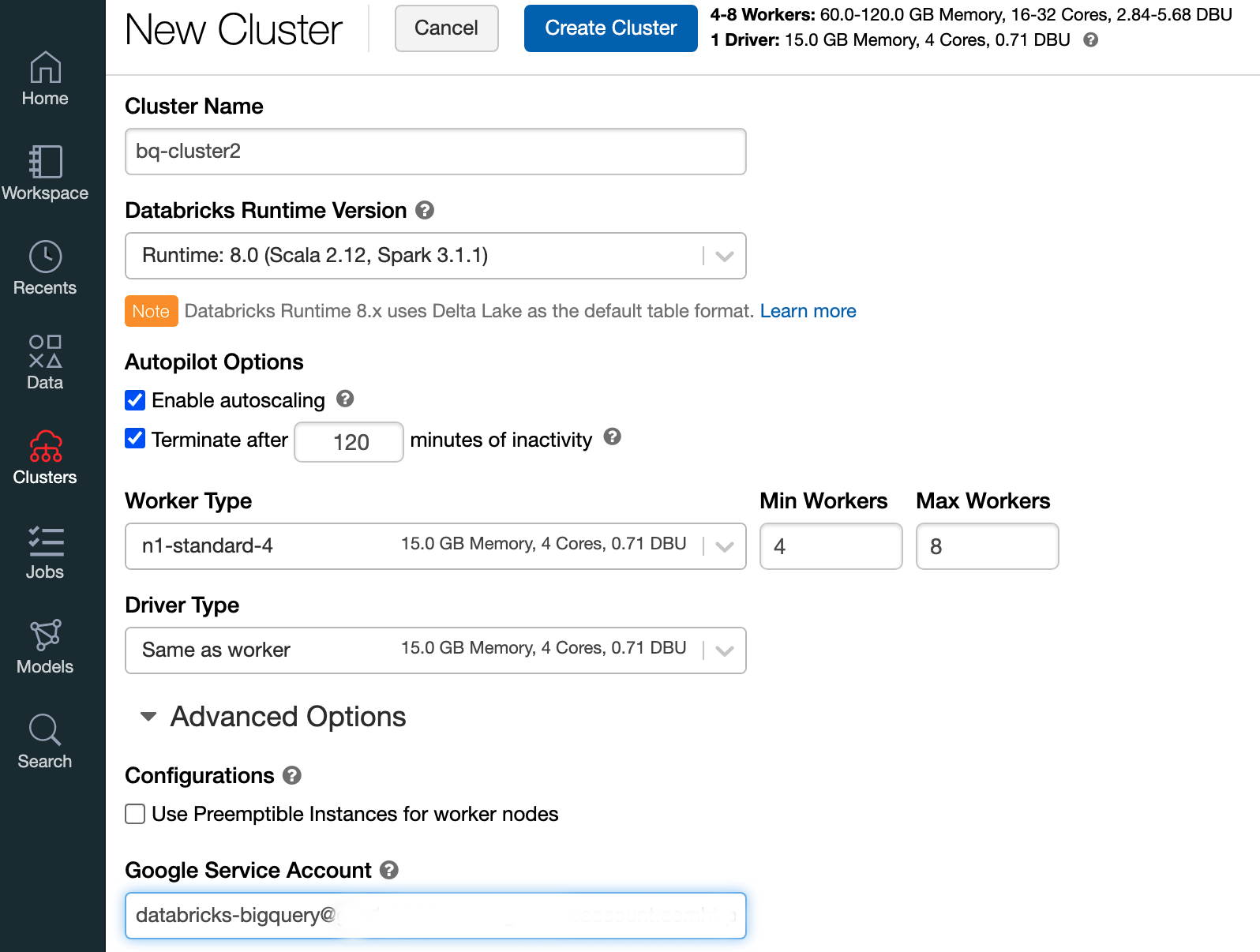
Fai clic su Crea cluster.
Per creare un notebook Python per Databricks, segui le istruzioni riportate in Creare un notebook.
Eseguire query su BigQuery da Databricks
Con la configurazione riportata sopra, puoi collegare in modo sicuro Databricks a BigQuery. Databricks utilizza un fork dell'adattatore Google Spark open source per accedere a BigQuery.
Databricks riduce il trasferimento dei dati e accelera le query spingendo automaticamente determinati predicati delle query, ad esempio i filtri per le colonne nidificate, in BigQuery. Inoltre, la possibilità aggiuntiva di eseguire prima una query SQL su BigQuery con l'API query() riduce le dimensioni del trasferimento del set di dati risultante.
I passaggi che seguono descrivono come accedere a un set di dati in BigQuery e scrivere i tuoi dati in BigQuery.
Accedere a un set di dati pubblico su BigQuery
BigQuery fornisce un elenco di set di dati pubblici disponibili. Per eseguire query sul set di dati BigQuery Shakespeare che fa parte dei set di dati pubblici:
Per leggere la tabella BigQuery, utilizza il seguente snippet di codice nel tuo notebook Databricks.
table = "bigquery-public-data.samples.shakespeare" df = spark.read.format("bigquery").option("table",table).load() df.createOrReplaceTempView("shakespeare")Esegui il codice premendo
Shift+Return.Ora puoi eseguire query sulla tabella BigQuery tramite il DataFrame Spark (
df). Ad esempio, utilizza quanto segue per mostrare le prime tre righe del dataframe:df.show(3)Per eseguire una query su un'altra tabella, aggiorna la variabile
table.Una funzionalità chiave dei notebook Databricks è che puoi combinare le celle di diversi linguaggi, come Scala, Python e SQL, in un unico notebook.
La seguente query SQL consente di visualizzare il conteggio delle parole in Shakespeare dopo aver eseguito la cella precedente che crea la vista temporanea.
%sql SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word ORDER BY word_count DESC LIMIT 12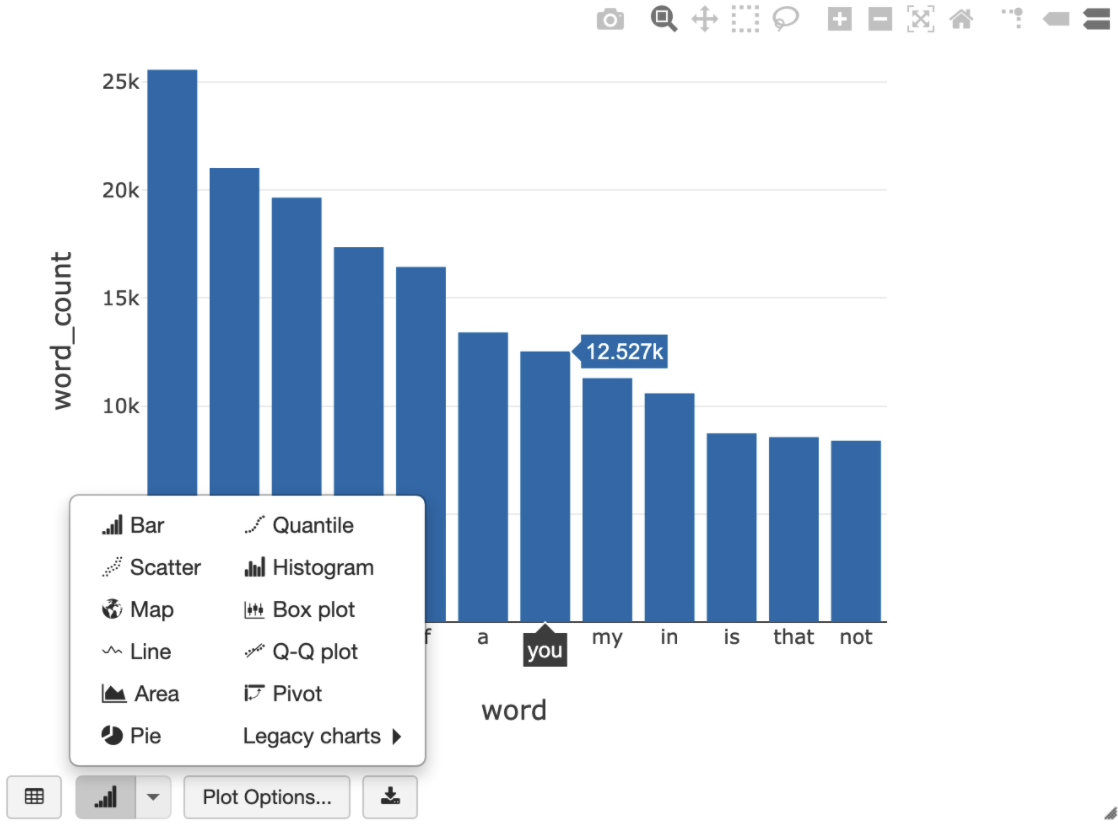
La cella sopra esegue una query Spark SQL sul dataframe nel cluster Databricks, non in BigQuery. Il vantaggio di questo approccio è che l'analisi dei dati avviene a livello di Spark, non vengono emesse altre chiamate all'API BigQuery e non sono previsti costi aggiuntivi per BigQuery.
In alternativa, puoi delegare l'esecuzione di una query SQL a BigQuery con l'API
query()e ottimizzare per ridurre le dimensioni del trasferimento del frame di dati risultante. A differenza dell'esempio riportato sopra, in cui l'elaborazione è stata eseguita in Spark, se utilizzi questo approccio, per l'esecuzione della query su BigQuery vengono applicate le ottimizzazioni dei prezzi e delle query.L'esempio seguente utilizza Scala, l'API
query()e il set di dati pubblico di Shakespeare in BigQuery per calcolare le cinque parole più comuni nelle opere di Shakespeare. Prima di eseguire il codice, devi creare un set di dati vuoto in BigQuery chiamatomdataseta cui il codice può fare riferimento. Per ulteriori informazioni, consulta Scrivere dati in BigQuery.%scala // public dataset val table = "bigquery-public-data.samples.shakespeare" // existing dataset where the Google Cloud user has table creation permission val tempLocation = "mdataset" // query string val q = s"""SELECT word, SUM(word_count) AS word_count FROM ${table} GROUP BY word ORDER BY word_count DESC LIMIT 10 """ // read the result of a GoogleSQL query into a DataFrame val df2 = spark.read.format("bigquery") .option("query", q) .option("materializationDataset", tempLocation) .load() // show the top 5 common words in Shakespeare df2.show(5)Per altri esempi di codice, consulta il notebook di esempio BigQuery di Databricks.
Scrittura di dati in BigQuery
Le tabelle BigQuery esistono nei set di dati. Prima di poter scrivere dati in una tabella BigQuery, devi creare un nuovo set di dati in BigQuery. Per creare un set di dati per un notebook Python di Databricks:
Vai alla pagina BigQuery nella Google Cloud console.
Espandi l'opzione Azioni , fai clic su Crea set di dati e poi assegnagli un nome, ad esempio
together.Nel notebook Python di Databricks, crea un semplice dataframe Spark da un elenco Python con tre voci di stringa utilizzando il seguente snippet di codice:
from pyspark.sql.types import StringType mylist = ["Google", "Databricks", "better together"] df = spark.createDataFrame(mylist, StringType())Aggiungi un'altra cella al notebook che scriva il dataframe Spark del passaggio precedente nella tabella BigQuery
myTablenel set di datitogether. La tabella viene creata o sovrascritta. Utilizza il nome del bucket specificato in precedenza.bucket = YOUR_BUCKET_NAME table = "together.myTable" df.write .format("bigquery") .option("temporaryGcsBucket", bucket) .option("table", table) .mode("overwrite").save()Per verificare di aver scritto correttamente i dati, esegui query e visualizza la tabella BigQuery tramite il DataFrame Spark (
df):display(spark.read.format("bigquery").option("table", table).load)
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Prima di rimuovere Databricks, esegui sempre il backup dei dati e dei notebook. Per eseguire la pulizia e rimuovere completamente Databricks, annulla l'abbonamento a Databricks nella Google Cloud console e rimuovi le risorse correlate che hai creato dalla Google Cloud console.Google Cloud
Se elimini uno spazio di lavoro Databricks, i due bucket Cloud Storage con i nomi databricks-WORKSPACE_ID edatabricks-WORKSPACE_ID-system che sono staticreati da Databricks
potrebbero non essere eliminati se i bucket Cloud Storage non sono vuoti. Dopo
l'eliminazione dello spazio di lavoro, puoi eliminare manualmente questi oggetti nella
Google Cloud console del tuo progetto.
Passaggi successivi
Questa sezione fornisce un elenco di documenti e tutorial aggiuntivi:
- Scopri i dettagli della prova gratuita di Databricks.
- Scopri di più su Databricks su Google Cloud.
- Scopri di più su Databricks BigQuery.
- Leggi l'annuncio del blog relativo al supporto di BigQuery per Databricks.
- Scopri di più sui notebook di esempio di BigQuery.
- Scopri di più sul provider Terraform per Databricks su Google Cloud.
- Leggi il blog di Databricks, che include maggiori informazioni su argomenti di data science e set di dati.