This page shows how to configure a user cluster for Google Distributed Cloud so that custom logs and metrics from user applications are sent to Cloud Logging and Cloud Monitoring.
From 1.12, you can use Google Cloud Managed Service for Prometheus to monitor your workloads as a preview feature. This is Google Cloud's fully managed storage and query service for Prometheus metrics. To use this feature, enable Managed Service for Prometheus and Cloud Logging by following the steps below.
Enabling Managed Service for Prometheus for user applications (Preview)
The configuration for Managed Service for Prometheus is
held in a Stackdriver object named stackdriver.
Open the
stackdriverobject for editing:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace kube-system edit stackdriver stackdriver
Replace USER_CLUSTER_KUBECONFIG with the path of your user cluster kubeconfig file.
Under
spec, setenableGMPForApplicationstotrue:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableGMPForApplications: true enableVPC: ... optimizedMetrics: trueClose the edited file. This will begin running Google-managed Prometheus (GMP) components in the cluster.
To check the components, run the following command:
kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace gmp-system get pods
The output of this command is similar to the following:
NAME READY STATUS RESTARTS AGE collector-abcde 2/2 Running 1 (5d18h ago) 5d18h collector-fghij 2/2 Running 1 (5d18h ago) 5d18h collector-klmno 2/2 Running 1 (5d18h ago) 5d18h gmp-operator-68d49656fc-abcde 1/1 Running 0 5d18h rule-evaluator-7c686485fc-fghij 2/2 Running 1 (5d18h ago) 5d18h
Managed Service for Prometheus supports rule evaluation and alerting. To set up rule evaluation, see Rule evaluation.
Running an example application
In this section, you create an application that emits Prometheus metrics, and use Google-managed Prometheus to collect the metrics. For more information, see Google Cloud Managed Service for Prometheus.
Deploy the example application
Create the
gmp-testnamespace for resources you create as part of the example application:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG create ns gmp-test
The managed service provides a manifest for an example application that emits Prometheus metrics on its
metricsport. The application uses three replicas.To deploy the example application, run the following command:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG -n gmp-test apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.4.1/examples/example-app.yaml
Configure a PodMonitoring resource
To ingest the metric data emitted by the example application, you use target scraping. The managed service uses PodMonitoring custom resources (CRs) to configure target scraping and metrics ingestion. You can convert your existing prometheus-operator resources to PodMonitoring CRs.
A PodMonitoring CR scrapes targets only in the namespace the CR is deployed in. To scrape targets in multiple namespaces, deploy the same PodMonitoring CR in each namespace. You can verify the PodMonitoring resource is installed in the intended namespace by running the following command:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG get podmonitoring -A
For reference documentation about all the Managed Service for Prometheus CRs, see the prometheus-engine/doc/api reference.
The following manifest defines a PodMonitoring resource, prom-example, in
the gmp-test namespace. The resource finds all Pods in the namespace that have the label
app with the value prom-example. The matching Pods are
scraped on a port named metrics, every 30 seconds, on the /metrics
HTTP path.
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app: prom-example
endpoints:
- port: metrics
interval: 30s
To apply this resource, run the following command:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG -n gmp-test apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.4.1/examples/pod-monitoring.yaml
Managed Service for Prometheus is now scraping the matching Pods.
Query metrics data
The simplest way to verify that your Prometheus data is being exported is to use PromQL queries in the Metrics Explorer in the Google Cloud console.
To run a PromQL query, do the following:
In the Google Cloud console, go to the Monitoring page or click the following button:
In the navigation pane, select
 Metrics Explorer.
Metrics Explorer.Use Prometheus Query Language (PromQL) to specify the data to display on the chart:
In the toolbar of the Select a metric pane, select Code Editor.
Select PromQL in the Language toggle. The language toggle is at the bottom of the Code Editor pane.
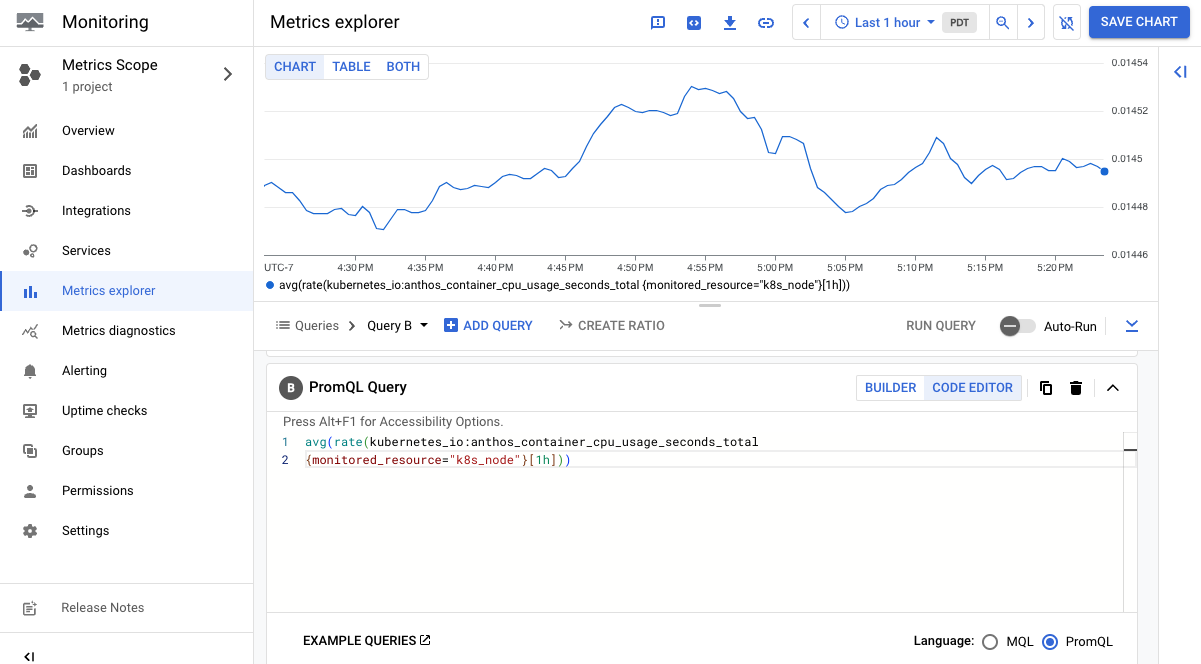
Enter your query into the query editor. For example, to chart the average number of seconds CPUs spent in each mode over the past hour, use the following query:
avg(rate(kubernetes_io:anthos_container_cpu_usage_seconds_total {monitored_resource="k8s_node"}[1h]))
For more information about using PromQL, see PromQL in Cloud Monitoring.
The following screenshot shows a chart that displays the
anthos_container_cpu_usage_seconds_total metric:
If you collect a lot of data, you might want to filter exported metrics to keep costs down.
Enabling Cloud Logging for user applications (Preview)
The configuration for Logging is held in a Stackdriver object named stackdriver.
Open the
stackdriverobject for editing:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace kube-system edit stackdriver stackdriver
Replace USER_CLUSTER_KUBECONFIG with the path of your user cluster kubeconfig file.
Under
spec, setenableCloudLoggingForApplicationstotrue:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableCloudLoggingForApplications: true enableVPC: ... optimizedMetrics: trueClose the edited file.
Running an example application
In this section, you create an application that writes custom logs.
Save the following Deployment manifest to a file named
my-app.yaml.apiVersion: apps/v1 kind: Deployment metadata: name: "monitoring-example" namespace: "default" labels: app: "monitoring-example" spec: replicas: 1 selector: matchLabels: app: "monitoring-example" template: metadata: labels: app: "monitoring-example" spec: containers: - image: gcr.io/google-samples/prometheus-dummy-exporter:latest name: prometheus-example-exporter imagePullPolicy: Always command: - /bin/sh - -c - ./prometheus-dummy-exporter --metric-name=example_monitoring_up --metric-value=1 --port=9090 resources: requests: cpu: 100mCreate the Deployment:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG apply -f my-app.yaml
Viewing application logs
Console
Go to the Logs explorer in the Google Cloud console.
Click Resource. Under ALL_RESOURCE_TYPES, select
Kubernetes Container.Under CLUSTER_NAME, select the name of your user cluster.
Under NAMESPACE_NAME, select
default.Click Add and then click Run Query.
Under Query results, you can see log entries from the
monitoring-exampleDeployment. For example:{ "textPayload": "2020/11/14 01:24:24 Starting to listen on :9090\n", "insertId": "1oa4vhg3qfxidt", "resource": { "type": "k8s_container", "labels": { "pod_name": "monitoring-example-7685d96496-xqfsf", "cluster_name": ..., "namespace_name": "default", "project_id": ..., "location": "us-west1", "container_name": "prometheus-example-exporter" } }, "timestamp": "2020-11-14T01:24:24.358600252Z", "labels": { "k8s-pod/pod-template-hash": "7685d96496", "k8s-pod/app": "monitoring-example" }, "logName": "projects/.../logs/stdout", "receiveTimestamp": "2020-11-14T01:24:39.562864735Z" }
gcloud
Run this command:
gcloud logging read 'resource.labels.project_id="PROJECT_ID" AND \ resource.type="k8s_container" AND resource.labels.namespace_name="default"'Replace PROJECT_ID with the ID of your logging-monitoring project.
In the output, you can see log entries from the
monitoring-exampleDeployment. For example:insertId: 1oa4vhg3qfxidt labels: k8s-pod/app: monitoring-example k8s- pod/pod-template-hash: 7685d96496 logName: projects/.../logs/stdout receiveTimestamp: '2020-11-14T01:24:39.562864735Z' resource: labels: cluster_name: ... container_name: prometheus-example-exporter location: us-west1 namespace_name: default pod_name: monitoring-example-7685d96496-xqfsf project_id: ... type: k8s_container textPayload: | 2020/11/14 01:24:24 Starting to listen on :9090 timestamp: '2020-11-14T01:24:24.358600252Z'
Enabling Logging and Monitoring for user applications
This section describes how to enable Logging and Monitoring if you are not using Managed Service for Prometheus.
The configuration for Logging and Monitoring is
held in a Stackdriver object named stackdriver.
Open the
stackdriverobject for editing:kubectl --kubeconfig=USER_CLUSTER_KUBECONFIG --namespace kube-system edit stackdriver stackdriver
Replace USER_CLUSTER_KUBECONFIG with the path of your user cluster kubeconfig file.
Under
spec, setenableStackdriverForApplicationstotrue:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: projectID: ... clusterName: ... clusterLocation: ... proxyConfigSecretName: ... enableStackdriverForApplications: true enableVPC: ... optimizedMetrics: trueClose the edited file.
Annotating workloads
To enable the collection of custom metrics from an application, add the
prometheus.io/scrape: "true" annotation to the application's Service or Pod
manifest, or add the same annotation to the spec.template section in
Deployment or DaemonSet manifest in order to be passed to their Pods.
To avoid garbage collection of metrics, we recommend setting the metrics scrape interval to one minute.
Running an example application
In this section, you create an application that writes custom logs and exposes a custom metric.
Save the following Service and Deployment manifests to a file named
my-app.yaml. Notice that the Service has the annotationprometheus.io/scrape: "true":kind: Service apiVersion: v1 metadata: name: "monitoring-example" namespace: "default" annotations: prometheus.io/scrape: "true" spec: selector: app: "monitoring-example" ports: - name: http port: 9090 --- apiVersion: apps/v1 kind: Deployment metadata: name: "monitoring-example" namespace: "default" labels: app: "monitoring-example" spec: replicas: 1 selector: matchLabels: app: "monitoring-example" template: metadata: labels: app: "monitoring-example" spec: containers: - image: gcr.io/google-samples/prometheus-dummy-exporter:latest name: prometheus-example-exporter imagePullPolicy: Always command: - /bin/sh - -c - ./prometheus-dummy-exporter --metric-name=example_monitoring_up --metric-value=1 --port=9090 resources: requests: cpu: 100mCreate the Deployment and the Service:
kubectl --kubeconfig USER_CLUSTER_KUBECONFIG apply -f my-app.yaml
Viewing application logs
Console
Go to the Logs explorer in the Google Cloud console.
Click Resource. Under ALL_RESOURCE_TYPES, select
Kubernetes Container.Under CLUSTER_NAME, select the name of your user cluster.
Under NAMESPACE_NAME, select
default.Click Add and then click Run Query.
Under Query results, you can see log entries from the
monitoring-exampleDeployment. For example:{ "textPayload": "2020/11/14 01:24:24 Starting to listen on :9090\n", "insertId": "1oa4vhg3qfxidt", "resource": { "type": "k8s_container", "labels": { "pod_name": "monitoring-example-7685d96496-xqfsf", "cluster_name": ..., "namespace_name": "default", "project_id": ..., "location": "us-west1", "container_name": "prometheus-example-exporter" } }, "timestamp": "2020-11-14T01:24:24.358600252Z", "labels": { "k8s-pod/pod-template-hash": "7685d96496", "k8s-pod/app": "monitoring-example" }, "logName": "projects/.../logs/stdout", "receiveTimestamp": "2020-11-14T01:24:39.562864735Z" }
gcloud
Run this command:
gcloud logging read 'resource.labels.project_id="PROJECT_ID" AND \ resource.type="k8s_container" AND resource.labels.namespace_name="default"'Replace PROJECT_ID with the ID of your logging-monitoring project.
In the output, you can see log entries from the
monitoring-exampleDeployment. For example:insertId: 1oa4vhg3qfxidt labels: k8s-pod/app: monitoring-example k8s- pod/pod-template-hash: 7685d96496 logName: projects/.../logs/stdout receiveTimestamp: '2020-11-14T01:24:39.562864735Z' resource: labels: cluster_name: ... container_name: prometheus-example-exporter location: us-west1 namespace_name: default pod_name: monitoring-example-7685d96496-xqfsf project_id: ... type: k8s_container textPayload: | 2020/11/14 01:24:24 Starting to listen on :9090 timestamp: '2020-11-14T01:24:24.358600252Z'
Viewing application metrics in the Google Cloud console
Your example application exposes a custom metric named example_monitoring_up.
You can view the values of that metric in the Google Cloud console.
Go to the Metrics explorer in the Google Cloud console.
For Resource type, select
Kubernetes PodorKubernetes Container.For metric, select
external.googleapis.com/prometheus/example_monitoring_up.In the chart, you can see that
example_monitoring_uphas a repeated value of 1.