Google Distributed Cloud (khusus software) untuk bare metal mendukung beberapa opsi untuk logging dan pemantauan cluster, termasuk layanan terkelola berbasis cloud, alat open source, dan kompatibilitas yang divalidasi dengan solusi komersial pihak ketiga. Halaman ini menjelaskan opsi ini dan memberikan panduan dasar tentang cara memilih solusi yang tepat untuk lingkungan Anda.
Halaman ini ditujukan untuk Admin, arsitek, dan Operator yang ingin memantau kondisi aplikasi atau layanan yang di-deploy, seperti untuk kepatuhan tujuan tingkat layanan (SLO). Untuk mempelajari lebih lanjut peran umum dan contoh tugas yang dirujuk dalam konten Google Cloud , lihat Peran dan tugas pengguna GKE Enterprise umum.
Opsi untuk Google Distributed Cloud
Anda memiliki beberapa opsi logging dan pemantauan untuk cluster:
- Cloud Logging dan Cloud Monitoring, diaktifkan secara default pada komponen sistem bare metal.
- Prometheus dan Grafana tersedia dari Cloud Marketplace.
- Konfigurasi yang divalidasi dengan solusi pihak ketiga.
Cloud Logging dan Cloud Monitoring
Kemampuan Observasi Google Cloud adalah solusi kemampuan observasi bawaan untukGoogle Cloud. Solusi ini menawarkan solusi logging, pengumpulan metrik, pemantauan, dasbor, dan pemberitahuan yang terkelola sepenuhnya. Cloud Monitoring memantau cluster Google Distributed Cloud dengan cara yang mirip dengan cluster GKE berbasis cloud.
Cloud Logging dan Cloud Monitoring diaktifkan secara default saat Anda membuat cluster dengan akun layanan dan peran IAM yang diperlukan. Anda tidak dapat menonaktifkan Cloud Logging dan Cloud Monitoring. Untuk mengetahui informasi selengkapnya tentang akun layanan dan peran yang diperlukan, lihat Mengonfigurasi akun layanan.
Agen dapat dikonfigurasi untuk mengubah hal berikut:
- Cakupan logging dan pemantauan, dari hanya komponen sistem (default) hingga komponen sistem dan aplikasi.
- Tingkat metrik yang dikumpulkan, dari hanya kumpulan metrik yang dioptimalkan (secara default) hingga semua metrik.
Lihat Mengonfigurasi agen Stackdriver untuk Google Distributed Cloud di dokumen ini untuk mengetahui informasi selengkapnya.
Logging dan Monitoring menyediakan satu solusi observabilitas berbasis cloud yang canggih dan mudah dikonfigurasi. Sebaiknya gunakan Logging dan Pemantauan saat menjalankan workload di Google Distributed Cloud. Untuk aplikasi dengan komponen yang berjalan di Google Distributed Cloud dan infrastruktur lokal standar, Anda dapat mempertimbangkan solusi lain untuk mendapatkan tampilan menyeluruh aplikasi tersebut.
Untuk mengetahui detail tentang arsitektur, konfigurasi, dan data yang direplikasi ke project Google Cloud Anda secara default, lihat Cara kerja Logging dan Monitoring untuk Google Distributed Cloud.
Untuk mengetahui informasi selengkapnya tentang Logging, lihat dokumentasi Cloud Logging.
Untuk mengetahui informasi selengkapnya tentang Monitoring, lihat dokumentasi Cloud Monitoring.
Untuk mempelajari cara melihat dan menggunakan metrik penggunaan resource Cloud Monitoring dari Google Distributed Cloud di tingkat fleet, lihat Menggunakan ringkasan edisi Enterprise Google Kubernetes Engine (GKE).
Prometheus dan Grafana
Prometheus dan Grafana adalah dua produk pemantauan open source populer yang tersedia di Cloud Marketplace:
Prometheus mengumpulkan metrik aplikasi dan sistem.
Alertmanager menangani pengiriman pemberitahuan dengan beberapa mekanisme pemberitahuan yang berbeda.
Grafana adalah alat pembuatan dasbor.
Sebaiknya gunakan Google Cloud Managed Service for Prometheus, yang berbasis di Cloud Monitoring, untuk semua kebutuhan pemantauan Anda. Dengan Google Cloud Managed Service for Prometheus, Anda dapat memantau komponen sistem tanpa biaya. Google Cloud Managed Service for Prometheus juga kompatibel dengan Grafana. Namun, jika Anda lebih memilih sistem pemantauan lokal murni, Anda dapat memilih untuk menginstal Prometheus dan Grafana di cluster.
Jika Anda menginstal Prometheus secara lokal dan ingin mengumpulkan metrik dari komponen sistem, Anda harus memberikan izin ke instance Prometheus lokal untuk mengakses endpoint metrik komponen sistem:
Ikat akun layanan untuk instance Prometheus Anda ke ClusterRole
gke-metrics-agentyang telah ditentukan sebelumnya, dan gunakan token akun layanan sebagai kredensial untuk menyalin metrik dari komponen sistem berikut:kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
Gunakan kunci dan sertifikat klien yang disimpan di secret
kube-system/stackdriver-prometheus-etcd-scrapeuntuk mengautentikasi pengambilan metrik dari etcd.Buat NetworkPolicy untuk mengizinkan akses dari namespace Anda ke kube-state-metrics.
Solusi pihak ketiga
Google telah bekerja sama dengan beberapa penyedia solusi logging dan pemantauan pihak ketiga untuk membantu produk mereka berfungsi dengan baik dengan Google Distributed Cloud. Alat ini mencakup Datadog, Elastic, dan Splunk. Pihak ketiga tambahan yang divalidasi akan ditambahkan di masa mendatang.
Panduan solusi berikut tersedia untuk menggunakan solusi pihak ketiga dengan Google Distributed Cloud:
- Memantau Google Distributed Cloud dengan Elastic Stack
- Mengumpulkan log di Google Distributed Cloud dengan Splunk Connect
Cara kerja Logging dan Pemantauan untuk Google Distributed Cloud
Cloud Logging dan Cloud Monitoring diinstal dan diaktifkan di setiap cluster saat Anda membuat cluster admin atau pengguna baru.
Agen Stackdriver menyertakan beberapa komponen di setiap cluster:
Stackdriver Operator (
stackdriver-operator-*). Mengelola siklus proses untuk semua agen Stackdriver lainnya yang di-deploy ke cluster.Resource Kustom Stackdriver. Resource yang dibuat secara otomatis sebagai bagian dari proses penginstalan Google Distributed Cloud.
Agen Metrik GKE (
gke-metrics-agent-*). DaemonSet berbasis OpenTelemetry Collector yang mengambil metrik dari setiap node ke Cloud Monitoring. DaemonSetnode-exporterdan deploymentkube-state-metricsjuga disertakan untuk memberikan lebih banyak metrik tentang cluster.Stackdriver Log Forwarder (
stackdriver-log-forwarder-*). DaemonSet Fluent Bit yang meneruskan log dari setiap mesin ke Cloud Logging. Penerusan log akan menyimpan entri log di node secara lokal dan mengirim ulang log tersebut hingga 4 jam. Jika buffer penuh atau jika Log Forwarder tidak dapat menjangkau Cloud Logging API selama lebih dari 4 jam, log akan dihapus.Metadata Agent (
stackdriver-metadata-agent-). Deployment yang mengirim metadata untuk resource Kubernetes seperti pod, deployment, atau node ke Ops API Config Monitoring. Penambahan metadata ini memungkinkan Anda membuat kueri data metrik menurut nama deployment, nama node, atau bahkan nama layanan Kubernetes.
Anda dapat melihat agen yang diinstal oleh Stackdriver dengan menjalankan perintah berikut:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Output perintah ini akan mirip dengan berikut ini:
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Metrik Cloud Monitoring
Untuk mengetahui daftar metrik yang dikumpulkan oleh Cloud Monitoring, lihat Melihat metrik Google Distributed Cloud.
Mengonfigurasi agen Stackdriver untuk Google Distributed Cloud
Agen Stackdriver yang diinstal dengan Google Distributed Cloud mengumpulkan data tentang komponen sistem untuk tujuan pemeliharaan dan pemecahan masalah pada cluster Anda. Bagian berikut menjelaskan konfigurasi dan mode operasi Stackdriver.
Hanya Komponen Sistem (Mode Default)
Setelah diinstal, agen Stackdriver dikonfigurasi secara default untuk mengumpulkan log dan metrik, termasuk detail performa (misalnya, penggunaan CPU dan memori), dan metadata serupa, untuk komponen sistem yang disediakan Google. Hal ini mencakup semua workload di cluster admin, dan untuk cluster pengguna, workload di namespace kube-system, gke-system, gke-connect, istio-system, dan config-management- system.
Komponen dan Aplikasi Sistem
Untuk mengaktifkan logging dan pemantauan aplikasi di atas mode default, ikuti langkah-langkah di Mengaktifkan logging dan pemantauan aplikasi.
Metrik yang dioptimalkan (Metrik default)
Secara default, deployment kube-state-metrics yang berjalan di cluster mengumpulkan dan melaporkan kumpulan metrik kube yang dioptimalkan ke Google Cloud Observability (sebelumnya Stackdriver).
Lebih sedikit resource yang diperlukan untuk mengumpulkan kumpulan metrik yang dioptimalkan ini, yang meningkatkan performa dan skalabilitas secara keseluruhan.
Untuk menonaktifkan metrik yang dioptimalkan (tidak direkomendasikan), ganti setelan default di resource kustom Stackdriver Anda.
Menggunakan Google Cloud Managed Service for Prometheus untuk komponen sistem yang dipilih
Google Cloud Managed Service for Prometheus adalah bagian dari Cloud Monitoring dan tersedia sebagai opsi untuk komponen sistem. Manfaat Google Cloud Managed Service for Prometheus mencakup hal berikut:
Anda dapat terus menggunakan pemantauan berbasis Prometheus yang ada tanpa mengubah pemberitahuan dan dasbor Grafana.
Jika menggunakan GKE dan Google Distributed Cloud, Anda dapat menggunakan Prometheus Query Language (PromQL) yang sama untuk metrik di semua cluster. Anda juga dapat menggunakan tab PromQL di Metrics Explorer di konsol Google Cloud.
Mengaktifkan dan menonaktifkan Google Cloud Managed Service for Prometheus
Google Cloud Managed Service for Prometheus diaktifkan secara default di Google Distributed Cloud.
Untuk menonaktifkan Google Cloud Managed Service for Prometheus:
Buka objek Stackdriver bernama
stackdriveruntuk mengedit:kubectl --kubeconfig CLUSTER_KUBECONFIG --namespace kube-system \ edit stackdriver stackdriverTambahkan gate fitur
enableGMPForSystemMetrics, dan tetapkan kefalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: featureGates: enableGMPForSystemMetrics: falseTutup sesi pengeditan Anda.
Melihat data metrik
Jika enableGMPForSystemMetrics ditetapkan ke true, metrik untuk komponen
berikut memiliki format yang berbeda untuk cara penyimpanan dan kueri di
Cloud Monitoring:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet dan cadvisor
- kube-state-metrics
- node-exporter
Dalam format baru, Anda dapat membuat kueri metrik sebelumnya menggunakan PromQL atau Monitoring Query Language (MQL):
PromQL
Contoh kueri PromQL:
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
MQL
Untuk menggunakan MQL, tetapkan resource yang dipantau ke prometheus_target, gunakan nama metrik dengan awalan kubernetes.io/anthos, dan tambahkan jenis Prometheus sebagai akhiran ke nama metrik.
fetch prometheus_target
| metric 'kubernetes.io/anthos/apiserver_request_duration_seconds/histogram'
| align delta(5m)
| every 5m
| group_by [], [value_histogram_percentile: percentile(value.histogram, 95)]
Mengonfigurasi dasbor Grafana dengan Google Cloud Managed Service for Prometheus
Untuk menggunakan Grafana dengan data metrik dari Google Cloud Managed Service for Prometheus, Anda
harus terlebih dahulu mengonfigurasi dan mengautentikasi sumber data Grafana. Untuk mengonfigurasi dan
mengautentikasi sumber data, Anda menggunakan sinkroniser sumber data
(datasource-syncer) untuk membuat kredensial OAuth2 dan menyinkronkannya ke Grafana
melalui API sumber data Grafana. Pengsinkron sumber data menetapkan Cloud Monitoring API sebagai URL server Prometheus (nilai URL dimulai dengan https://monitoring.googleapis.com) di bagian sumber data di Grafana.
Ikuti langkah-langkah di Kueri menggunakan Grafana untuk mengautentikasi dan mengonfigurasi sumber data Grafana guna membuat kueri data dari Google Cloud Managed Service for Prometheus.
Kumpulan dasbor Grafana contoh disediakan di repositori anthos-samples di GitHub. Untuk menginstal dasbor contoh, lakukan hal berikut:
Download contoh file JSON:
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Jika sumber data Grafana Anda dibuat dengan nama yang berbeda dengan
Managed Service for Prometheus, ubah kolomdatasourcedi semua file JSON:sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
Ganti [DATASOURCE_NAME] dengan nama sumber data di Grafana yang diarahkan ke layanan
frontendPrometheus.Akses UI Grafana dari browser, lalu pilih + Import di bagian menu Dashboards.
Upload file JSON, atau salin dan tempel konten file, lalu pilih Load. Setelah konten file berhasil dimuat, pilih Impor. Secara opsional, Anda juga dapat mengubah nama dasbor dan UID sebelum mengimpor.
Dasbor yang diimpor akan berhasil dimuat jika Google Distributed Cloud dan sumber data Anda dikonfigurasi dengan benar. Misalnya, screenshot berikut menampilkan dasbor yang dikonfigurasi oleh
cluster-capacity.json.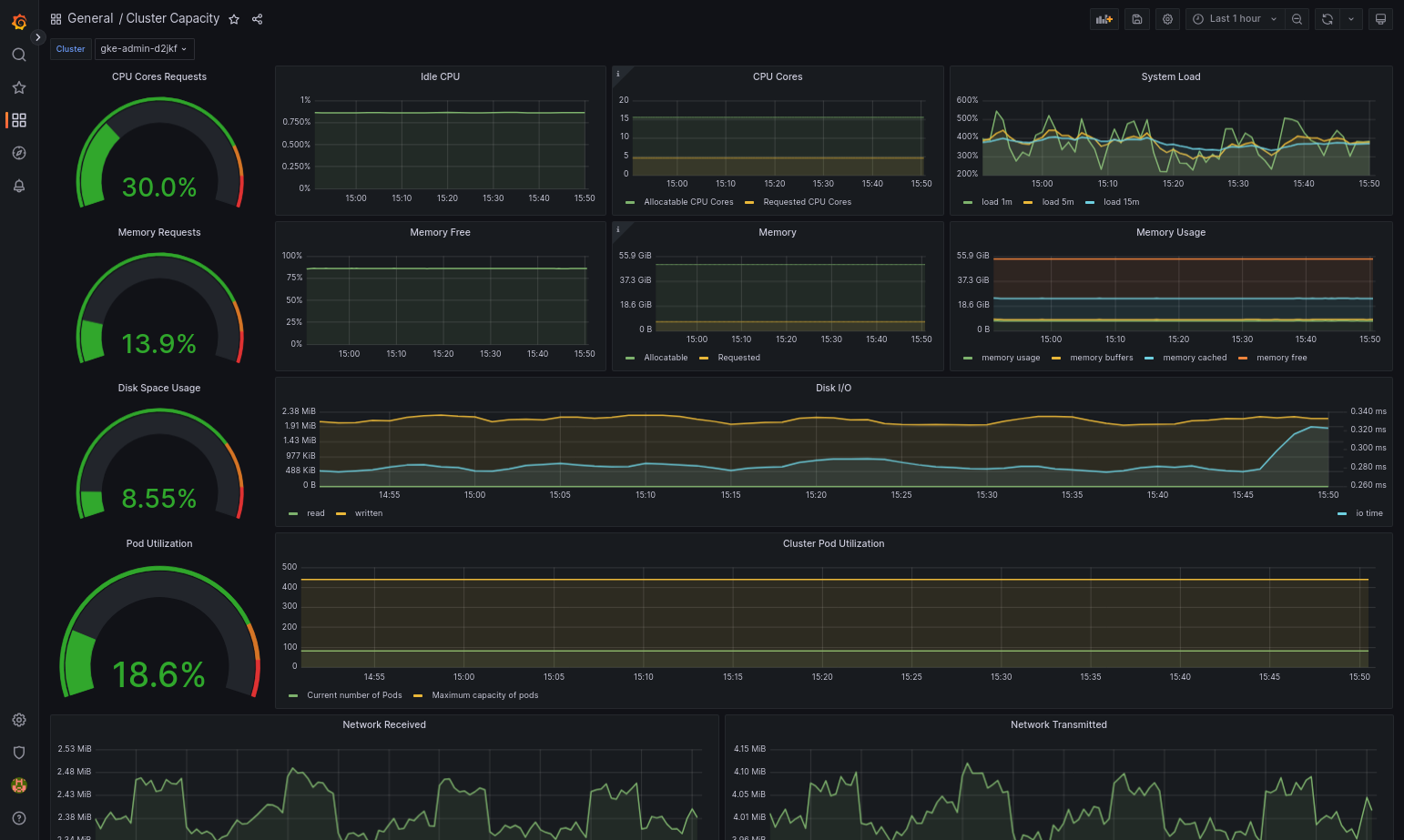
Referensi lainnya
Untuk informasi selengkapnya tentang Google Cloud Managed Service for Prometheus, lihat hal berikut:
Mengonfigurasi resource komponen Stackdriver
Saat Anda membuat cluster, Google Distributed Cloud otomatis membuat resource kustom Stackdriver. Anda dapat mengedit spesifikasi di resource kustom untuk mengganti nilai default untuk permintaan dan batas CPU serta memori untuk komponen Stackdriver, dan Anda dapat mengganti setelan metrik yang dioptimalkan secara default secara terpisah.
Mengganti permintaan dan batas CPU dan memori default untuk komponen Stackdriver
Cluster dengan kepadatan pod yang tinggi akan menyebabkan overhead logging dan pemantauan yang lebih tinggi. Dalam kasus ekstrem, komponen Stackdriver dapat melaporkan mendekati batas penggunaan CPU dan memori atau bahkan dapat mengalami mulai ulang secara konstan karena batas resource. Dalam hal ini, untuk mengganti nilai default untuk permintaan dan batas CPU serta memori untuk komponen Stackdriver, gunakan langkah-langkah berikut:
Jalankan perintah berikut untuk membuka resource kustom Stackdriver di editor command line:
kubectl -n kube-system edit stackdriver stackdriver
Di resource kustom Stackdriver, tambahkan bagian
resourceAttrOverridedi bawah kolomspec:resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYPerhatikan bahwa bagian
resourceAttrOverrideakan menggantikan semua batas dan permintaan default yang ada untuk komponen yang Anda tentukan. Komponen berikut didukung olehresourceAttrOverride:gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
Contoh file terlihat seperti berikut:
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiUntuk menyimpan perubahan pada resource kustom Stackdriver, simpan dan tutup editor command line Anda.
Periksa kondisi Pod Anda:
kubectl -n kube-system get pods -l "managed-by=stackdriver"
Respons untuk Pod yang sehat akan terlihat seperti berikut:
gke-metrics-agent-4th8r 1/1 Running 1 40h
Periksa spesifikasi Pod komponen untuk memastikan resource ditetapkan dengan benar.
kubectl -n kube-system describe pod POD_NAME
Ganti
POD_NAMEdengan nama Pod yang baru saja Anda ubah. Contoh,gke-metrics-agent-4th8r.Responsnya akan terlihat seperti berikut:
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
Menonaktifkan metrik yang dioptimalkan
Secara default, deployment kube-state-metrics yang berjalan di cluster mengumpulkan dan melaporkan kumpulan metrik kube yang dioptimalkan ke Stackdriver. Jika Anda memerlukan metrik tambahan, sebaiknya cari pengganti dari daftar metrik Google Distributed Cloud.
Berikut adalah beberapa contoh penggantian yang dapat Anda gunakan:
| Metrik yang dinonaktifkan | Penggantian |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
Untuk menonaktifkan setelan default metrik yang dioptimalkan (tidak direkomendasikan), lakukan hal berikut:
Buka resource kustom Stackdriver di editor command line:
kubectl -n kube-system edit stackdriver stackdriver
Tetapkan kolom
optimizedMetricskefalse:apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
Simpan perubahan, lalu keluar dari editor command line.
Server Metrik
Server Metrik adalah sumber metrik resource penampung untuk berbagai pipeline penskalaan otomatis. Server Metrik mengambil metrik dari kubelet dan mengeksposnya melalui Kubernetes Metrics API. HPA dan VPA kemudian menggunakan metrik ini untuk menentukan waktu untuk memicu penskalaan otomatis. Server metrik diskalakan menggunakan pengubah ukuran add-on.
Dalam kasus ekstrem saat kepadatan pod yang tinggi menyebabkan overhead logging dan pemantauan yang terlalu banyak, Server Metrik mungkin dihentikan dan dimulai ulang karena keterbatasan resource. Dalam hal ini, Anda dapat mengalokasikan lebih banyak resource ke server metrik dengan mengedit configmap metrics-server-config di namespace gke-managed-metrics-server, dan mengubah nilai untuk cpuPerNode dan memoryPerNode.
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
Contoh konten ConfigMap adalah:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
Setelah mengupdate ConfigMap, buat ulang pod server metrik dengan perintah berikut:
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
Pemilihan rute log dan metrik
Pengirim log Stackdriver (stackdriver-log-forwarder) mengirim log dari setiap mesin node ke Cloud Logging. Demikian pula, agen metrik GKE
(gke-metrics-agent) mengirimkan metrik dari setiap mesin node ke
Cloud Monitoring. Sebelum log dan metrik dikirim, Operator Stackdriver (stackdriver-operator) akan melampirkan nilai dari kolom clusterLocation di resource kustom stackdriver ke setiap entri log dan metrik sebelum dirutekan ke Google Cloud. Selain itu, log dan metrik dikaitkan dengan project Google Cloud yang ditentukan dalam spesifikasi resource kustom stackdriver (spec.projectID).
Resource stackdriver mendapatkan nilai untuk kolom clusterLocation dan projectID
dari kolom
location
dan
projectID
di bagian clusterOperations dari resource Cluster pada waktu pembuatan
cluster.
Semua metrik dan entri log yang dikirim oleh agen stackdriver dirutekan ke endpoint penyerapan global. Dari sana, data diteruskan ke endpoint Google Cloud regional terdekat yang dapat dijangkau untuk memastikan keandalan transpor data.
Setelah endpoint global menerima entri metrik atau log, hal yang terjadi selanjutnya bergantung pada layanan:
Cara pemilihan rute log dikonfigurasi: saat endpoint logging menerima pesan log, Cloud Logging akan meneruskan pesan tersebut melalui Router Log. Penampung dan filter dalam konfigurasi Log Router menentukan cara merutekan pesan. Anda dapat merutekan entri log ke tujuan seperti bucket Logging regional, yang menyimpan entri log, atau ke Pub/Sub. Untuk mengetahui informasi selengkapnya tentang cara kerja pemilihan rute log dan cara mengonfigurasinya, lihat Ringkasan pemilihan rute dan penyimpanan.
Kolom
clusterLocationdi resource kustomstackdriveratau kolomclusterOperations.locationdalam spesifikasi Cluster tidak dipertimbangkan dalam proses pemilihan rute ini. Untuk log,clusterLocationhanya digunakan untuk memberi label pada entri log, yang dapat membantu pemfilteran di Logs Explorer.Cara konfigurasi perutean metrik: saat endpoint metrik menerima entri metrik, entri akan dirutekan secara otomatis untuk disimpan di lokasi yang ditentukan oleh metrik. Lokasi dalam metrik berasal dari kolom
clusterLocationdi resource kustomstackdriver.Rencanakan konfigurasi Anda: saat Anda mengonfigurasi Cloud Logging dan Cloud Monitoring, konfigurasikan Router Log dan tentukan
clusterOperations.locationyang sesuai dengan lokasi yang paling mendukung kebutuhan Anda. Misalnya, jika Anda ingin log dan metrik dikirim ke lokasi yang sama, tetapkanclusterOperations.locationke region Google Cloud yang sama dengan yang digunakan Log Router untuk project Google Cloud Anda.Perbarui konfigurasi log jika diperlukan: Anda dapat melakukan perubahan kapan saja pada setelan tujuan untuk log karena persyaratan bisnis, seperti disaster recovery plan. Perubahan pada konfigurasi Log Router di Google Cloud akan segera diterapkan. Kolom
locationdanprojectIDdi bagianclusterOperationsdari resource Cluster tidak dapat diubah, sehingga tidak dapat diperbarui setelah Anda membuat cluster. Sebaiknya Anda tidak mengubah nilai di resourcestackdriversecara langsung. Resource ini akan dikembalikan ke status pembuatan cluster awal setiap kali operasi cluster, seperti upgrade, memicu rekonsiliasi.
Persyaratan konfigurasi untuk Logging dan Pemantauan
Ada beberapa persyaratan konfigurasi untuk mengaktifkan Cloud Logging dan Cloud Monitoring dengan Google Distributed Cloud. Langkah-langkah ini disertakan dalam Mengonfigurasi akun layanan untuk digunakan dengan Logging dan Pemantauan di halaman Mengaktifkan layanan Google, dan dalam daftar berikut:
- Ruang Kerja Cloud Monitoring harus dibuat dalam project Google Cloud. Hal ini dilakukan dengan mengklik Monitoring di Konsol Google Cloud dan mengikuti alur kerja.
Anda perlu mengaktifkan Stackdriver API berikut:
Anda perlu menetapkan peran IAM berikut ke akun layanan yang digunakan oleh agen Stackdriver:
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
Tag log
Banyak log Google Distributed Cloud memiliki tag F:
logtag: "F"
Tag ini berarti bahwa entri log sudah selesai atau penuh. Untuk mempelajari tag ini lebih lanjut, lihat Format log dalam proposal desain Kubernetes di GitHub.
Harga
Log dan metrik sistem Google Kubernetes Engine (GKE) edisi Enterprise tidak dikenai biaya.
Dalam cluster Google Distributed Cloud, log dan metrik sistem edisi Enterprise Google Kubernetes Engine (GKE) mencakup:
- Log dan metrik dari semua komponen dalam cluster admin.
- Log dan metrik dari komponen dalam namespace ini di cluster pengguna:
kube-system,gke-system,gke-connect,knative-serving,istio-system,monitoring-system,config-management-system,gatekeeper-system,cnrm-system.
Untuk mengetahui informasi selengkapnya, lihat Harga untuk Google Cloud Observability.
Untuk mempelajari kredit untuk metrik Cloud Logging, hubungi tim penjualan untuk mengetahui harga.