本页面的内容帮助您以此为起点,规划和设计 Kubernetes 的 CI/CD GitOps 流水线。GitOps 以及 Config Sync 等工具可提供以下优势:提高代码稳定性、提高可读性和加强自动化。
GitOps 是一种快速发展的方法,用于大规模管理 Kubernetes 配置。您可以根据对 CI/CD 流水线的要求,选择多种应用和配置代码架构和整理方式。通过学习一些 GitOps 最佳实践,您可以构建稳定、井井有条且安全的架构。
本页面适用于希望在环境中实现 GitOps 的管理员、架构师和运维人员。如需详细了解我们在 Google Cloud 内容中提及的常见角色和示例任务,请参阅常见的 GKE 用户角色和任务。
整理代码库
设置 GitOps 架构时,请根据存储在每个代码库中的配置文件类型来分隔代码库。概括来讲,您可能至少需要考虑以下四种类型的代码库:
- 相关配置组的 Package Repository。
- 用于存储集群和命名空间的舰队级配置的平台代码库。
- 应用配置库。
- 应用代码库。
下图展示了这些库的布局:
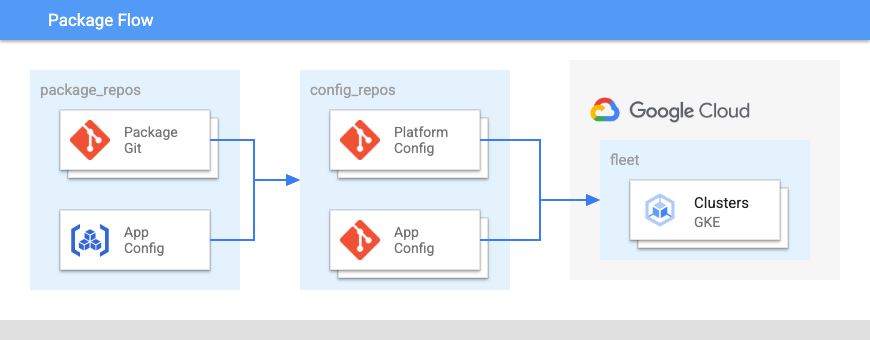
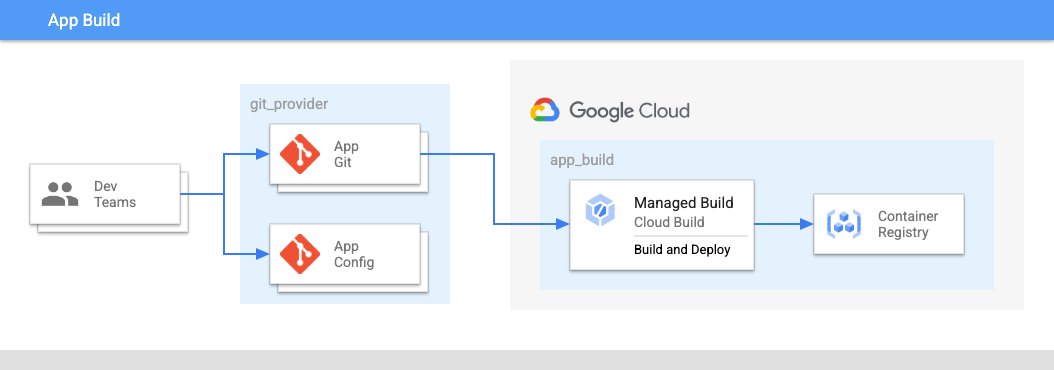
在图 2 中:
- 开发团队将应用代码和应用配置推送到库中。
- 应用和配置的代码均存储在同一个位置,应用团队可以控制这些库。
- 应用团队将代码推送到某个 build 中。
使用集中式私有 Package Repository
使用存储公共或内部软件包(如 Helm 图表)的中央代码库可帮助团队找到软件包。例如,如果代码库的结构是逻辑结构或包含 readme,使用集中式私有软件包库可帮助团队快速找到信息。您可以使用 Artifact Registry 或 Git Repositories 等服务来整理您的中心代码库。
例如,贵组织的平台团队可以实行政策,要求应用团队只能使用中央代码库中的软件包。
您只能向少数工程师授予对代码库的写入权限。组织的其余部分可以授予读取权限。我们建议您实现将软件包提升到中央代码库并广播更新的流程。
虽然管理中央代码库可能会增加一些额外的开销,因为必须有人维护中央代码库,并且它会为应用团队增加额外的流程,但这种方法有很多好处:
- 中央团队可以选择按定义的节奏添加公共软件包,这有助于避免因连接或上游停用问题而产生中断。
- 在广泛提供软件包之前,自动化系统和人工审核者可以检查软件包是否存在问题。
- 中央代码库为团队提供了一种方式,让他们可以了解正在使用和支持的内容。例如,团队可以找到存储在中央代码库中的标准 Redis 部署。
- 您可以自动更改上游软件包,以确保它们符合默认值、添加标签和容器映像库等内部标准。
创建 WET 代码库
WET 代表“Write Everything Twice”(写入所有内容两次)。与之形成对比的是 DRY,它代表“Don't Repeat Yourself”(不要重复)。这些方法代表了两种不同的配置文件:
- DRY 配置,其中单个配置文件会执行转换操作,以便为不同环境的字段填充不同的值。例如,您可以使用共享集群配置,为不同的环境填充不同的区域或不同的安全设置。
- WET(有时称为“完全水合”)配置,其中每个配置文件都代表最终状态。
虽然 WET 代码库可能会导致一些重复的配置文件,但对于 GitOps 工作流,它具有以下优势:
- 团队成员可以更轻松地审核更改。
- 无需处理即可查看配置文件的预期状态。
在验证配置时尽早进行测试
等待 Config Sync 开始同步以检查是否存在问题可能会导致不必要的 Git 提交和冗长的反馈循环。使用 kpt 验证器函数,在将配置应用于集群之前,可以发现许多问题。
虽然您必须在提交流程中添加其他工具和逻辑,但在应用配置之前进行测试具有以下优势:
- 在更改请求中显示配置更改有助于防止错误进入代码库。
- 减少问题在共享配置中的影响。
使用文件夹取代分支
针对配置文件的变体使用文件夹,而不是分支。对于文件夹,您可以使用 tree 命令查看变体。使用分支时,您无法确定生产分支和开发分支之间的增量是即将发生的配置更改,还是 prod 和 dev 环境应有的永久性差异。
这种方法的主要缺点是,使用文件夹无法让您使用更改请求将配置更改提升到同一文件。不过,使用文件夹而非分支具有以下优势:
- 文件夹比分支更容易浏览。
- 使用许多 CLI 和 GUI 工具都可以对文件夹执行差异比较,而分支差异比较在 Git 提供商之外不太常见。
- 使用文件夹可以更轻松地区分永久差异和未提升的差异。
- 您可以在一个更改请求中向多个集群和命名空间部署更改,而分支需要向不同的分支发出多个更改请求。
尽可能减少使用 ClusterSelectors
借助 ClusterSelectors,您可以将配置的某些部分应用于部分集群。您可以改为修改应用的资源或向集群添加标签,而不是配置 RootSync 或 RepoSync 对象。虽然这是向集群添加特征的轻量级方法,但随着 ClusterSelectors 数量的不断增加,理解集群的最终状态可能会变得很复杂。
因为 Config Sync 允许您同时同步多个 RootSync 和 RepoSync 对象,所以您可以将相关配置添加到单独的代码库,然后将其同步到所需的集群。这样可以更轻松地了解集群的最终状态,并且您可以将集群的配置组合到文件夹中,而不是直接在集群上应用这些配置决策。
避免使用 Config Sync 管理作业
在大多数情况下,作业和其他情境性任务应由处理其生命周期管理的服务进行管理。然后,您可以使用 Config Sync 管理该服务,而不是管理作业本身。
虽然 Config Sync 可以为您应用作业,但作业并不适合 GitOps 部署,原因如下:
不可变字段:许多作业字段不可变。如需更改不可变字段,必须删除并重新创建对象。不过,除非您从来源中移除对象,否则 Config Sync 不会删除对象。
意外运行作业:如果您使用 Config Sync 同步作业,然后从集群中删除该作业,Config Sync 会将其视为偏离您选择的状态,并重新创建该作业。如果您指定了作业存留时间 (TTL),Config Sync 会自动删除作业,并自动重新创建和重启作业,直到您从可靠来源中删除作业为止。
协调问题:Config Sync 通常会等待对象在应用后进行协调。不过,作业在开始运行时会被视为已协调。这意味着,Config Sync 无需等待作业完成,即可继续应用其他对象。但是,如果作业稍后失败,则会被视为协调失败。在某些情况下,这可能会阻止其他资源同步,并在您修复问题之前导致错误。在其他情况下,同步可能会成功,而仅协调操作失败。
因此,我们不建议将作业与 Config Sync 同步。
使用非结构化代码库
Config Sync 支持两种组织代码库的结构:非结构化和分层。
建议使用非结构化方法,因为它可以让您以最方便的方式组织代码库。相比之下,分层代码库会强制采用特定结构,例如在 cluster 目录中使用自定义资源定义 (CRD)。在您需要共享配置时,这可能会导致出现问题。例如,如果一个团队发布包含 CRD 的软件包,则另一个需要使用该软件包的团队必须将 CRD 移至 cluster 目录,从而增加了流程的开销。
使用非结构化代码库后,共享和重复使用配置软件包会变得更加容易。但是,如果没有明确的流程或代码库整理准则,代码库结构可能因团队而异,因此更难以实现舰队级工具。
如需了解如何转换分层代码库,请参阅将分层代码库转换为非结构化代码库。
分离代码库和配置库
在单库扩容时,每个文件夹都需要一个特定的构建。处理代码的人员和处理集群配置的人员的权限和关注点通常不同。
分离代码库和配置库具有以下优势:
- 避免“循环”提交。例如,提交到代码库可能会触发 CI 请求,这可能会生成映像,然后需要提交代码。
- 所需提交的数量可能会成为团队成员的负担。
- 您可以为处理应用代码和集群配置的人员使用不同的权限。
分离代码库和配置库有以下缺点:
- 减少应用配置的发现,因为它与应用代码不在同一库中。
- 管理多个库可能非常耗时。
使用单独的库隔离更改
在单库扩容时,需要对不同文件夹拥有不同的权限。因此,分离库可以在安全性、平台和应用配置之间实现安全边界。将生产库和非生产库分开也是一个好方法。
虽然管理多个代码库本身就是一项繁重的工作,但将不同类型的配置隔离在不同的代码库中具有以下优势:
- 在拥有平台、安全和应用团队的组织中,更改的节奏和权限有所不同。
- 权限保留在代码库级层。
CODEOWNERS文件让组织可以限制写入权限,同时仍允许读取权限。 - Config Sync 支持每个命名空间进行多次同步,这可实现与从多个代码库中提取文件类似的效果。
固定软件包版本
无论是使用 Helm 还是 Git,您都应将配置软件包版本固定到一些没有明确发布就不会意外推进的对象上。
虽然这会在更新共享配置时对您的发布作业进行额外检查,但会降低共享更新对预期影响更大的风险。
使用 Workload Identity Federation for GKE
您可以在 GKE 集群上启用 Workload Identity Federation for GKE,以允许 Kubernetes 工作负载以安全且可管理的方式访问 Google 服务。
虽然某些非Google Cloud 服务(例如 GitHub 和 GitLab)不支持 Workload Identity Federation for GKE,但您应尽可能尝试使用 Workload Identity Federation for GKE,因为这样可以提高安全性并降低管理 Secret 和密码的复杂性。