Esta página oferece um ponto de partida para ajudar a planear e criar pipelines de CI/CD GitOps para o Kubernetes. O GitOps, juntamente com ferramentas como o Config Sync, oferece vantagens como uma estabilidade do código melhorada, uma melhor legibilidade e automatização.
O GitOps é uma abordagem de crescimento rápido para gerir a configuração do Kubernetes em grande escala. Consoante os seus requisitos para o pipeline de CI/CD, existem muitas opções para a forma como cria a arquitetura e organiza o código da aplicação e de configuração. Ao aprender algumas práticas recomendadas de GitOps, pode criar uma arquitetura estável, bem organizada e segura.
Esta página destina-se a administradores, arquitetos e operadores que querem implementar o GitOps no respetivo ambiente. Para saber mais sobre as funções comuns e exemplos de tarefas que referimos no Google Cloud conteúdo, consulte Funções e tarefas comuns do utilizador do GKE.
Organize os seus repositórios
Ao configurar a sua arquitetura GitOps, separe os repositórios com base nos tipos de ficheiros de configuração armazenados em cada repositório. Em termos gerais, pode considerar, pelo menos, quatro tipos de repositórios:
- Um repositório de pacotes para grupos de configurações relacionadas.
- Um repositório de plataformas para configuração ao nível da frota para clusters e espaços de nomes.
- Um repositório de configuração de aplicações.
- Um repositório de código de aplicação.
O diagrama seguinte mostra o esquema destes repositórios:
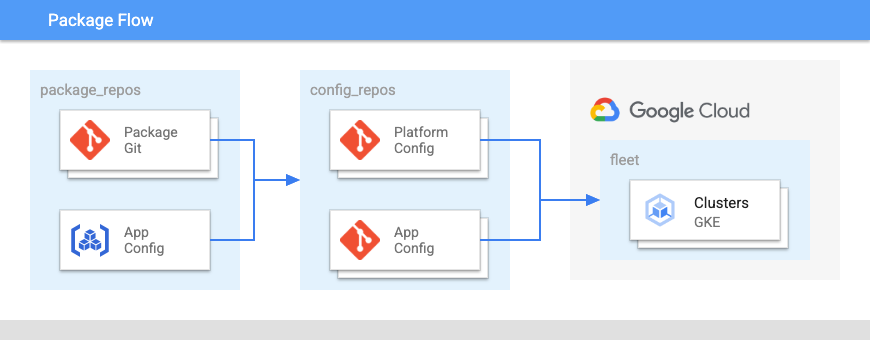

Na Figura 2:
- As equipas de desenvolvimento enviam código para aplicações e configurações de aplicações para um repositório.
- O código das apps e das configurações é armazenado no mesmo local e as equipas de aplicações têm controlo sobre estes repositórios.
- As equipas de aplicações enviam código para uma compilação.
Use um repositório de pacotes privado e centralizado
Use um repositório central para pacotes públicos ou internos, como gráficos Helm,para ajudar as equipas a encontrar pacotes. Por exemplo, se o repositório estiver estruturado logicamente ou contiver um readme, a utilização de repositórios de pacotes privados centralizados pode ajudar as equipas a encontrar rapidamente informações. Pode usar serviços como o Artifact Registry ou os repositórios Git para organizar o seu repositório central.
Por exemplo, a equipa da plataforma da sua organização pode implementar políticas em que as equipas de aplicações só podem usar pacotes do repositório central.
Pode limitar as autorizações de escrita ao repositório apenas a um pequeno número de engenheiros. O resto da organização pode ter acesso de leitura. Recomendamos que implemente um processo para promover pacotes no repositório central e transmitir atualizações.
Embora a gestão de um repositório central possa adicionar alguma sobrecarga adicional, uma vez que alguém tem de manter o repositório central, e adiciona um processo adicional para as equipas de aplicações, esta abordagem tem muitas vantagens:
- Uma equipa central pode optar por adicionar pacotes públicos a uma cadência definida, o que ajuda a evitar que sejam interrompidos por problemas de conetividade ou rotatividade a montante.
- Uma combinação de revisores humanos e automáticos pode verificar se existem problemas nos pacotes antes de os disponibilizar amplamente.
- O repositório central oferece uma forma de as equipas descobrirem o que está em utilização e é suportado. Por exemplo, as equipas podem encontrar a implementação padrão do Redis armazenada no repositório central.
- Pode automatizar as alterações aos pacotes a montante para garantir que cumprem as normas internas, como valores predefinidos, adição de etiquetas e repositórios de imagens de contentores.
Crie repositórios WET
WET significa "Write Everything Twice" (Escrever tudo duas vezes). Contrasta com DRY, que significa "Não se repita". Estas abordagens representam dois tipos diferentes de ficheiros de configuração:
- Configurações DRY, em que um único ficheiro de configuração é submetido a uma ação de transformação para preencher campos com valores diferentes para diferentes ambientes. Por exemplo, pode ter uma configuração de cluster partilhada que é preenchida com uma região diferente ou definições de segurança diferentes para ambientes diferentes.
- Configurações WET (ou, por vezes, "totalmente hidratadas"), em que cada ficheiro de configuração é representativo do estado final.
Embora os repositórios WET possam originar alguns ficheiros de configuração repetidos, têm as seguintes vantagens para um fluxo de trabalho GitOps:
- É mais fácil para os membros da equipa reverem as alterações.
- Não é necessário processamento para ver o estado pretendido de um ficheiro de configuração.
Teste mais cedo ao validar as configurações
Aguardar até que o Config Sync comece a sincronizar para verificar se existem problemas pode criar commits do Git desnecessários e um longo ciclo de feedback. Pode encontrar muitos problemas
antes de aplicar uma configuração a um cluster através das kptfunções de validação.
Embora tenha de adicionar ferramentas e lógica adicionais ao processo de confirmação, os testes antes de aplicar as configurações têm as seguintes vantagens:
- A apresentação de alterações de configuração num pedido de alteração pode ajudar a evitar que os erros sejam incluídos num repositório.
- Reduz o impacto de problemas em configurações partilhadas.
Use pastas em vez de ramificações
Use pastas para variantes de ficheiros de configuração em vez de ramificações. Com as pastas, pode usar o comando tree para ver as variantes. Com as ramificações, não pode saber se a diferença entre uma ramificação de produção e de desenvolvimento é uma alteração de configuração futura ou uma diferença permanente entre o aspeto dos ambientes prod e dev.
A principal desvantagem desta abordagem é que a utilização de pastas não lhe permite promover alterações de configuração através de um pedido de alteração para os mesmos ficheiros. No entanto, a utilização de pastas em vez de ramificações tem as seguintes vantagens:
- A descoberta de pastas é mais fácil do que a de ramificações.
- A comparação de pastas é possível com muitas ferramentas de CLI e GUI, enquanto a comparação de ramificações é menos comum fora dos fornecedores do Git.
- A diferenciação entre diferenças permanentes e não promovidas é mais fácil com pastas.
- Pode implementar alterações em vários clusters e espaços de nomes num único pedido de alteração, enquanto os ramos requerem vários pedidos de alteração a ramos diferentes.
Minimize a utilização de ClusterSelectors
ClusterSelectors permitem-lhe aplicar determinadas partes de uma configuração a um subconjunto de clusters. Em vez de configurar um objeto RootSync ou RepoSync,
pode modificar o recurso que está a ser aplicado ou adicionar etiquetas
aos clusters. Embora seja uma forma simples de adicionar caraterísticas a um cluster, à medida que o número de ClusterSelectors aumenta ao longo do tempo, pode tornar-se complicado compreender o estado final do cluster.
Uma vez que a sincronização de configuração permite sincronizar vários objetos RootSync e RepoSync de uma só vez, pode adicionar a configuração relevante a um repositório separado e, em seguida, sincronizá-la com os clusters pretendidos. Isto facilita a compreensão do estado final do cluster e permite reunir as configurações do cluster numa pasta em vez de aplicar essas decisões de configuração diretamente no cluster.
Evite gerir tarefas com o Config Sync
Na maioria dos casos, os trabalhos e outras tarefas situacionais devem ser geridos por um serviço que processa a respetiva gestão do ciclo de vida. Em seguida, pode gerir esse serviço com o Config Sync, em vez dos próprios trabalhos.
Embora a sincronização de configuração possa aplicar tarefas por si, as tarefas não são adequadas para implementações de GitOps pelos seguintes motivos:
Campos imutáveis: muitos campos de emprego são imutáveis. Para alterar um campo imutável, o objeto tem de ser eliminado e recriado. No entanto, o Config Sync não elimina o seu objeto, a menos que o remova da origem.
Execução não intencional de tarefas: se sincronizar uma tarefa com o Config Sync e, em seguida, essa tarefa for eliminada do cluster, o Config Sync considera que existe uma derivação do estado escolhido e recria a tarefa. Se especificar um tempo de vida (TTL) da tarefa, o Config Sync elimina automaticamente a tarefa e volta a criar e reiniciar a tarefa até a eliminar da fonte de verdade.
Problemas de reconciliação: normalmente, o Config Sync aguarda a reconciliação dos objetos após a aplicação. No entanto, as tarefas são consideradas reconciliadas quando começam a ser executadas. Isto significa que o Config Sync não aguarda a conclusão da tarefa antes de continuar a aplicar outros objetos. No entanto, se a tarefa falhar mais tarde, isso é considerado uma falha na conciliação. Em alguns casos, isto pode impedir a sincronização de outros recursos e causar erros até que corrija o problema. Noutros casos, a sincronização pode ser bem-sucedida e apenas a conciliação falha.
Por estes motivos, não recomendamos a sincronização de trabalhos com o Config Sync.
Use repositórios não estruturados
A Sincronização de configurações suporta duas estruturas para organizar um repositório: não estruturada e hierárquica.
A abordagem não estruturada é a recomendada porque
permite organizar um repositório da forma mais conveniente para si.
Em comparação, os repositórios hierárquicos aplicam uma estrutura específica, como as definições de recursos personalizados (CRDs) num diretório cluster.
Isto pode causar problemas quando precisa de partilhar configurações. Por exemplo, se uma equipa publicar um pacote que contenha um CRD, outra equipa que precise de usar esse pacote teria de mover o CRD para um diretório cluster, adicionando mais sobrecarga ao processo.
Ao usar um repositório não estruturado, torna-se muito mais fácil partilhar e reutilizar pacotes de configuração. No entanto, sem um processo ou diretrizes definidos para organizar repositórios, as estruturas dos repositórios podem variar entre equipas, o que pode dificultar a implementação de ferramentas ao nível da frota.
Para saber como converter um repositório hierárquico, consulte o artigo Converta um repositório hierárquico num repositório não estruturado.
Repositórios de código e de configuração separados
Quando aumenta a escala de um repositório único, é necessária uma compilação específica para cada pasta. Geralmente, as autorizações e as preocupações das pessoas que trabalham no código e na configuração do cluster são diferentes.
A separação dos repositórios de código e de configuração tem as seguintes vantagens:
- Evita commits "em ciclo". Por exemplo, confirmar um repositório de código pode acionar um pedido de CI, que pode produzir uma imagem, que requer uma confirmação de código.
- O número de commits necessários pode tornar-se um fardo para os membros da equipa que contribuem.
- Pode usar diferentes autorizações para pessoas que trabalham no código da aplicação e na configuração do cluster.
A separação dos repositórios de código e de configuração tem as seguintes desvantagens:
- Reduz a deteção da configuração da aplicação, uma vez que não está no mesmo repositório que o código da aplicação.
- A gestão de muitos repositórios pode ser demorada.
Use repositórios separados para isolar as alterações
Quando aumenta a escala de um repositório único, são necessárias autorizações diferentes em pastas diferentes. Por este motivo, a separação dos repositórios permite limites de segurança entre a segurança, a plataforma e a configuração da aplicação. Também é aconselhável separar os repositórios de produção e não produção.
Embora a gestão de muitos repositórios possa ser uma tarefa grande por si só, o isolamento de diferentes tipos de configuração em diferentes repositórios tem as seguintes vantagens:
- Numa organização com equipas de plataforma, segurança e aplicações, a cadência de alterações e autorizações é diferente.
- As autorizações permanecem ao nível do repositório.
CODEOWNERSficheiros permitem que as organizações limitem a autorização de escrita, ao mesmo tempo que continuam a permitir a autorização de leitura. - O Config Sync suporta várias sincronizações por espaço de nomes, o que pode alcançar um efeito semelhante ao da obtenção de ficheiros de vários repositórios.
Fixe versões de pacotes
Quer use o Helm ou o Git, deve fixar a versão do pacote de configuração a algo que não seja movido acidentalmente para a frente sem uma implementação explícita.
Embora isto adicione verificações adicionais às implementações quando uma configuração partilhada é atualizada, reduz o risco de as atualizações partilhadas terem um impacto maior do que o pretendido.
Use a federação de identidades de cargas de trabalho para o GKE
Pode ativar a Federação do Workload Identity para o GKE em clusters do GKE, o que permite que as cargas de trabalho do Kubernetes acedam aos serviços Google de uma forma segura e gerível.
Embora alguns serviços não pertencentes àGoogle Cloud Google, como o GitHub e o GitLab, não suportem a Workload Identity Federation para o GKE, deve tentar usar a Workload Identity Federation para o GKE sempre que possível devido ao aumento da segurança e à redução da complexidade da gestão de segredos e palavras-passe.