This page provides a starting point to help you plan and architect CI/CD GitOps pipelines for Kubernetes. GitOps, along with tools like Config Sync, offers benefits like improved code stability, better readability, and automation.
GitOps is a fast-growing approach for managing Kubernetes configuration at scale. Depending on your requirements for your CI/CD pipeline, there are many options for how you architect and organize your application and configuration code. By learning some GitOps best practices, you can create a stable, well organized, and secure architecture.
This page is for Admins and architects and Operators who want to implement GitOps in their environment. To learn more about common roles and example tasks that we reference in Google Cloud content, see Common GKE user roles and tasks.
Organize your repositories
When setting up your GitOps architecture, separate your repositories based on the types of configuration files stored in each repository. At a high level, you might consider at least four types of repositories:
- A package repository for groups of related configurations.
- A platform repository for fleet-wide configuration for clusters and namespaces.
- An application configuration repository.
- An application code repository.
The following diagram shows the layout of these repositories:
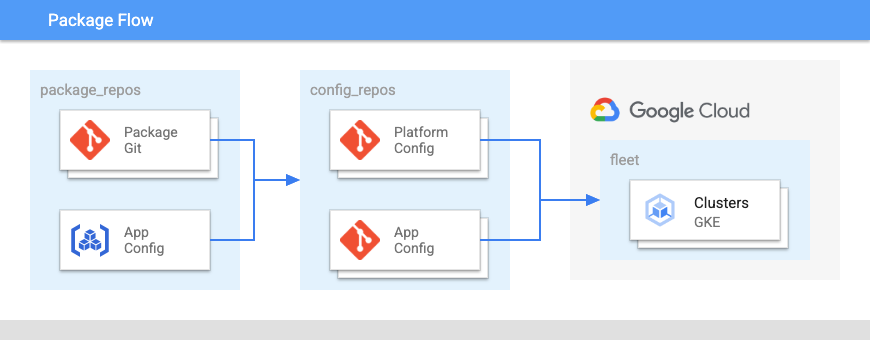
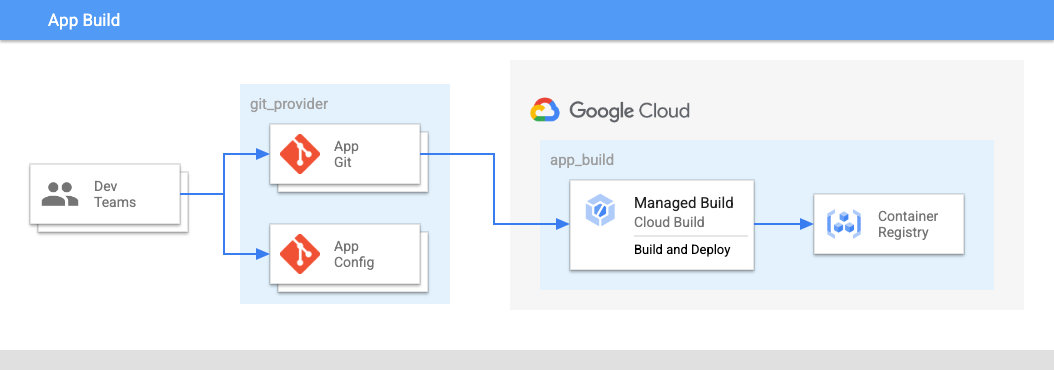
In Figure 2:
- The development teams push code for applications and application configurations into a repository.
- The code for both apps and configs is stored in the same place and application teams have control over these repositories.
- The application teams push code into a build.
Use a centralized, private package repository
Use a central repository for public or internal packages, such as Helm charts,to
help teams find packages. For example, if the repository is
structured logically or contains a readme, using centralized, private package
repositories can help teams quickly find information. You can use services like
Artifact Registry or Git repositories to organize your central repository.
For example, your organization's platform team can implement policies where application teams can use packages only from the central repository.
You can limit write permissions to the repository to only a small number of engineers. The rest of the organization can have read access. We recommend implementing a process for promoting packages into the central repository and broadcasting updates.
Although managing a central repository can add some additional overhead since someone must maintain the central repository, and it adds additional process for application teams, there are many benefits to this approach:
- A central team can choose to add public packages at a defined cadence, which helps avoid getting broken by connectivity or upstream churn.
- A combination of automated and human reviewers can check packages for issues before making them widely available.
- The central repository provides a way for teams to discover what is in use and supported. For example, teams can find the standard Redis deployment stored in the central repository.
- You can automate changes to upstream packages to ensure that they meet internal standards such as default values, adding labels, and container image repositories.
Create WET repositories
WET stands for "Write Everything Twice". It contrasts with DRY, which stands for "Don't Repeat Yourself". These approaches represent two different kinds of configuration files:
- DRY configs, where a single, configuration file undergoes a transform action to populate fields with different values for different environments. For example, you could have a shared cluster configuration that populates with a different region or different security settings for different environments.
- WET (or sometimes, "fully-hydrated") configs, where each configuration file is representative of the end state.
Although WET repositories can lead to some repeated configuration files, it has the following benefits for a GitOps workflow:
- It's easier for team members to review changes.
- There's no processing required to see the intended state of a configuration file.
Test earlier when validating configs
Waiting until Config Sync starts syncing to check for issues can create
unnecessary Git commits and a long feedback loop. Many issues can be found
before a config is applied to a cluster by using kpt validator functions.
Although you must add additional tools and logic to your commit process, testing before applying configs has the following benefits:
- Surfacing config changes in a change request can help prevent errors from making it into a repository.
- Reduces the impact of issues in shared configurations.
Use folders instead of branches
Use folders for variants of configuration files instead of branches. With
folders, you can use the tree command to see variants. With branches, you
can't tell if the delta between a production and development branch is an
upcoming change in configuration or a permanent difference between what the
prod and dev environments should look like.
The main downside of this approach is that using folders doesn't let you promote config changes using a change request to the same files. However, using folders instead of branches has the following benefits:
- Discovery of folders is easier than branches.
- Doing a diff on folders is possible with many CLI and GUI tools, while branch diff is less common outside of Git providers.
- Differentiating between permanent differences and unpromoted differences is easier with folders.
- You can deploy changes to multiple clusters and namespaces in one change request whereas branches require several change requests to different branches.
Minimize use of ClusterSelectors
ClusterSelectors let you apply certain parts of a
configuration to a subset of clusters. Instead of configuring a RootSync or RepoSync object,
you can instead modify either the resource that is being applied or add labels
to the clusters. Although this is a lightweight way to add traits to a cluster,
as the number of ClusterSelectors grows over time, it can become complicated
to understand the final state of the cluster.
Since Config Sync lets you sync multiple RootSync and RepoSync objects
at once, you can add the relevant configuration to a separate repository and
then sync it to the clusters you want. This makes it easier to understand the
final state of the cluster and you can assemble the configurations for the
cluster into a folder instead of applying those configuration decisions directly
on the cluster.
Avoid managing Jobs with Config Sync
In most cases, Jobs and other situational tasks should be managed by a service that handles their lifecycle management. You can then manage that service with Config Sync, instead of the Jobs themselves.
While Config Sync can apply Jobs for you, Jobs are not well suited for GitOps deployments for the following reasons:
Immutable fields: Many Job fields are immutable. To change an immutable field, the object must be deleted and recreated. However, Config Sync doesn't delete your object unless you remove it from the source.
Unintended running of Jobs: If you sync a Job with Config Sync and then that Job is deleted from the cluster, Config Sync considers that drift from your chosen state and re-creates the Job. If you specify a Job time to live (TTL), Config Sync automatically deletes the Job and automatically re-creates and restarts the Job, until you delete the Job from the source of truth.
Reconciliation issues: Config Sync normally waits for objects to reconcile after being applied. However, Jobs are considered reconciled when they have started running. This means that Config Sync doesn't wait for the Job to complete before continuing to apply other objects. However, if the Job later fails, that is considered a failure to reconcile. In some cases, this can block other resources from being synced and cause errors until you fix it. In other cases, the syncing might succeed and only reconciling fails.
For these reasons, we don't recommend syncing Jobs with Config Sync.
Use unstructured repositories
Config Sync supports two structures for organizing a repository: unstructured and hierarchical.
Unstructured is the recommended approach because
it lets you organize a repository in a way that's most convenient for you.
Hierarchical repositories, by comparison, enforce a specific structure like
Custom Resource Definitions (CRDs) in a cluster directory.
This can cause issues when you need to share configs. For example, if one team
publishes a package that contains a CRD, another team that needs to use that
package would have to move the CRD into a cluster directory, adding more
overhead to the process.
By using an unstructured repository, it becomes much easier to share and reuse configuration packages. However, without a defined process or guidelines for organizing repositories, repository structures can vary across teams which can make it harder to implement fleet-wide tools.
To learn how to convert a hierarchical repository, see Convert a hierarchical repository to an unstructured repository.
Separate code and config repositories
When scaling up a mono-repository, it requires a build specific to each folder. Permissions and concerns for people working on the code and working on the cluster configuration are generally different.
Separating code and config repositories has the following benefits:
- Avoids "looping" commits. For example, committing to a code repository might trigger a CI request, which might produce an image, which then requires a code commit.
- The number of commits required can become a burden to team members contributing.
- You can use different permissions for people working on application code and cluster configuration.
Separating code and config repositories has the following downsides:
- Reduces discovery for application configuration since it's not in the same repository as application code.
- Managing many repositories can be time-consuming.
Use separate repositories to insulate changes
When scaling up a mono-repository, different permissions are required on different folders. Because of this, separating repositories allows for security boundaries between security, platform, and application configuration. It's also a good idea to separate production and non-production repositories.
Although managing many repositories can be a large task by itself, insulating different types of configuration in different repositories has the following benefits:
- In an organization with platform, security, and application teams, the cadence of changes and permissions are different.
- Permissions remain at the repository level.
CODEOWNERSfiles let organizations limit write permission while still allowing read permission. - Config Sync supports multiple syncs per namespace which can achieve a similar effect as sourcing files from multiple repositories.
Pin package versions
Whether using Helm or Git, you should pin the configuration package version to something that doesn't accidentally get moved forward without an explicit rollout.
Although this adds additional checks to your rollouts when a shared configuration is updated, it reduces the risk of shared updates having a larger-than-intended impact.
Use Workload Identity Federation for GKE
You can enable Workload Identity Federation for GKE on GKE clusters, which allows Kubernetes workloads to access Google services in a secure and manageable way.
Although some non-Google Cloud services, such as GitHub and GitLab, don't support Workload Identity Federation for GKE, you should try to use Workload Identity Federation for GKE whenever possible due to the increased security and reduction in complexity of managing secrets and passwords.