Garantizar la confiabilidad y la calidad de tu configuración de alta disponibilidad de Patroni es fundamental para mantener las operaciones continuas de la base de datos y minimizar el tiempo de inactividad. En esta página, se proporciona una guía integral para probar tu clúster de Patroni, que abarca varias situaciones de falla, la coherencia de la replicación y los mecanismos de conmutación por error.
Prueba tu configuración de Patroni
Conéctate a cualquiera de tus instancias de patroni (
alloydb-patroni1,alloydb-patroni2oalloydb-patroni3) y navega a la carpeta de patroni de AlloyDB Omni.cd /alloydb/
Inspecciona los registros de Patroni.
docker compose logs alloydbomni-patroni
Las últimas entradas deben reflejar información sobre el nodo de Patroni. Deberías ver un resultado similar al siguiente.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lockConéctate a cualquier instancia que ejecute Linux y que tenga conectividad de red con tu instancia principal de Patroni,
alloydb-patroni1, y obtén información sobre la instancia. Es posible que debas instalar la herramientajqejecutandosudo apt-get install jq -y.curl -s http://alloydb-patroni1:8008/patroni | jq .
Deberías ver algo similar a lo siguiente:
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
Llamar extremo de API de HTTP de Patroni en un nodo de Patroni expone varios detalles sobre el estado y la configuración de esa instancia de PostgreSQL en particular que administra Patroni, incluida la información del estado del clúster, la línea de tiempo, la información de WAL y las verificaciones de estado que indican si los nodos y el clúster están en funcionamiento correctamente.
Cómo probar la configuración de HAProxy
En una máquina con un navegador y conectividad de red a tu nodo de HAProxy, ve a la siguiente dirección:
http://haproxy:7000. Como alternativa, puedes usar la dirección IP externa de la instancia de HAProxy en lugar de su nombre de host.Deberías ver algo similar a la siguiente captura de pantalla.
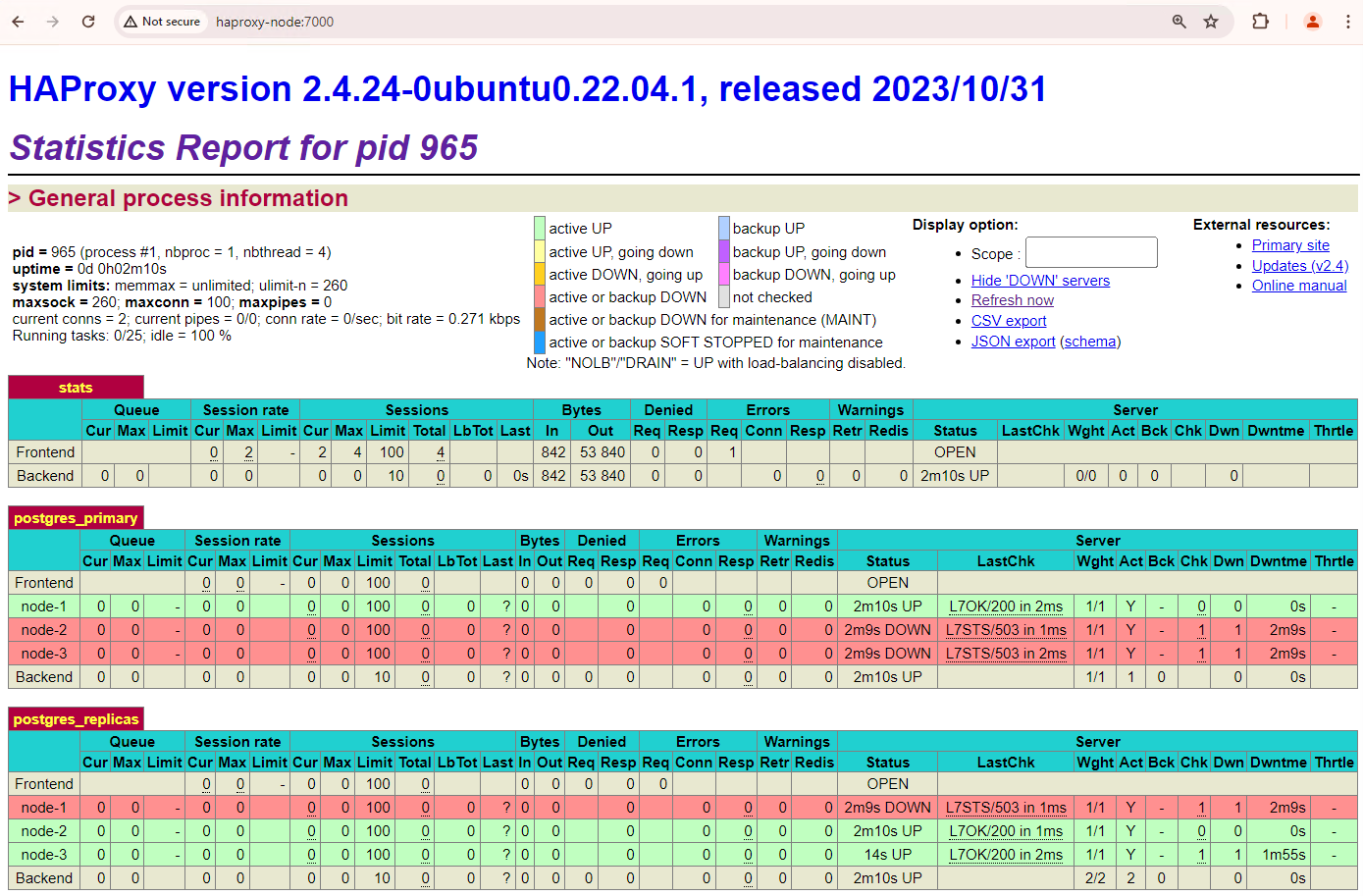
Figura 1. Página de estado de HAProxy que muestra el estado y la latencia de los nodos de Patroni.
En el panel de HAProxy, puedes ver el estado y la latencia de tu nodo principal de Patroni,
patroni1, y de las dos réplicas,patroni2ypatroni3.Puedes realizar consultas para verificar las estadísticas de replicación en tu clúster. Desde un cliente como pgAdmin, conéctate a tu servidor de base de datos principal a través de HAProxy y ejecuta la siguiente consulta.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Deberías ver algo similar al siguiente diagrama, que muestra que
patroni2ypatroni3se transmiten desdepatroni1.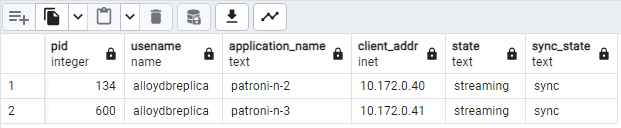
Figura 2: Resultado de pg_stat_replication que muestra el estado de replicación de los nodos de Patroni.
Prueba la conmutación por error automática
En esta sección, en tu clúster de tres nodos, simularemos una interrupción en el nodo principal deteniendo el contenedor de Patroni adjunto en ejecución. Puedes detener el servicio de Patroni en el servidor principal para simular una interrupción o aplicar algunas reglas de firewall para detener la comunicación con ese nodo.
En la instancia principal de Patroni, navega a la carpeta de Patroni de AlloyDB Omni.
cd /alloydb/
Detén el contenedor.
docker compose down
Deberías ver un resultado similar al siguiente. Esto debería validar que el contenedor y la red se detuvieron.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedActualiza el panel de HAProxy y observa cómo se produce la conmutación por error.
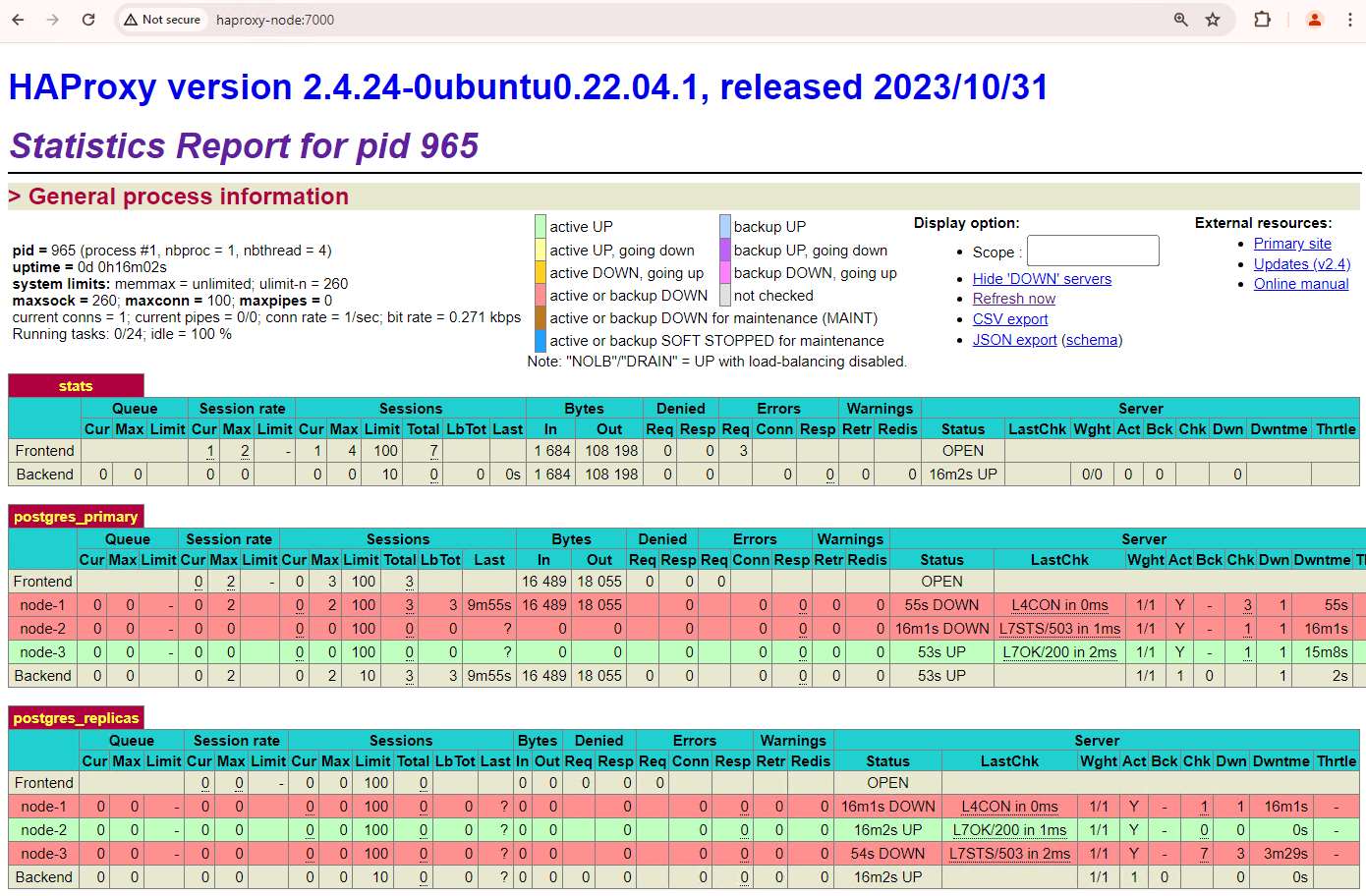
Figura 3. Panel de HAProxy que muestra la conmutación por error del nodo principal al nodo en espera.
La instancia
patroni3se convirtió en la nueva instancia principal, ypatroni2es la única réplica restante. La instancia principal anterior,patroni1, está inactiva y las verificaciones de estado fallan.Patroni realiza y administra la conmutación por error a través de una combinación de supervisión, consenso y organización automatizada. En cuanto el nodo principal no renueva su concesión dentro de un tiempo de espera especificado o si informa una falla, los demás nodos del clúster reconocen esta condición a través del sistema de consenso. Los nodos restantes se coordinan para seleccionar la réplica más adecuada para promoverla como la nueva principal. Una vez que se selecciona una réplica candidata, Patroni promueve este nodo a principal aplicando los cambios necesarios, como actualizar la configuración de PostgreSQL y volver a reproducir los registros de WAL pendientes. Luego, el nuevo nodo principal actualiza el sistema de consenso con su estado, y las demás réplicas se reconfiguran para seguir al nuevo nodo principal, lo que incluye cambiar su fuente de replicación y, posiblemente, ponerse al día con las transacciones nuevas. HAProxy detecta el nuevo servidor principal y redirecciona las conexiones del cliente según corresponda, lo que garantiza una interrupción mínima.
Desde un cliente como pgAdmin, conéctate a tu servidor de bases de datos a través de HAProxy y verifica las estadísticas de replicación en tu clúster después de la conmutación por error.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Deberías ver algo similar al siguiente diagrama, que muestra que solo
patroni2se está transmitiendo ahora.
Figura 4: Resultado de pg_stat_replication que muestra el estado de replicación de los nodos de Patroni después de la conmutación por error.
Tu clúster de tres nodos puede sobrevivir a una interrupción más. Si detienes el nodo principal actual,
patroni3, se producirá otra conmutación por error.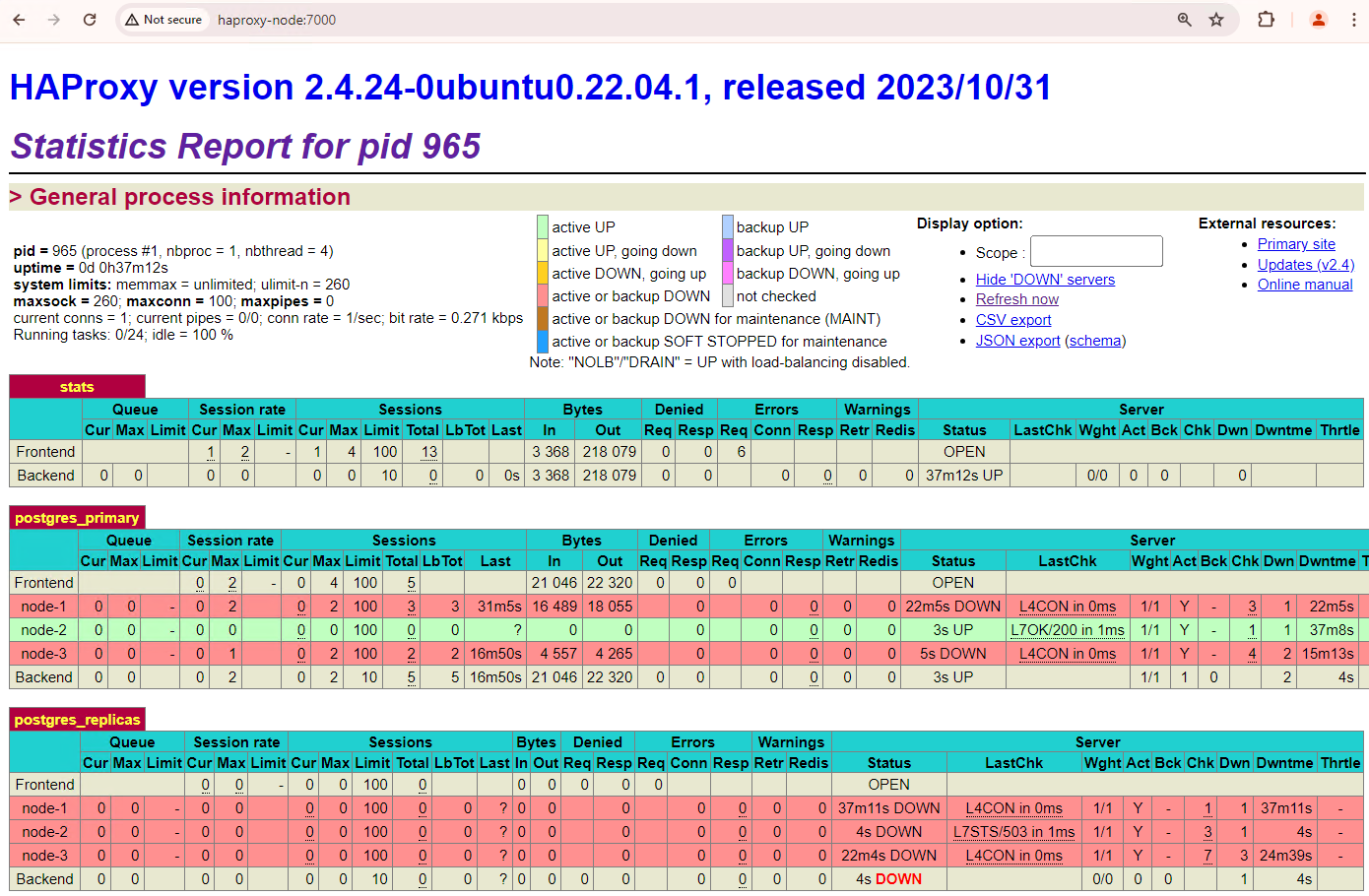
Figura 5. Panel de HAProxy que muestra la conmutación por error del nodo principal,
patroni3, al nodo de reserva,patroni2.
Consideraciones sobre el resguardo
La reversión es el proceso de restablecimiento del nodo fuente anterior luego de que se produce una conmutación por error. En general, no se recomienda la conmutación por error automática en un clúster de bases de datos de alta disponibilidad debido a varios problemas críticos, como la recuperación incompleta, el riesgo de situaciones de cerebro dividido y el retraso en la replicación.
En tu clúster de Patroni, si activas los dos nodos con los que simulaste una interrupción, se volverán a unir al clúster como réplicas en espera.
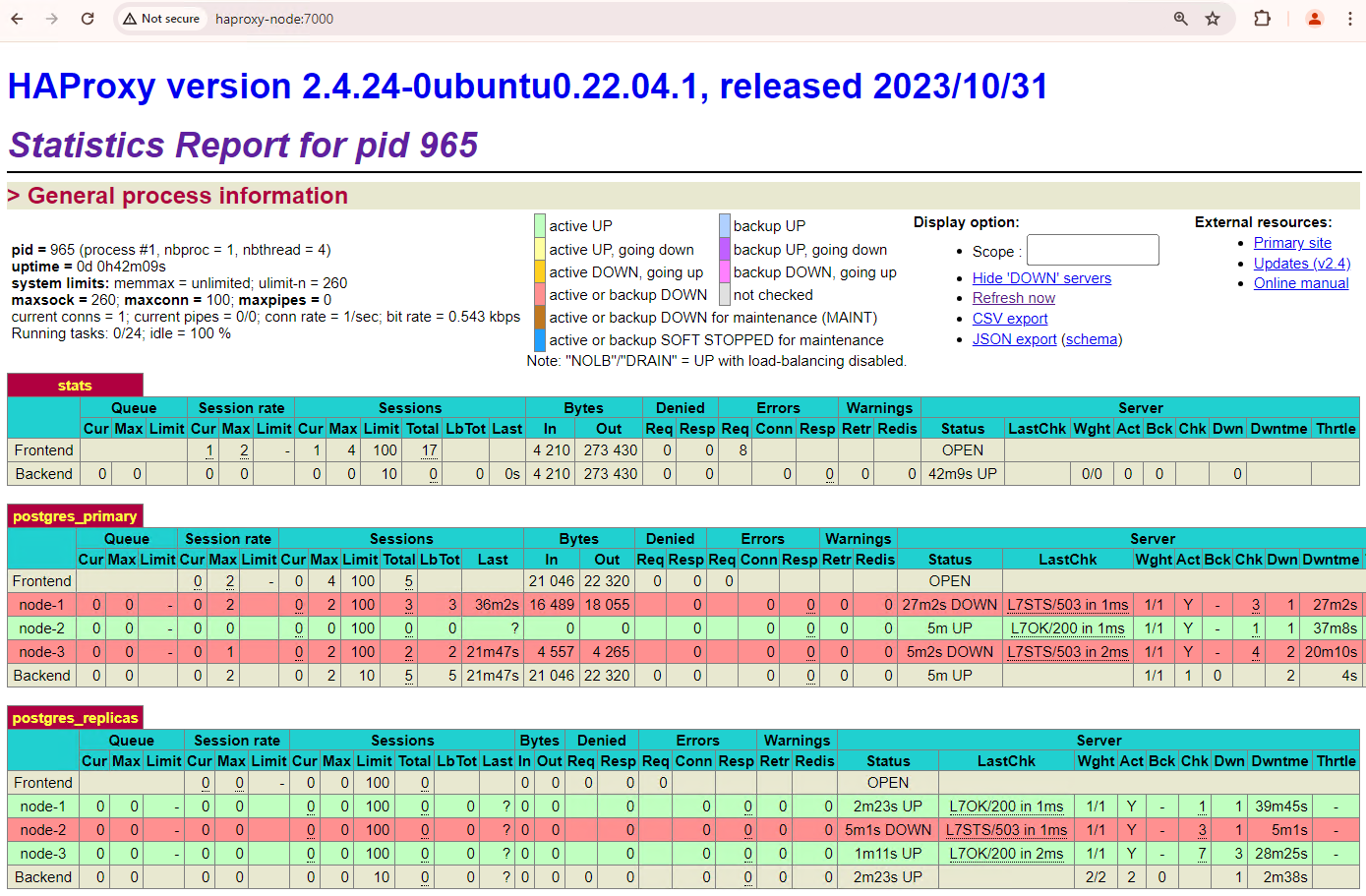
Figura 6. Panel de HAProxy que muestra el restablecimiento de patroni1 y patroni3 como nodos de reserva.
Ahora patroni1 y patroni3 se replican desde la instancia principal actual patroni2.

Figura 7: Resultado de pg_stat_replication que muestra el estado de replicación de los nodos de Patroni después de la conmutación por recuperación.
Si quieres volver manualmente a tu servidor principal inicial, puedes hacerlo con la interfaz de línea de comandos patronictl. Si optas por la conmutación por error manual, puedes garantizar un proceso de recuperación más confiable, coherente y verificado a fondo, lo que mantiene la integridad y la disponibilidad de tus sistemas de bases de datos.