Quando rappresenti graficamente il throughput nel tempo man mano che un'altra variabile viene modificata, in genere il throughput aumenta fino a raggiungere un punto di esaurimento delle risorse.
La figura seguente mostra un tipico grafico di scalabilità del throughput. Man mano che il numero di client aumenta, il workload e il throughput aumentano fino a esaurire tutte le risorse.
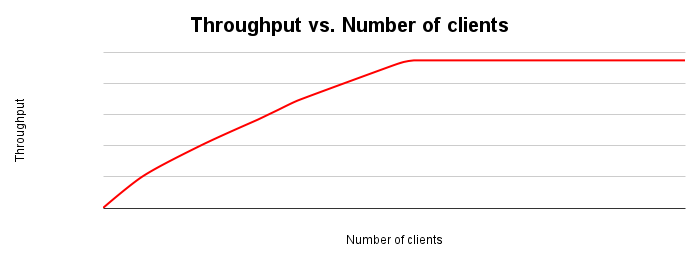
Idealmente, quando raddoppi il carico sul sistema, anche il throughput dovrebbe raddoppiare. In pratica, ci sarà una contesa delle risorse che porterà a un aumento inferiore del throughput. A un certo punto, l'esaurimento o la contesa delle risorse farà sì che il throughput si appiattisca o addirittura diminuisca. Se stai eseguendo l'ottimizzazione per il throughput, questo è un punto chiave da identificare, in quanto indirizza i tuoi sforzi verso l'ottimizzazione del sistema di applicazioni o database per migliorare il throughput.
I motivi tipici per cui il throughput si stabilizza o diminuisce includono:
- Esaurimento delle risorse CPU sul server del database
- Esaurimento delle risorse della CPU sul client, in modo che al server di database non venga inviato altro lavoro
- Conflitto di blocco del database
- Tempo di attesa I/O quando i dati superano le dimensioni del pool di buffer Postgres
- Tempo di attesa I/O dovuto all'utilizzo del motore di archiviazione
- Colli di bottiglia della larghezza di banda della rete che restituiscono i dati al client
Latenza e velocità effettiva sono inversamente proporzionali. All'aumentare della latenza, il throughput diminuisce. Intuitivamente, ha senso. Quando inizia a materializzarsi un collo di bottiglia, le operazioni iniziano a richiedere più tempo e il sistema esegue meno operazioni al secondo.
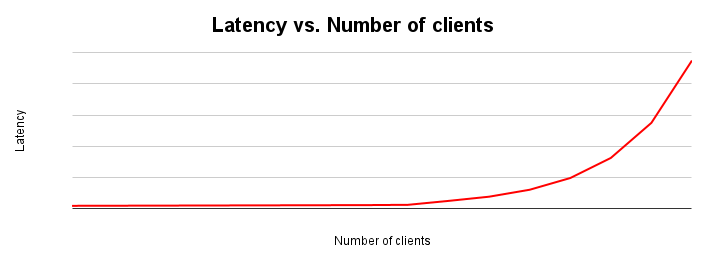
Il grafico di scalabilità della latenza mostra come cambia la latenza all'aumentare del carico su un sistema. La latenza rimane relativamente costante finché non si verifica un attrito dovuto alla contesa delle risorse. Il punto di flesso di questa curva corrisponde generalmente all'appiattimento della curva di throughput nel grafico di scalabilità del throughput.
Un altro modo utile per valutare la latenza è come istogramma. In questa rappresentazione, raggruppiamo le latenze in bucket e contiamo quante richieste rientrano in ciascun bucket.
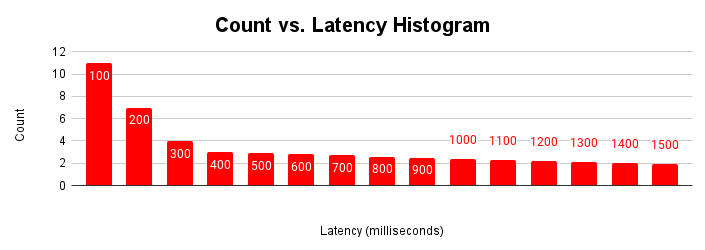
Questo istogramma della latenza mostra che la maggior parte delle richieste è inferiore a 100 millisecondi e le latenze superiori a 100 millisecondi. Comprendere la causa delle richieste con una coda di latenze più lunghe può contribuire a spiegare le variazioni del rendimento dell'applicazione osservate. Le cause della lunga coda di latenze aumentate corrispondono alle latenze aumentate osservate nel tipico grafico di scalabilità della latenza e all'appiattimento del grafico del throughput.
L'istogramma della latenza è più utile quando in un'applicazione sono presenti più modalità. Una modalità è un insieme normale di condizioni operative. Ad esempio, la maggior parte delle volte l'applicazione accede a pagine che si trovano nella cache del buffer. Nella maggior parte dei casi, l'applicazione aggiorna le righe esistenti, ma potrebbero esserci più modalità. A volte, l'applicazione recupera pagine dallo spazio di archiviazione, inserisce nuove righe o si verifica un conflitto di blocco.
Quando un'applicazione rileva nel tempo queste diverse modalità di funzionamento, l'istogramma della latenza mostra queste modalità multiple.

Questa figura mostra un tipico istogramma bimodale in cui la maggior parte delle richieste viene gestita in meno di 100 millisecondi, ma esiste un altro cluster di richieste che richiedono 401-500 millisecondi. Comprendere la causa di questa seconda modalità può contribuire a migliorare le prestazioni della tua applicazione. Possono esserci anche più di due modalità.
La seconda modalità potrebbe essere dovuta a normali operazioni del database, a un'infrastruttura e una topologia eterogenee o al comportamento dell'applicazione. Ecco alcuni esempi da prendere in considerazione:
- La maggior parte degli accessi ai dati proviene dal buffer pool PostgreSQL, ma alcuni provengono dallo spazio di archiviazione
- Differenze nelle latenze di rete per alcuni client al server di database
- Logica dell'applicazione che esegue operazioni diverse a seconda dell'input o dell'ora del giorno
- Conflitto blocco sporadico
- Picchi di attività del client