Il est essentiel de garantir la fiabilité et la qualité de votre configuration Patroni à haute disponibilité pour maintenir des opérations de base de données continues et minimiser les temps d'arrêt. Cette page fournit un guide complet pour tester votre cluster Patroni, couvrant divers scénarios de défaillance, la cohérence de la réplication et les mécanismes de basculement.
Tester votre configuration Patroni
Connectez-vous à l'une de vos instances patroni (
alloydb-patroni1,alloydb-patroni2oualloydb-patroni3), puis accédez au dossier AlloyDB Omni patroni.cd /alloydb/
Inspectez les journaux Patroni.
docker compose logs alloydbomni-patroni
Les dernières entrées doivent refléter des informations sur le nœud Patroni. Un résultat semblable aux lignes suivantes doit s'afficher.
alloydbomni-patroni | 2024-06-12 15:10:29,020 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:39,010 INFO: no action. I am (patroni1), the leader with the lock alloydbomni-patroni | 2024-06-12 15:10:49,007 INFO: no action. I am (patroni1), the leader with the lockConnectez-vous à n'importe quelle instance Linux disposant d'une connectivité réseau à votre instance Patroni principale,
alloydb-patroni1, et obtenez des informations sur l'instance. Vous devrez peut-être installer l'outiljqen exécutantsudo apt-get install jq -y.curl -s http://alloydb-patroni1:8008/patroni | jq .
Un résultat semblable à celui-ci devrait s'afficher.
{ "state": "running", "postmaster_start_time": "2024-05-16 14:12:30.031673+00:00", "role": "master", "server_version": 150005, "xlog": { "location": 83886408 }, "timeline": 1, "replication": [ { "usename": "alloydbreplica", "application_name": "patroni2", "client_addr": "10.172.0.40", "state": "streaming", "sync_state": "async", "sync_priority": 0 }, { "usename": "alloydbreplica", "application_name": "patroni3", "client_addr": "10.172.0.41", "state": "streaming", "sync_state": "async", "sync_priority": 0 } ], "dcs_last_seen": 1715870011, "database_system_identifier": "7369600155531440151", "patroni": { "version": "3.3.0", "scope": "my-patroni-cluster", "name": "patroni1" } }
L'appel du point de terminaison de l'API HTTP Patroni sur un nœud Patroni expose divers détails sur l'état et la configuration de cette instance PostgreSQL particulière gérée par Patroni, y compris des informations sur l'état du cluster, la chronologie, les informations WAL et les vérifications de l'état indiquant si les nœuds et le cluster sont opérationnels.
Tester votre configuration HAProxy
Sur une machine disposant d'un navigateur et d'une connectivité réseau à votre nœud HAProxy, accédez à l'adresse suivante :
http://haproxy:7000. Vous pouvez également utiliser l'adresse IP externe de l'instance HAProxy au lieu de son nom d'hôte.Vous devriez voir quelque chose de semblable à la capture d'écran suivante.
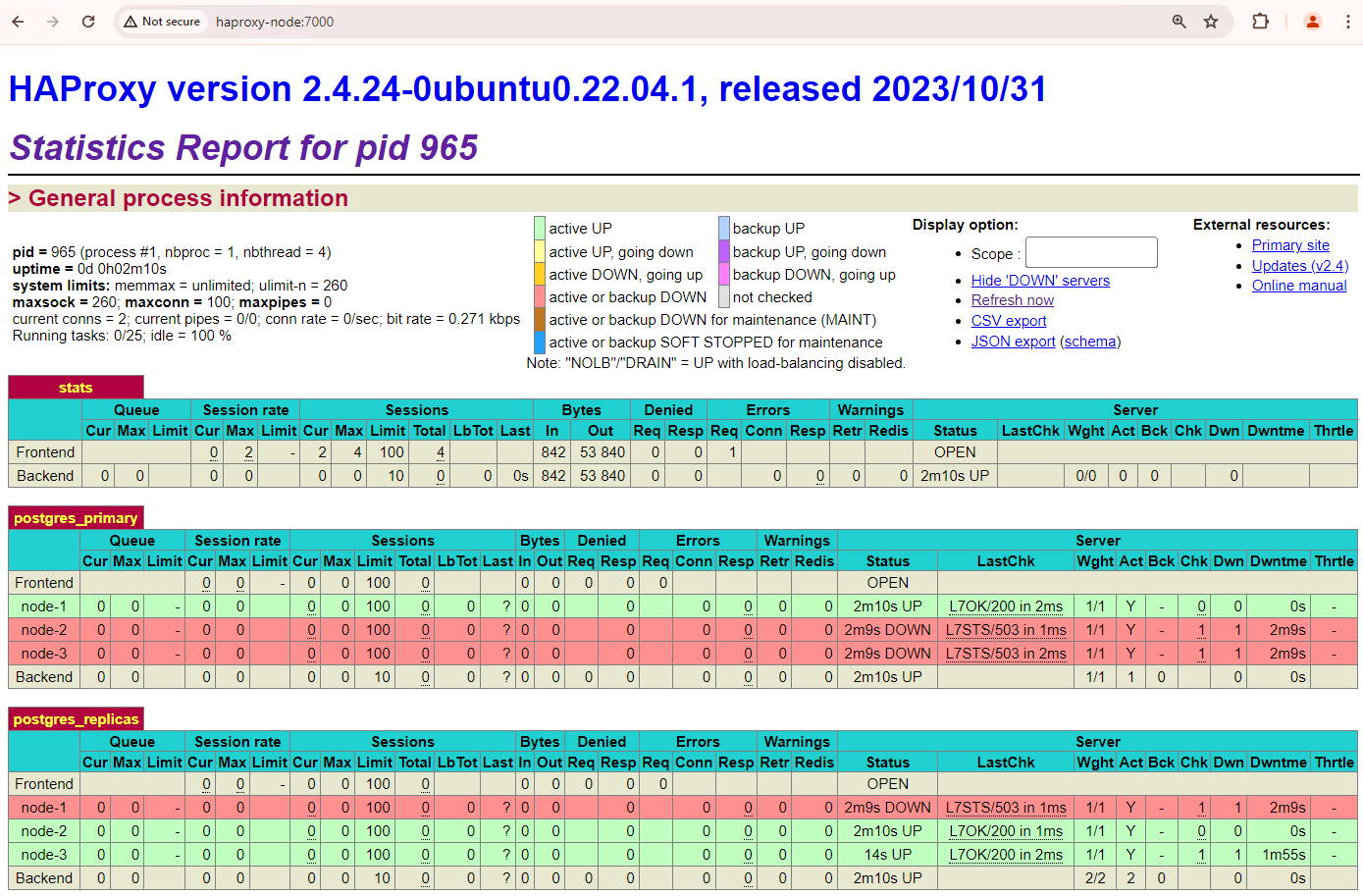
Figure 1 : Page d'état HAProxy affichant l'état de fonctionnement et la latence des nœuds Patroni.
Dans le tableau de bord HAProxy, vous pouvez voir l'état de fonctionnement et la latence de votre nœud Patroni principal,
patroni1, et des deux répliques,patroni2etpatroni3.Vous pouvez exécuter des requêtes pour vérifier les statistiques de réplication dans votre cluster. À partir d'un client tel que pgAdmin, connectez-vous à votre serveur de base de données principal via HAProxy et exécutez la requête suivante.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Vous devriez voir un diagramme semblable à celui ci-dessous, indiquant que
patroni2etpatroni3sont diffusés en streaming depuispatroni1.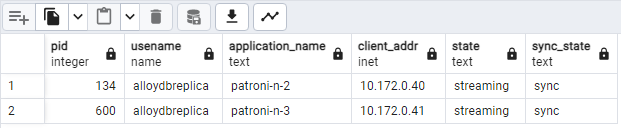
Figure 2 : Sortie pg_stat_replication montrant l'état de la réplication des nœuds Patroni.
Tester le basculement automatique
Dans cette section, nous allons simuler une panne sur le nœud principal de votre cluster à trois nœuds en arrêtant le conteneur Patroni en cours d'exécution qui y est associé. Vous pouvez arrêter le service Patroni sur le nœud principal pour simuler une panne ou appliquer des règles de pare-feu pour arrêter la communication avec ce nœud.
Sur l'instance Patroni principale, accédez au dossier AlloyDB Omni Patroni.
cd /alloydb/
Arrêtez le conteneur.
docker compose down
Le résultat obtenu devrait ressembler à ce qui suit. Cela devrait confirmer que le conteneur et le réseau ont été arrêtés.
[+] Running 2/2 ✔ Container alloydb-patroni Removed ✔ Network alloydbomni-patroni_default RemovedActualisez le tableau de bord HAProxy et observez le basculement.
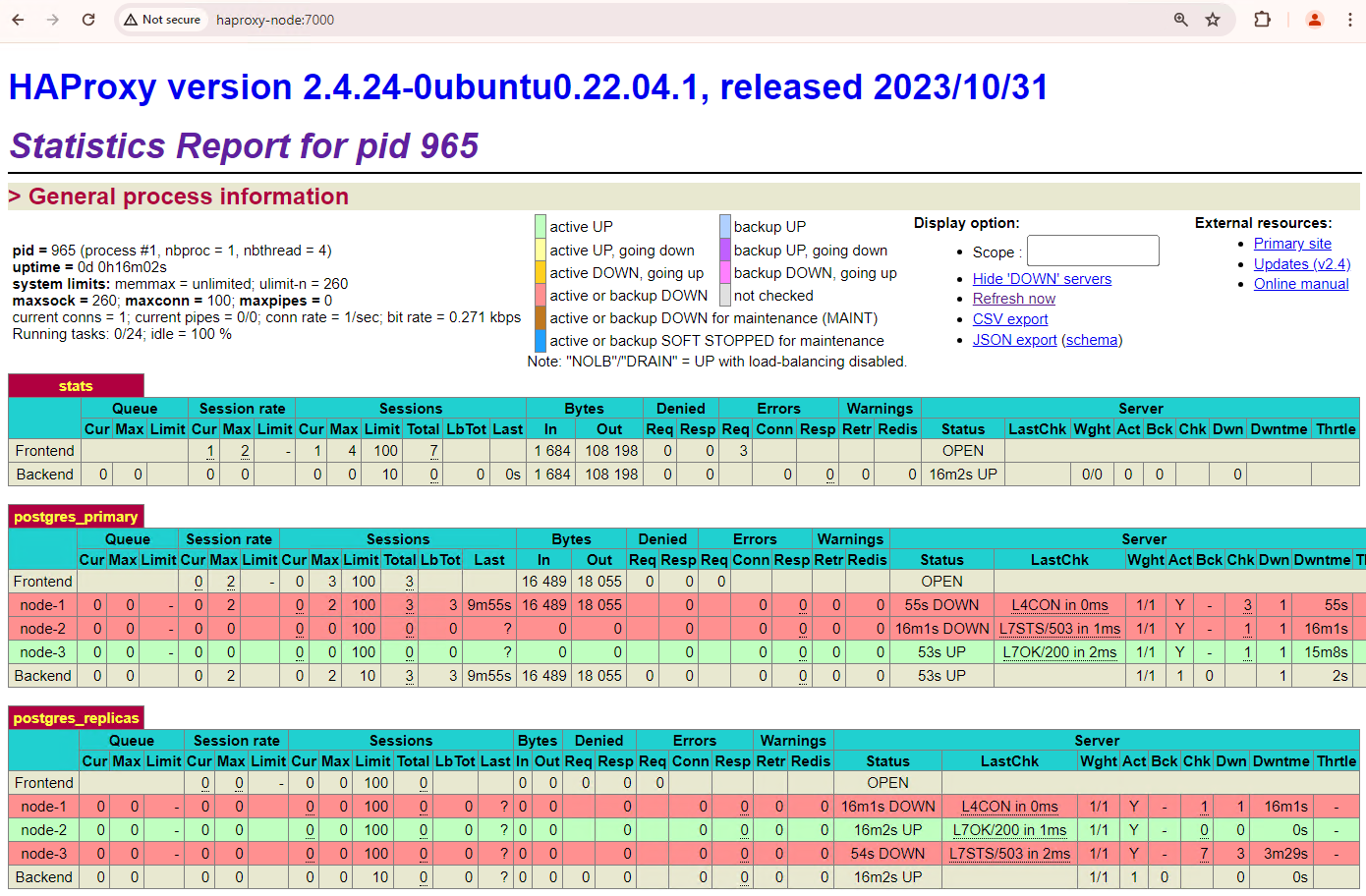
Figure 3. Tableau de bord HAProxy montrant le basculement du nœud principal vers le nœud de secours.
L'instance
patroni3est devenue la nouvelle instance principale, etpatroni2est la seule instance répliquée restante. L'ancienne VM principale,patroni1, est hors service et les vérifications de l'état échouent pour celle-ci.Patroni effectue et gère le basculement grâce à une combinaison de surveillance, de consensus et d'orchestration automatisée. Dès que le nœud principal ne parvient pas à renouveler son bail dans un délai spécifié ou s'il signale un échec, les autres nœuds du cluster reconnaissent cette condition via le système de consensus. Les nœuds restants se coordonnent pour sélectionner le réplica le plus approprié à promouvoir en tant que nouveau nœud principal. Une fois une instance répliquée candidate sélectionnée, Patroni la promeut en instance principale en appliquant les modifications nécessaires, telles que la mise à jour de la configuration PostgreSQL et la relecture des enregistrements WAL en attente. Le nouveau nœud principal met ensuite à jour le système de consensus avec son état, et les autres répliques se reconfigurent pour suivre le nouveau nœud principal, y compris en changeant de source de réplication et en rattrapant potentiellement les nouvelles transactions. HAProxy détecte le nouveau nœud principal et redirige les connexions client en conséquence, ce qui minimise les perturbations.
À partir d'un client tel que pgAdmin, connectez-vous à votre serveur de base de données via HAProxy et vérifiez les statistiques de réplication dans votre cluster après le basculement.
SELECT pid, usename, application_name, client_addr, state, sync_state FROM pg_stat_replication;Vous devriez voir un diagramme semblable à celui ci-dessous, indiquant que seul
patroni2est en streaming.
Figure 4 : Sortie pg_stat_replication montrant l'état de la réplication des nœuds Patroni après le basculement.
Votre cluster à trois nœuds peut survivre à une autre panne. Si vous arrêtez le nœud principal actuel,
patroni3, un autre basculement se produit.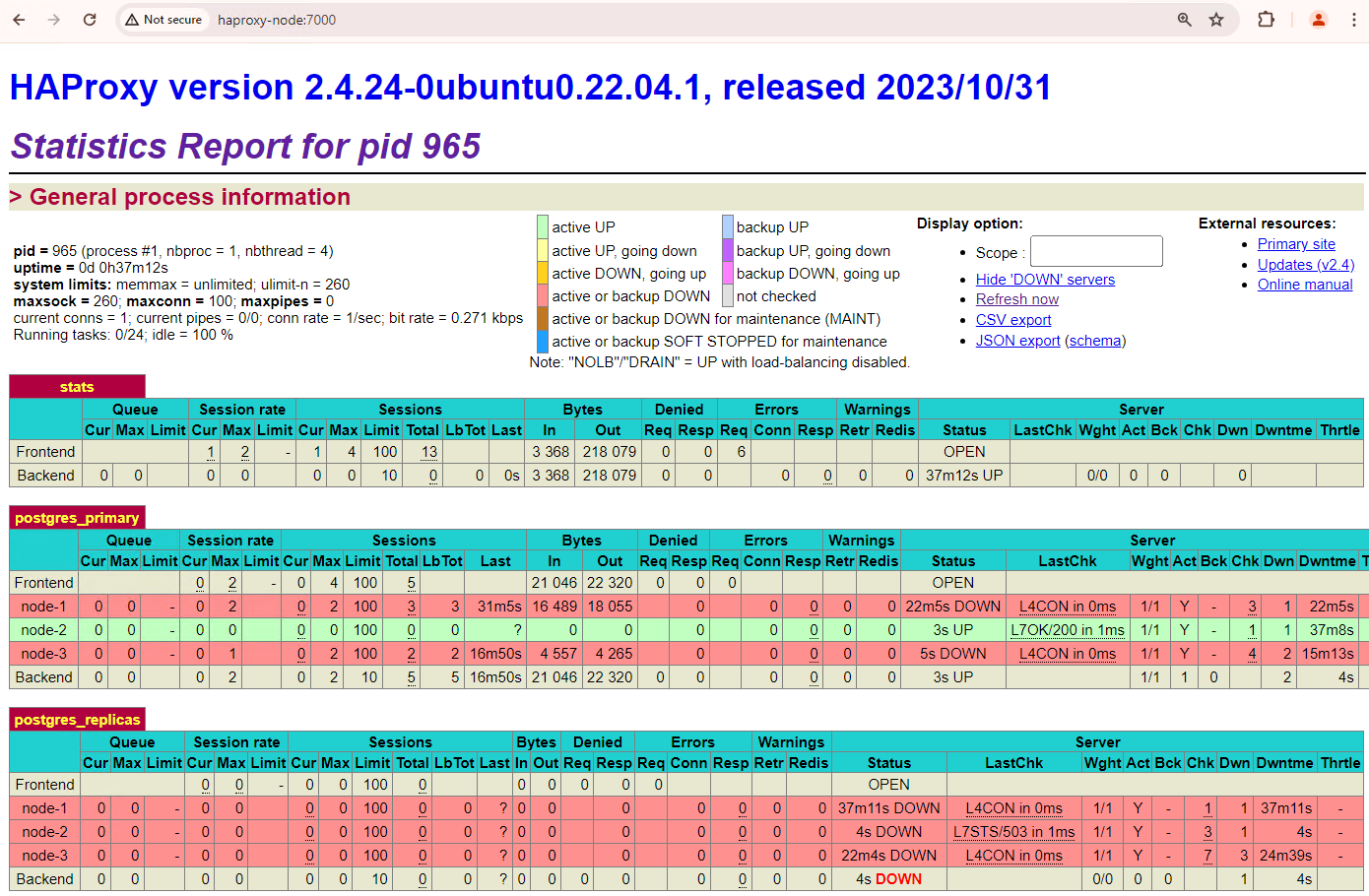
Figure 5. Tableau de bord HAProxy montrant le basculement du nœud principal,
patroni3, vers le nœud de secours,patroni2.
Considérations concernant le remplacement
Le repli est le processus de rétablissement de l'ancien nœud source après un basculement. Le basculement automatique n'est généralement pas recommandé dans un cluster de base de données à haute disponibilité en raison de plusieurs problèmes critiques, tels que la récupération incomplète, le risque de scénarios de split-brain et le décalage de réplication.
Dans votre cluster Patroni, si vous réactivez les deux nœuds avec lesquels vous avez simulé une panne, ils rejoindront le cluster en tant qu'instances répliquées de secours.
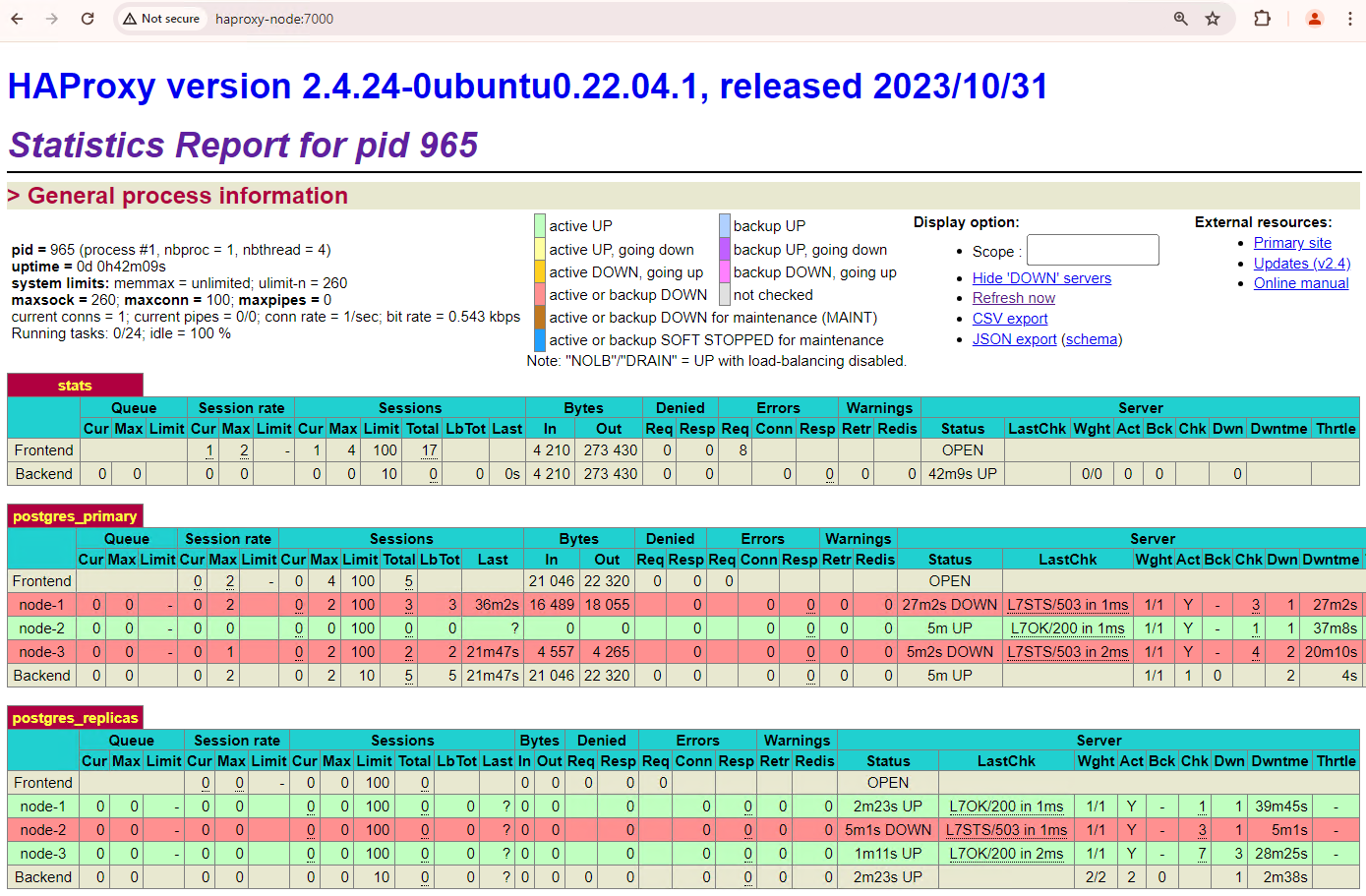
Figure 6. Tableau de bord HAProxy montrant la restauration de patroni1 et patroni3 en tant que nœuds de secours.
patroni1 et patroni3 sont désormais répliquées à partir de l'instance principale actuelle patroni2.

Figure 7 : Sortie pg_stat_replication montrant l'état de la réplication des nœuds Patroni après le basculement.
Si vous souhaitez revenir manuellement à votre instance principale initiale, vous pouvez le faire à l'aide de l'interface de ligne de commande patronictl. En optant pour le basculement manuel, vous pouvez garantir un processus de récupération plus fiable, cohérent et minutieusement vérifié, tout en préservant l'intégrité et la disponibilité de vos systèmes de base de données.